Использование интерфейса WorkFlow
9 минутное чтение
ModusETL развивается в концепции «low-code», что подразумевает возможность настраивать ETL-операции в визуальных интерфейсах и без необходимости написания кода. Появившийся в релизе ETL v. 1.5 (май 2021) интерфейс WorkFlow — является альтернативой настройке шагов сценария в виде таблицы, для которого возможно только последовательное выполнение шагов; в WorkFlow появилась возможность параллельного выполнения нескольких веток сценария, что обеспечивает большую производительность.
Интерфейс WorkFlow дает возможность проектировать сценарии обработки данных
- размещая шаги (обработчики) на холсте, связывая их друг с другом для передачи между шагами данных или потока управления;
- настраивая для шага правила обработки данных в визуальном мастере — сейчас возможно использовать десятки готовых мастеров (шаблонов) для выборки, группировки, соединения, объединения, дополнения, отбора данных и других ETL-операций.
- настраивая в нужных точках выполнения сценария сбор и сохранение статистики для профилирования и проверки качества данных (шаблон «Просмотр»).
При запуске сценария на исполнение в интерфейсе отображается ход выполнения процесса, сохраняются логи и статистика по данным.
Описание интерфейса WorkFlow
Для открытия интерфейса в разделе сценария обработки данных выбрать кнопку «WorkFlow» как на рисунке ниже:

Для настройки процесса обработки данных необходимо разместить шаги на холсте, выбирая шаблоны обработчика из списка шаблонов (см. рисунок ниже, 1 и 2) и связывая шаги друг с другом.
Список с кратким описанием назначения и основных функций шаблонов / мастеров обработки данных см. этот раздел.
Шаги связываются стрелкой, которая означает передачу управления иили передачу данных (см. рисунок ниже, 3).
Для шага возможно изменить «Наименование» в текстовом поле над шагом (см. рисунок ниже, 4).
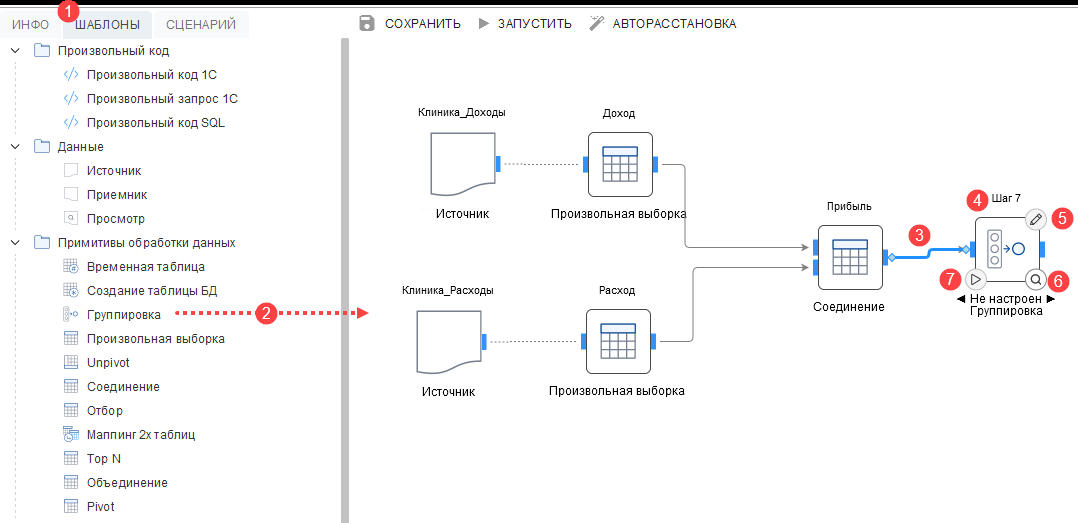
Для настройки параметров шага — необходимо запустить мастер, воспользовавшись контроллом «Редактировать шаг» (см. рисунок выше, 5). Настройка с использованием шаблонов мастеров описана в этом разделе:

Как правило, в мастере настройки имеются закладки «Выбора источника», «Настройки полей запроса» и просмотра «Результата». На закладке «Результат» отображается текст запроса и результат запроса:

Элемент управления «Просмотр» (см. второй рисунок, 6) предназначен для просмотра образца (сэмпла) данных (см. рисунок выше). Если при открытии отобразится сообщение «Нет данных», то для выполнения сценария до текущего шага и получения сэмпла данных необходимо нажать «Выполнить до текущего цикла». Также возможно изменить количество отображаемых строк, установив параметр «Размер выборки».

Элемент управления для шага «Выполнить до текущего шага» (см. второй рисунок, 7) предназначен для запуска выполнения сценария до текущего шага — при выполнении отображается прогресс и лог выполнения:

В сценарии возможно настраивать в нужных точках сбор и сохранение статистики для профилирования и качества данных, используя специальный шаблон «Просмотр».
После формирования диаграммы WorkFlow с шагами обработки данных и связями шагов, настройки точек сбора статистики по данным, источниками и приемниками данных — необходимо сохранить сценарий обработки данных и запустить на выполнение, воспользовавшись кнопками в верхней части WorkFlow «Сохранить», «Запустить», «Авторасстановка».
После запуска в интерфейсе (см. рисунок ниже, «S»), будет отображаться ход выполнения на прогресс-баре (см. рисунок ниже, «P»), выполненные шаги выделяются зелеными рамками и в таблице «Лог выполнения» выводится инфо о времени и длительности выполнения шагов (см. рисунок ниже, «L»):

После завершения выполнения сценария возможно анализировать «Лог выполнения», для возможной оптимизации наиболее длительных шагов. В случае ошибки — описание ошибки будет выведено в колонке «Ошибка лога выполнения».
Список шаблонов шагов сценария
Для реализации концепции «low-code» — возможности настраивать ETL-операции пользователем без специальной подготовки, в удобных визуальных интерфейсах и без написания кода в Modus ETL доступны мастера визуальной настройки обработки данных — шаблоны шагов сценария. Ниже — список используемых шаблонов. Этот список будет пополнятся и расширятся в новых релизах продукта:
| Шаблон шага сценария | Описание функционала | Есть в Work Flow? |
|---|---|---|
| Произвольный код | ||
| Произвольный код SQL | Для ввода кода на языке SQL | Да |
| Произвольный код 1С | Для ввода кода на языке 1С | Да |
| Произвольный запрос 1С | Для ввода на языке 1С-запросов | |
| Данные | ||
| Источник | Присоединяется ко входу шага-обработчика данных. Предназначен для выбора таблицы-источника. Нажав на элемент управления возможно просмотреть сэмпл данных | Да |
| Приемник | Присоединяется к выходу обработчика данных. Предназначен для формирования таблицы с набором полей из входящего потока и сохранения данных в таблицу. Элемент управления — для получения и просмотра сэмпла данных из таблицы. Если установить признак, то приемник может быть источником для последующих шагов сценария |
Да |
| Просмотр | Используется для сохранения и просмотра статистики по данным | Да |
| Очистка таблицы | Производит очистку таблицы из базы данных, которую надо указать в поле «Приемник данных» | Да |
| Перенос данных | Предназначен для переноса данных между двумя различными базами внутри одного сценария | Да |
| Примитивы обработки данных | Да | |
| Произвольная выборка данных | Для настройки выборки данных из одной или нескольких таблиц с функциями выбора полей, соединения таблиц, отбора и сортировки данных. Возможно применять функции преобразования к полям или добавлять новые поля, используя интерфейс «Конструктор выражений». На основании полей с типом «дата» и «дата и время» возможно добавлять поля с частями даты (год, квартал, месяц, номер недели, день недели и т.д.), воспользоавшись интерфейсом «Части даты» |
Да |
| Группировка | Группирует данные, аналогично SQL-функции GROUP BY. Настраиваются: поля группировки и поля агрегатов с выбором функций: SUM, MIN, MAX, AVG, COUNT. |
Да |
| Соединение (дополнение данных) |
Дополняет данные основной таблицы/потока полями из одной или нескольких таблиц. Соединяет таблицы, аналогично SQL-функции JOIN. Настраиваются условия соединения таблиц и поля из таблиц с возможностью применения функций |
Да |
| Объединение | Объединяет данные таблиц аналогично SQL-функции UNION. Настраиваются соответствия полей основной и добавляемых таблиц |
Да |
| Отбор | Для отбора/фильтрации данных по условиям. Настраиваются: «Поле» / «Условие» / «Значения». Набор условий зависит от типа поля (строка, число, дата) и соответствует SQL-операторам: =, ≠, >, <, ≥, ≤, LIKE, IN(список), not IN(список) NULL, IS NOT NULL |
Да |
| Маппинг полей двух таблиц | Копирует данные из одной таблицы в другую по настроенным правилам соответсвия (маппинга) полей | Да |
| Маппинг полей двух таблиц с предварительным удалением | Работает аналогично шаблону «Маппинг 2х таблиц», с одним отличием. На вкладке «Связь полей» задаются поля (ключ) для поиска. Если какие-то записи совпадут по ключу поиска, то они в таблице-приёмнике будут заменены соответствующими записями из таблицы-источника | Да |
| Unpivot | Транспонирует выбранные столбцы таблицы При этом заголовки выбранных столбцов переносятся в значения строк, а их значения — в один столбец. |
Да |
| Pivot | Для формирования сводной таблицы настраиваются: - поля группировки — значения выводятся в строках; - поля для транспонирования строк в столбцы; - поля значений с функцией агрегации |
Да |
| Создание таблицы БД | Используется для создания таблиц в базе данных хранилища | Да |
| Топ N | Для выбора строк по условиям. Настраивается: - размер выборки — N строк, - поля и направление сортировки. SQL эквивалент: top N / limit N с условием Order by |
Да |
| Разделение строки | разделяет строки на массив подстрок, используя указанный разделитель | Да |
| НСИ — дополнение данных | ||
| Справочник НСИ | Эталонный справочник модуля НСИ для дополнения или обновления первичных данных | Да |
| Маппинг НСИ | Таблица соответствия между сущностями: справочниками, категориями / группами | Да |
| НСИ. Дополнение из эталонного справочника | Дополнение таблицы значениями из эталонного справочника НСИ. Настраиваются: связь таблиц — поля и условия; поле(я) для дополнения таблицы | Да |
| НСИ. Обновление из эталонного справочника | Замена значений в таблице значениями из эталонного справочника НСИ. Настраиваются: - связь таблиц — поля и условия; - поле(я) для обновления таблицы |
Да |
| НСИ. Дополнение из маппинга | Дополнение таблицы значениями из маппинга НСИ. Настраиваются связь таблиц — поля и условия связывания, а также поле(я) для дополнения исходной таблицы | Да |
| Python | ||
| Кластеризация | Кластеризация используется для группировки объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри группы (кластера) должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры. Возможно выбирать алгоритмы «KMean», «DbScan». |
Да |
| Линейная регрессия | Регрессия используется для решения задач «Data Mining», таких, как прогнозирование и численное предсказание. Требуется предварительное обучение на обучающей выборке. Возможно выбрать из пяти линейных («Linear regression», «Ridge», «Lasso», «Elastic Net», «Lars») и двух древовидных («Decision tree», «Random forest regressor») моделей | Да |
| Сервисные операции | ||
| Настройка замены пустых значений | Заменяет значения по образцу | Да |
| Выгрузка таблицы в файл | Настраиваются параметры для выгрузки данных в файл | Да |
| Настройка индексов таблицы | Создает индексы в таблице для ускорения поиска | Да |
| Мастер настройки расчета фасетов таблицы | Расчет статистических данных таблицы (фасетов), котрые используется для быстрого знакомства с данными и профилирования данных | Да |
| Очистка хранилища от бэкапов | Удаления архивных копий таблиц, которые копируются и сохраняются при обновлении данных в целевой таблице «Составом выгрузки» в режиме «Скопировать и добавить». Такие архивные таблицы имеют общий признак: суффикс «_ГГГГММДД_Время» в наименовании | Да |
| Копирование бинарного файла в «BASE64» | Файлы, подходящие под заданную маску, кодируются по алгоритму «BASE64» и сохраняются в текстовый выходной «CSV»-файл | Да |
| Настройка удаления пробелов/спецсимволов из полей таблицы | Очистка строковых полей от «плохих» символов | Да |
| Запуск принудительного обновления куба | Настраиваются параметры интеграция с сервером «Полиматики» для обновления кубов по расписанию | Да |
| Сложный сценарий | ||
| Вставка результата запроса в таблицу | Записывает в выходную таблицу | Да |
| Смена имен таблиц | Изменяет имя таблицы по образцу | Да |
| Создание временной таблицы | Создает временную таблицу | Да |
| Верификация данных | ||
| Начало процесса верификации | Осуществляется запись в специальный журнал процессов о начале процесса верификации | Нет |
| Заменить значение | Настраивается замена значения при обнаружении ошибки | Нет |
| Записать в лог ошибок | Настраивается запись в лог ошибок описания ошибки при ее обнаружении | Нет |
| Завершение процесса верификации | Осуществляется запись в специальный журнал процессов об окончании процесса верификации, количестве обработанных строк и количестве выявленных ошибок | Нет |
| Мэппинг данных с заменой | Осуществляет проверку и замену значений поля таблицы в соответствии с предварительно настроенным справочником эталонных значений | Нет |
| Мэппинг предварительный анализ | Осуществляет проверку в соответствии с предварительно настроенным справочником эталонных значений | Нет |
| Проверка символьной строки | Осуществляется проверка значений поля на соответствие предопределенным правилам, например, проверка корректности СНИЛС, ИНН и т.п. | Нет |
| Проверка на NULL | Осуществляется поиск незаполненных (NULL) значений в поле таблицы для символьных, числовых или календарных типов данных. | Нет |
| Мэппинг данных с дополнением | Осуществляет проверку и дополнение таблицы новым полем в соответствии с предварительно настроенным справочником эталонных значений | Нет |
Перенос данных
Типы шаблонов и рекомендации по использованию шаблонов
Шаблоны из группы «Произвольный код» используются для ввода кода на языке 1С / SQL.
Шаблоны из группы «Данные» предназначены не для обработки данных, а для настройки источников, приемников и правил сбора статистики по данным.
Шаблоны из группы «Примитивы обработки данных» используются для настройки выборок из таблиц, обработки-трансформации данных определенным способом.
Шаблоны из группы «НСИ — дополнение данных» используются для операций стандартизации и категоризации данных с использованием объектов НСИ — эталонных справочников и маппингов.
Шаблоны из группы «Python» используются для решения задач DataMining сегментации объектов, прогнозирования, предсказания и т.д., с использованием моделей продвинутой аналитики и библиотек Python.
Шаблоны из группы «Сервисные операции» используются для выгрузки таблиц в файлы, настройки индексов, замены значений по определенным правилам, очистки хранилища от архивных копий таблиц, кодирования файла в «BASE64» и других сервисных операций.
Шаблоны из группы «Верификация данных» используются для настройки логирования процесса верификации (проверки на установленные условия), настройки правил верификации и обработки выявленных ошибок.
Шаблоны из группы «Сложные сценарий» используются для оптимизации работы с таблицами.