Решение предназначено для управления процессами ETL и Data Quality Management.
Позволяет собирать данные из множества источников, обеспечивает процессы верификации, нормализации и последующего формирования единого корпоративного хранилища данных.
Это многостраничный печатный вид этого раздела. Нажмите что бы печатать.
Modus ETL
- 1: Начало работы
- 2: Администратору
- 2.1: Установка и настройка Modus ETL
- 2.2: Установка конфигурации Modus ETL
- 2.3: Установка СЛК
- 2.4: Агент ETL
- 2.5: Настройка взаимодействия Агента ETL и информационной базы ETL
- 2.6: Установка адаптера ETL
- 2.7: Обновление Modus ETL
- 2.8: Создание базы данных хранилища
- 2.9: Подключение ClickHouse
- 2.10: Разграничение доступа в разрезе проектов
- 2.11: Запуск пакетов, составов, сценариев используя API
- 2.12: Технические настройки для подготовки к работе
- 2.13: Контрольные метрики
- 3: Сбор данных
- 3.1: Настройка соединения с БД
- 3.2: Источники данных
- 3.2.1: Настройка источников данных
- 3.2.2: Регистрация набора источников
- 3.3: Загрузка данных из файлов
- 3.3.1: Загрузка файлов csv и xlsx
- 3.3.2: Загрузка JSON файлов
- 3.3.2.1: Конструктор правил разбора JSON
- 3.4: Настройка выгрузки данных
- 3.4.1: Настройка правил выгрузки данных
- 3.4.1.1: Настройка служебных полей
- 3.4.1.2: Настройка правила вида «Запрос»
- 3.4.1.3: Настройка правила вида «Произвольный код»
- 3.4.1.4: Настройка правила вида «Загрузка из файла»
- 3.4.1.5: Настройка правила вида «Схема источника (СКД)» для 1С-источника
- 3.4.2: Настройка состава выгрузки данных
- 3.4.3: Механизм извлечения данных с использованием обработок plug-in’ов (модулей получения данных)
- 3.4.4: Настройка инкрементальной загрузки из 1С
- 3.4.5: Загрузка данных в таблицу из файлов JSON
- 3.4.6: Загрузка данных из Битрикс24
- 3.4.7: Получение данных из web сервисов
- 3.5: Настройка процесса выгрузки данных
- 3.5.1: Однократный запуск получения данных (запуск «вручную»)
- 3.5.2: Автоматический (регулярный) сбор данных
- 3.5.3: Логирование выгрузки данных
- 3.6: Загрузка данных из временных таблиц
- 3.7: Мастер интеграции
- 3.7.1: Общие настройки Мастера интеграции
- 3.7.2: Настройка мастера интеграции для Битрикс24
- 3.7.2.1: Описание полей Битрикс24
- 3.8: Выполнение внешних обработок в базах-источниках 1С:Предприятие через адаптер
- 4: Обработка данных
- 4.1: Сценарии обработки данных
- 4.2: Использование интерфейса WorkFlow
- 4.3: Шаблоны примитивов обработки данных
- 4.4: Шаблоны выполнения произвольного кода
- 4.5: Шаблоны базовых операций с данными
- 4.6: Шаг переноса данных в другую БД
- 4.7: Использование параметров выполнения шага
- 4.8: Шаги сценария (старый интерфейс)
- 4.9: Дополнительные возможности
- 5: Пакеты обработки данных
- 5.1: Настройка пакетов обработки данных
- 5.2: Включение пакета в расписание
- 5.3: Настройка рассылки оповещений о выполнении пакета
- 5.4: Лог выполнения пакетов обработки данных
- 6: Модуль НСИ
- 7: Дополнительные возможности
- 8: Новое в версии
1 - Начало работы
Программный продукт: «Модус:Управление корпоративным хранилищем данных (ETL)» (сокращенное название — Modus ETL), разработан на платформе 1С с использованием «1С:Библиотека стандартных подсистем 8» (далее — БСП) и является 1С-конфигурацией, позволяющей выгружать данные из разных источников (учетных систем, баз данных, web-сервисов, файлов), обрабатывать полученные данные по предварительно настроенным правилам (сценариям) и сохранять результаты в базу данных хранилища.
Конфигурация-1С программного продуктапредназначена для автоматизации ETL-процессов (от англ. «Extract, Transform, Load» — «извлечение, преобразование, загрузка») извлечения данных из различных источников, подготовки и загрузки данных в хранилище.
Программный продуктможет являться частью программного комплекса, включающей помимо Modus ETL, хранилище данных (DWH) и программный продукт для визуализации данных Модус:Аналитический портал (см. рисунок ниже):

Случаи использования:
- получение больших массивов данных из разнообразных источников;
- объединение/консолидация данных из разных источников;
- обработка данных — очистки, дополнения, стандартизации, агрегации, расчета показателей и т.д. — по разнообразным правилам;
- обновление данных по расписанию.
Как это работает:
- настраиваем доступ к источникам данных;
- настраиваем правила получения данных из каждого типа источников;
- проверяем доступность источников;
- получаем данные, пользуясь интерфейсом «Выгрузка в отчет» (ручной режим);
- проверяем, что данные получены без ошибок;
- анализируем полученные данные и определяем необходимость и алгоритмы обработки данных для конкретной задачи;
- настраиваем правила (сценарии) обработки данных;
- настраиваем ETL-пакет, включающий стадии получения и обработки данных;
- настраиваем расписание ETL-пакета;
- контролируем получение данных по расписанию.
1.1 - Варианты использования Modus ETL
Для ModusETL существуют базовые и продвинутые способы получения, загрузки и обработки данных.
Базовый вариант — использует встроенные в приложение ModusETL механизмы:
- для сбора данных — стандартный механизм, когда полученные из источника данные сначала размещаются во временных массивах и структурах, а затем сохраняются в базу данных хранилища целиком.
- для интеграции с 1С-источниками — «Внешнее-соединение» (COM-коннектор).
Продвинутый варинат (более производительный и масштабируемый) предполагает, использование вместе с ModusETL специально разработанных дополнительных модулей:
- «Агент ETL» (разработан на языке Golang) для многопоточной обработки данных. При работе под OC Linux использование «Агента ETL» обязательно. Возможно использование с одним ETL нескольких агентов, размещенных как-правило на разных серверах, что обеспечивает горизонтальную масштабируемость получения-обработки данных;
- «Адаптер ETL для 1С» — http-сервис, для получения данных из 1С-приложений.
Этот компонент устанавливается в 1С-источники как отдельная подсистема в конфигурацию базы-источника или как расширение конфигурации.
Сравнение и особенности вариантов, а также названия инструкций по установке-настройке дополнительного ПО представлены в таблице ниже.
Сравнение вариантов получения данных и интеграции с 1С-источниками
| Функционал | Базовый вариант | Продвинутый вариант с дополнительным ПО (Инструкция) |
|---|---|---|
| Сбор и обработка данных | Стандартные механизмы приложения: - Получаемые из источников данные сохраняются во временных массивах-и-структурах и, затем записываются в БД хранилища целиком |
Агент ETL Многопоточное получание данных с управлением порциями и очередями. (+) производительность (+) масштабируемость (+) работа под ОС Linux Modus ETL. Руководство по установке Агента |
| Коннектор для 1С-источников | Внешнее соединение/COM-коннектор: (-) Ограничение: 1С-источник и ETL должны иметь одинаковые версии 1С-платформы/ СОМ-коннектора |
Адаптер ETL для 1С -http-сервис, встраиваемый в 1С-источник (+) нативные способы получения данных из 1С Модус ETL. Руководство по установке и настройке. [Приложение П1. Инструкция по встраиванию “Адаптера ETL-1С” в 1С базу-источник](../3.5 Инструкция по встраиванию Адаптера ETL-1C в 1С базу-источник/index.md) |
Схема компонентов аналитической системы с использованием Агента ETL и Адаптера ETL-1С представлена на рисунке ниже:

1.2 - Навигация в ETL
При открытии программы отображается интерфейс «Начальная страница». На эту страницу выведены ссылки для настройки основных функций системы, ссылки сгруппированы в смысловые блоки:

Основные:
- «Мастер сбора данных» — функции подключения и правил получения данных из сторонних источников;
- «Источники данных» — функции подключения и настройки источников получения данных и баз данных-приемников;
- «Сбор данных» — функции настройки правил получения данных;
- «Обработка» — функции по настройке трансформации данных в хранилище;
- «Пакеты» — функции настройки ETL-пакетов, за пускающихся по расписанию и объединяющих процессы сбора, трансформации и загрузки данных в хранилище.
Дополнительные:
- «Справочники» — выведены ссылки на наиболее часто использующиеся справочники;
- «Сервис» — выведены ссылки на основные сервисные функции;
- «Отчеты» — выведены ссылки на наиболее часто использующиеся отчеты.
Также на начальной странице расположены средства для мониторинга процессов получения данных.
В блоке «Контроль работы» отображаются последние запуски пакетов на получение и обработку данных, их текущее состояние и наличие ошибок:
- Синий — пакет находится в процессе работы:

- Зеленый — пакет закончил работу и отработал без ошибок:

- Красный — работа пакета прервана из-за ошибки:

Для работающих или завершенных с ошибкой ETL-пакетов возможно по ссылке перейти в лог «Выполнение пакета» и далее последовательно в логи этапов и шагов выполнения пакета, что позволяет быстро выявить текущий этап (для работающего пакета) или шаг, выполнение которого было прервано из-за ошибки (для пакета, выполнение которого было прервано).
В блоке «Текущая очередь» показываются работающие в настоящее время процессы получения данных. Индикатор выполнения (прогресс-бар) показывает процент обработанных источников данных, а строка сообщений выводит количество обработанных источников из общего количества источников:

Разделы ETL
Все функции системы доступны через разделы меню:

Нажимая кнопки разделов, можно включать подменю в разделах и получить доступ ко всем функциональным возможностям системы.
Нажимая на название раздела, можно перейти к его функциям:

Если в системе открыты какие-либо формы, к функциям меню можно перейти через подразделы:

2 - Администратору
2.1 - Установка и настройка Modus ETL
Программный продукт: «Модус: Управление корпоративным хранилищем данных (ETL)» (сокращенно — Modus ETL), возможно использовать в нескольких вариантах.
Для ModusETL существуют базовые и продвинутые способы получения, загрузки и обработки данных.
Базовый вариант — использует встроенные в приложение ModusETL механизмы:
- для сбора данных — стандартный механизм, когда полученные из источника данные сначала размещаются во временных массивах и структурах, а затем сохраняются в базу данных хранилища целиком;
- для интеграции с 1С-источниками — «Внешнее-соединение» (COM-коннектор).
Продвинутый вариант (более производительный и масштабируемый) предполагает, использование вместе с ModusETL специально разработанных дополнительных модулей:
- «Агент ETL» (разработан на языке Golang) для многопоточной обработки данных. При работе под OC Linux использование «Агента ETL» обязательно. Возможно использование с одним ETL нескольких агентов, размещенных как-правило на разных серверах, что обеспечивает горизонтальную масштабируемость получения-обработки данных;
- «Адаптер ETL для 1С» — http-сервис, для получения данных из 1С-приложений. Этот компонент устанавливается в 1С-источники как отдельная подсистема в конфигурацию базы-источника или как расширение конфигурации.
Сравнение и особенности вариантов, а также названия инструкций по установке-настройке дополнительного ПО представлены в следующей таблице.
Сравнение вариантов получения данных и интеграции с 1С-источниками
| Функционал | Базовый вариант | Продвинутый вариант с дополнительным ПО (Инструкция) |
|---|---|---|
| Сбор и обработка данных | Стандартные механизмы приложения: получаемые из источников данные сохраняются во временных массивах и структурах и, затем записываются в БД хранилища целиком |
Агент ETL: Многопоточное получение данных с управлением порциями и очередями. (+) производительность; (+) масштабируемость; (+) работа под ОС Linux. Modus ETL. Руководство по установке Агента |
| Коннектор для 1С-источников | Внешнее соединение/COM-коннектор: (-) Ограничение: 1С-источник и ETL должны иметь одинаковые версии 1С-платформы / СОМ-коннектора |
Адаптер ETL для 1С: (-) http-сервис, встраиваемый в 1С-источник; (+) нативные способы получения данных из 1С Модус ETL. Руководство по установке и настройке Инструкция по встраиванию Адаптера ETL в 1С-базу источника |
Схема компонентов аналитической системы с использованием Агента ETL и Адаптера ETL-1С представлена на рисунке ниже:

Требования к оборудованию и программному обеспечению
Минимальные требования к оборудованию и программному обеспечению см. в таблице ниже.
Минимальные требования к оборудованию и программному обеспечению
| Сервер | Программное обеспечение | Операционная система | Минимальные требования к серверу (Процессор, ОЗУ, ЖД) |
|---|---|---|---|
| Сервер 1С | Платформа 8.3.18 и выше |
см. http://v8.1c.ru/requirements/ |
Процессор: желательно использование многопроцессорных или многоядерных машин ОЗУ: от 4 Гб; ЖД: от 20 Гб |
| Сервер СУБД | SQL Server 2008 и выше или PostgreeSQL 9.1 и выше |
Технические характеристики и операционная система должны оответствовать требованиям используемой версии сервера баз данных. MS SQL Server / PostgreSQL — см. http://v8.1c.ru/requirements/ |
Определение какие мощности и программное обеспечение (СУБД для хранилища, Агенты для ETL балансировщики нагрузки и т.д.) необходимы для обеспечения требуемой функциональности, производительности и отказоустойчивости в каждом конкретном случае требует экспертного анализа и сайзинга, а в комплексных случаях проведения нагрузочных тестов.
ModusETL возможно использовать для получения данных из облачных систем 1С:Fresh. Ниже для такого варианта использования представлены:
- схема Аналитической системы:

- рекомендуемые характеристики оборудования и программного обеспечения — см. в двух таблицах ниже:
«BI для 1C: Fresh» — рекомендуемые характеристики оборудования и программного обеспечения
| Сервер | Компонент | Программное обеспечение | Операционная система | Количество⠀ |
|---|---|---|---|---|
| ETL | 1C | Платформа 8.3.18 и выше | Win/Linux | CPU:12 ядер ОЗУ:16 Гб ЖД: 200 Гб |
| Хранилище данных | СУБД | SQL Server 2008 и выше или PostgreeSQL 9.1 и выше |
Windows / Linux | CPU:16 ядер ОЗУ: 24 Гб; ЖД: 700 Гб |
«BI для 1C: Fresh» — пример для интенсивного использования в варианте
| Описание | Сервер | Программное обеспечение | CPU, ОЗУ, ЖД |
|---|---|---|---|
| Источники данных: - 1C: Fresh (конфигурации БГУ и ЗКГУ); - Парус (СУБД Oracle); - данные по бухгалтерским проводкам, кадрам и заработной плате для 2000 организаций [500+ тыс.сотрудников] |
Сервер 1С | Платформа 8.3.18 | CPU: 16 ядер ОЗУ: 24 Гб ЖД: 200 Гб |
| Сервер СУБД для 1С и хранилища данных |
SQL Server 2012 | CPU: 16 ядер; ОЗУ: 48 Гб; ЖД: 1.5 Тб |
Ограничения для некоторых модулей / функций
При установке и использовании следует учитывать особенности и ограничения для некоторых модулей и функций ModusETL см. в таблице ниже.
Особенности и ограничения для некоторых модулей / функций ModusETL
| Модуль/функция | Версия плат- формы 1С минимальная |
1С-клиент | Ограничения |
|---|---|---|---|
| Модуль НСИ | 8.3.18 | Толстый:+ Тонкий:+ веб:+ |
СУБД для хранения НСИ только PostgreSQL |
| Модуль DataMining (библиотеки Python) | 8.3.18 | Толстый:+ Тонкий:+ веб:+ |
ПО: Python, Flask, IIS |
| Модуль WorkFlow | 8.3.18 | Толстый:+ Тонкий:+ веб:- |
ОС клиента — Windows |
| Сбор данных из 1С, используя Схему источника (СКД) | 8.3.18 | Толстый: весь функционал Тонкий: всё, кроме настройки схемы веб: всё, кроме настройки схемы |
Modus ETL. Руководство пользователя. Ограничения при использовании СКД (п. 6.6.3) |
Особенности настройки 1C для работы ETL
При установке информационной базы Modus ETL на сервере 1С, где эта база развернута, должен быть добавлена параметр DisableUnsafeActionProtection в файл «conf.cfg»
Пример: DisableUnsafeActionProtection=.*"[eE][tT][lL]".*;
С помощью данного параметра предоставляется возможность отключить защиту от опасных действий для определенных информационных баз. Информационные базы определяются набором шаблонов (регулярных выражений), разделяемых символом «;». Если строка соединения с информационной базой будет удовлетворять какому-либо регулярному выражению, перечисленному в данном параметре, для такой информационной базы защита от опасных действий будет отключена.
При редактировании регулярных выражений следует использовать POSIX Basic Regular Expressions (https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_03).
Данный параметр используется тем процессом, который фактически выполняет потенциально опасное действие:
- Загрузка внешних обработок/отчетов или расширений конфигураций ‑ только сервер (процесс rphost).
- Загрузка внешних компонент ‑ клиентское приложение или сервер (процесс rphost).
- Запуск внешнего приложения ‑ клиентское приложение или сервер (процесс rphost).
2.2 - Установка конфигурации Modus ETL
Установка конфигурации выполняется аналогично другим продуктам фирмы 1С. Производится установка необходимых файлов из «дистрибутива» и добавление информационной базы из шаблонов.
Для того чтобы установить конфигурацию, необходимо установить ее шаблон. Для этого нужно запустить файл «setup.exe» (в ОС Linux — «setup»), который расположен в каталоге с дистрибутивом:

Затем необходимо указать, в какой каталог выполнить установку шаблона конфигурации:

Если пользователя не устраивает предложенный по умолчанию путь к каталогу, то он может ввести путь к другому каталогу. Далее программа установки выполнит копирование файлов шаблона конфигурации в указанный каталог.
После того, как программа установки выполнит копирование файлов — нажать кнопку «Готово».
Имеется возможность уменьшить количество шагов мастера установки шаблона конфигурации. Для этого программу setup.exe необходимо запускать с ключом /s. В этом случае будет показан только стартовый диалог с приветствием, и затем будет показан ход копирования файлов с шаблоном конфигурации.
Далее необходимо установить выбранную конфигурацию из шаблона. Для этого необходимо в списке информационных баз добавить новую базу:

Далее выбрать шаблон, из которого разворачивать новую базу. Выбираем «Управление корпоративным хранилищем данных (ETL)»:

В результате, выбранная конфигурация будет установлена.
2.3 - Установка СЛК
СЛК — система лицензирования и защиты конфигураций устанавливается как отдельная система.
Для выполнения установки на ПК с ОС Windows выполните следующие шаги:
- Выполните запуск установочного пакета необходимой версии «licenceserver-{version}.win.exe»:

- На экране начала установки оставить указанными опцию «Загрузить актуальные данные о сериях ключей», и, при необходимости, «Установить пользовательскую документацию»:

- Дождаться окончания процесса установки:

- Завершить процесс установки.
Оставить опцию «Открыть консоль сервера СЛК» установленной:

- В открывшемся окне консоли сервера СЛК выбрать пункт «Установка лицензий»:

- Указать параметры лицензии: код активации, ИНН, КПП организации — владельца лицензии.
Если на ПК, на котором выполняется установка есть выход в Интернет, возможно выполнение активации по кнопке «Установить автоматически через Интернет»:

Иначе возможно выбрать установку через файловый запрос по кнопке «Сформировать файловый запрос». Сформированный текстовый ключ необходимо отправить по электронной почте на адрес katran@1c.ru, либо воспользоваться сайтом Центра лицензирования на компьютере с доступом к Интернету.
Дождаться получения ответа по электронной почте или с сайта Центра лицензирования.
Перейти в пункт «Ответ из Центра Лицензирования». Полученный ответ ввести в поле «Данные ответа»:

Детальную информацию по установке лицензии можно получить из руководства по установке лицензии (см. рисунок выше).
В результате, установка и лицензирование севера СЛК будут завершены.
2.4 - Агент ETL
Агент получения и записи данных реализует сервис по сбору данных из множества различных СУБД и записи их в целевые базы. Управление сервисом осуществляется посредством передачи HTTP-команд на создание/остановку задач. Мониторинг сервиса осуществляется посредством встроенного web-сервиса. Сервис может логировать свои действия как в локальный файл, так и на удаленный сервис логирования.
Для просмотра запущенных заданий также доступна web страница по адресу «http://имя-сервера-с-агентом:порт-агента».
Поддерживаемые базы данных:
- MS SQL;
- Postgres SQL;
- Vertica;
- Oracle DB;
- ClickHouse;
- Greenplum Database;
- Информационные базы 1С (только получение).
Установка Агента ETL
Агент устанавливается в систему Windows или Linux как системный сервис.
Как узнать версию агента:
- запустить исполняемый файл с ключом
-version;- посмотреть на главной странице сервиса в браузере;
- получить в заголовке ответа по пути «/check»;
- проверить в файле логов.
Для Windows
Для установки в систему Windows необходимо запустить от имени администратора файл «setupagentetl.exe», расположенный в поставке с обновлением Modus ETL, выбрать папку установки и нажать «Установить».
После запустится консоль установки начальных параметров агента. Параметры установки можно изменить в файле «settings.json», расположенном в каталоге, куда был установлен Агент ETL. Описание параметров агента приведено ниже.
После установки создается служба, которая логирует свои действия в системный журнал.
Возможна установка новой версии Агента ETL поверх запущенной (служба принудительно останавливается перед обновлением).
После установки автоматически создается служба «AgentETL».
Для Linux систем
Для установки в систему Linux предусмотрена возможность регистрации сервиса в «systemd» (Debian 8+, Ubuntu 16.04+, CentOS 7+). Для этого необходимо выполнить установку пакета для соответствующей системы («deb» или «rpm»):
Для deb-пакета (Ubuntu, Debian) команда:
sudo apt-get install unixodbc && sudo dpkg -i agentetl_*_amd64.deb
Для rpm-пакета (CentOS) команда:
sudo yum install unixODBC && sudo rpm -i agentetl-*-1.x86_64.rpm
При этом, в каталог «/opt/agentetl» будет скопирован файл программы и создан файл настроек «/etc/agentetl/settings.json», который можно отредактировать интерактивно, выполнив в консоли команду:
sudo agentetlcfg
Также будет создан файл демона для «systemd» и запущен сам демон.
По соображениям безопасности, желательно запускать службу от отдельного пользователя.
Для этого нужно:
- создать нового пользователя;
- внести соответствующие изменения в файл настройки «/etc/systemd/system/agentetl.service»;
- установить в качестве владельца нового пользователя для папок и всех вложенных файлов:
- «/opt/agentetl»;
- «/etc/agentetl»;
- «/var/log/agentetl».
После внесения изменений в настройки, необходимо выполнять перезапуск службы:
sudo systemctl daemon-reload
sudo systemctl restart agentetl
Удалить deb-пакет (Ubuntu, Debian) можно командой:
sudo dpkg -r agentetl
Удалить rpm-пакет (CentOS) можно командой:
sudo rpm -e agentetl
Просмотреть статус активности сервиса и последние строки его лог-файла можно командой:
sudo systemctl status agentetl
Файл логов будет размещен в «/var/log/agentetl/».
Настройка параметров Агент ETL
Настройка параметров агента может быть выполнена: при установке и обновлении приложения в консоли, либо редактируя файл «settings.json».
Файл представляет из себя json-файл:
{
"Addr": ":8000",
"TLSCertFile": "",
"TLSKeyfile": "",
"Login": "user",
"Password": "123",
"LogFile": "",
"SaveStatsToFile": "",
"Servers": [],
"ETLLogURL": "",
"ETLLogInterval": 30,
"ETLSuccessURL": "",
"Capacity": 200000,
"Workers": 50,
"Bulksize": 50000,
"Databases": {
"Vertica" : {
"InMemoryResultRowLimit": 200000,
"CopyBlockSizeBytes": 65536
}
}
}
Параметры:
Addr— ip-адрес и порт, в формате «адрес:порт» (слушается интерфейс «адрес») или «:порт» (слушаются все сетевые интерфейсы), которые будет использовать Агент ETL;TLSCertFile— путь к файлу сертификата TLS (*.pem) (если пустой, то TLS не будет использоваться);TLSKeyfile— путь к файлу ключа TLS (*.key);Login— логин для basicauth доступа к API сервиса;Password— пароль для basicauth доступа к API сервиса;LogFile— путь к файлу для записи детального лога;SaveStatsToFile— путь к файлу для записи статистических данных (*.xml);Servers— адреса (и порты) других агентов (для режима балансировщика);ETLLogURL— URL для отправки лога событий ETL в формате:
«http://ИмяПользователя:Пароль@СерверСПубликацией/ИмяБазы/hs/AgentsUpload/Logs»;ETLLogInterval— периодичность отправки лога событий ETL, секунд;ETLSuccessURL— URL для отправки в ETL события успешного завершения задачи в формате:
«http://ИмяПользователя:Пароль@СерверСПубликацией/ИмяБазы/hs/AgentsUpload/ack»;Capacity— макс. количество параллельно обрабатываемых строк;Workers— количество параллельных воркеров;Bulksize— размер «пачки» для вставки при сборе данных (по умолчанию 20 000 строк);Databases— настройки драйверов для соответствующих СУБД:Vertica— настройки для работы с СУБД Vertica:InMemoryResultRowLimit— количество строк, которые будут загружены в память при чтении из СУБД Vertica. Остальные данные записываются в файловый кэш;CopyBlockSizeBytes— размер пакета в байтах, которым отправляются данные для записи в СУБД Vertica
С помощью настроек Capacity и Workers возможно управлять параметрами процесса, для обеспечения адаптивности под разные конфигурации аппаратного обеспечения:
Capacity— регулирует размер буфера, выделяемый в памяти для хранения указанного количества прочитанных строк;Workers— регулирует количество «процессов-воркеров», выполняемых одновременно и передающих считанные строки в базы данных хранилища.
Одни воркер обрабатывает задачу записи для одного источника. Чтение и запись при этом выполняются параллельно.
С помощью настроек TLS-сертификата сервиса поддерживается шифрование https-соединений с сервисом.
Сервис требует basic-аутентификацию подключающегося пользователя. Логин и пароль к нему указываются в соответствующих свойствах файла «settings.json».
После изменения параметров службу Агента необходимо перезапускать
Резервное копирование
Для восстановления работоспособности Агента после каких-то сбоев достаточно иметь дистрибутив Агента ETL и файл с настройками «settings.json». Поэтому для резервирования достаточно выполнять архивацию файла «settings.json».
В системе Linux файл по умолчанию находится в каталоге «/etc/agentetl/».
В системе Windows находится в папке, куда был установлен Агент ETL.
Для восстановления достаточно выполнить следующие действия.
- Установить Агент ETL из дистрибутива.
- Восстановить файл с настройками «settings.json» по нужному пути (Linux — «/etc/agentetl/», Windows — в папку с установленным Агентом).
- Перезапустить службу Агента.
Логирование
Агент логирует свои действия в стандартный поток ошибок консоли. Этот поток сохраняется в системных журналах Windows и Linux.
Дополнительно агент может логировать свои действия в отдельный текстовый файл, для последующего анализа проблем с производительностью и/или работой агента.
Имя файла для сохранения лога указывается в настройке LogFile (см. Настройка агента).
Агент может взаимодействовать с внешним http-сервисом для ведения лога в ETL, если в настройке ETLLogURL указан полный путь к сервису логирования ETL, включая данные об аутентификации.
Формат «ETLLogURL»: «http(s)://user:pass@host:port/path».
Получение и запись данных Агентом под управлением ETL
Общий алгоритм сбора данных Агентом
- ETL передает настройки источника, приемника, текст запроса, параметры и т.д. Агенту.
- Агент запускает процесс по получению данных.
- Агент отправляет информацию в ETL по основным этапам получения данных: время начала/окончания, количество строк, возникшие ошибки и т.п.
- ETL периодически опрашивает Агент о состоянии выполняемых задач.
- По завершению перекачки данных Агент сообщает в ETL об этом.
Возможные этапы при сборе данных
-
«COMСоединение» — общий этап выполнения задачи по «перекачке». Он должен быть самым первым и самым последним. При передачи этого этапа в качестве успешного завершения работы обязательно передается количество строк записанных в приемник.
-
«ПолучениеДанныхИсточника» — этап начинается с момента подключения к источнику и началу выполнения запроса. Завершается моментом окончания чтения данных из источника.
-
«ЗаписьДанныхВоВнешнееХранилище» — этап начинается в момент начала записи данных в приемник и завершается по окончанию. При описании окончания этого этапа передается количество строк, записанных в приемник.
Важные особенности записи данных
Одно задание на перекачку данных является атомарным.
В рамках одного задания может быть выполнено несколько одинаковых запросов на чтение данных с разными параметрами. Однако, все считанные данные далее будут составлять одну транзакцию записи.
Агент учитывает, что в таблицу приемник могут писать и другие задания, поэтому таблица может быть не пустой, а добавление данных должно производится методом добавления, без очистки целевой таблицы.
Для обеспечения атомарности, для каждого типа целевых баз данных используются следующие методы записи.
- MS SQL:
- формируется запрос для массовой вставки
INSERTBULKв целевую таблицу с признаком необходимости установки блокировкиTablock; - данные потоком отправляются на сервер СУБД;
- после завершения чтения и записи всех данных выполняется фиксация общей транзакции;
- сервер MS SQL должен находиться в одном часовом поясе с агентом. В противном случае, для колонок с датами любых типов, кроме
DATETIMEOFFSET, возможно неверное определение часового пояса; - колонки с типом
DATETIMEOFFSETне подвержены проблемам с часовыми поясами, т.к. содержат (и агент транслирует без потерь) информацию о них вне зависимости от часовых поясов сервера и агента; Рекомендуется использовать колонки такого типа для целевых таблиц.
- Postgresql:
- формируется запрос для массовой вставки
COPYв целевую таблицу; - данные потоком отправляются на сервер СУБД;
- после завершения чтения и записи всех данных выполняется фиксация общей транзакции;
- работа с часовыми поясами дат происходит без потери информации о часовом поясе.
- Oracle / ODBC:
- в Oracle или ODBC-базе данных все данные вставляются одной транзакцией, без использования временных таблиц;
- В настройках такой базы достаточно указать
Type = "oracle" или "odbc"и полную строку соединения в параметре Database, остальные параметры (Address,Login,Password) не используются; - для Linux используется пакет «unixODBC», который должен быть установлен отдельно, так же как и необходимый ODBC-драйвер (в том числе и Oracle).
- для Windows достаточно установить и настроить только ODBC драйвер (в том числе и Oracle).
- Vertica:
- формируется запрос для массовой вставки
COPYв целевую таблицу; - данные потоком отправляются на сервер СУБД;
- данные вставляются несколькими запросами
COPY. Количество строк в одном запросе устанавливается в параметреBulksizeфайла «Settings.json»; - после завершения чтения и записи всех данных выполняется фиксация общей транзакции;
- управлять процессом массовой вставки можно используя переменные среды:
VERTICA_ABORT_COPY_ON_ERROR— 0/1. Если установлено значение 0, тогда данные будут вставлены даже в случае ошибок разбора входных данных на стороне СУБД Vertica. Для других значений параметра (в том числе и если параметр отсутствует) будет выполнятся прерывание массовой вставки с записью причины в лог-файл;VERTICA_COPY_AUTO_COMMIT— 0/1. Если установлено значение отличное от 1 (либо вообще не установлено), тогда к запросу будет добавлен параметрNO COMMIT. Данный параметр означает, что после выполнения запроса вставкиCOPYне будет автоматом выполнена фиксации транзакции (COMMITвыполняется один раз после вставки всех данных);VERTICA_TABLE_WITH_REJECTED_DATA— имя таблицы для вставки «отбракованных» данных.
Если используется режимNO COMMIT, то при отсутствии таблицы изVERTICA_TABLE_WITH_REJECTED_DATAона будет создана какLOCAL TEMP.
- ClickHouse:
- вставка в таблицу приемник происходит посредством промежуточной таблицы. Вначале данные накапливаются в промежуточной таблице, затем копируются из промежуточной в целевую (приемник);
- промежуточная таблица может быть как временной (
Temporary), так и обычной. Зависит это от версии СУБД. Начиная с версии 23.3.0.0 используется временная (Temporary) таблица; - промежуточная таблица создается с движком «MergeTree»;
- промежуточная таблица (обычная) удаляется после завершения задачи или в случае ошибки. Возможна ситуация при которой, в результате критических сбоев, промежуточная таблица удалена не будет. Для исключения подобных ситуаций желательно на версиях СУБД ниже 23.3.0.0 периодически запускать скрипт удаления промежуточных таблиц;
- промежуточная таблица получает наименование на основании шаблона имени и отметки времени в наносекундах.
Шаблон: «etl_tmp_$timestamp_nano».
Пример: «etl_tmp_1683294532542734300».
2.5 - Настройка взаимодействия Агента ETL и информационной базы ETL
При использовании для сбора данных Агента ETL, он должен передавать информацию о ходе процесса сбора (логи, количественные данные и т.п.) в базу ETL. Эта передача выполняется асинхронно и для передачи используется http сервис базы ETL.
Для настройки взаимодействия Агента ETL с базой ETL необходимо выполнить следующие действия.
- Опубликовать http сервис «хс_ДанныеОтАгентов» базы ETL на веб сервере.
- Создать пользователя в базе ETL для подключения Агента ETL.
- Настроить файл конфигурации Агента ETL.
- Создать запись об Агенте ETL в базе ETL и проверить подключение.
Публикация базы ETL на веб-сервер
Для взаимодействия необходимо выполнить публикацию http сервиса «хс_ДанныеОтАгентов» на веб-сервере.
Инструкции по настройке веб-серверов и способах публикации доступны в руководстве администратора на сайте Информационно-технологического сопровождения 1C.
См. также Инструкция публикации IIS на инфостарт.
Для публикации сервиса в пользовательском режиме необходимо:
- Зайти конфигуратором в базу ETL, запустив его от Администратора.
- В режиме конфигуратора перейти: «Администрирование» / «Публикация на веб. сервере…».
- В открывшемся окне выбрать вкладку http-сервисы и установить флаг напротив сервиса «хс_ДанныеОтАгентов».
- Сохранить настройки и перезагрузить веб-сервер.
Создание пользователя для подключения к HTTP сервису базы ETL
Пользователь создается следующим образом:
- необходимо создать(если еще не создана) группу доступа для агентов ETL — «Администрирование» / «Настройка пользователей и прав» / «Группа доступа»:

- в группе доступа необходимо выбрать предустановленный профиль «Агент ETL»:

- Создать пользователя через «Администрирование» / «Настройка пользователей и прав» / «Пользователи» с привязкой к группе доступа из п. 1:

Настройка «setting.json»
Следующим этапом является настройка «setting.json».
Расположение:
- в linux: «/etc/agentetl/settings.json»;
- в Windows: «C:\Program Files\AgentETL\settings.json».
Пример файла:
{
...
"Login": "oAzwKP",
"Password": "ysjjRwyG",
...
"ETLLogURL": "http://*ЛОГИН*:*ПАРОЛЬ*@"Адрес_сервера"/"Название базы"/hs/AgentsUpload/Logs",
"ETLLogInterval": 30,
"ETLSuccessURL": "http://*ЛОГИН*:*ПАРОЛЬ*@"Адрес_сервера"/"Название базы"/hs/AgentsUpload/ack",
...
}
Login,Password— параметры, которые используются Агентом ETL при аутентификации внешних сервисов, отправляющих Агенту ETL команды.
Основным отправителем таких команд является база ETL. Поэтому значения из этих параметров, должны быть указаны и в базе ETL, в соответствующих настройках;ETLLogURL— адрес публикации базы ETL, на который будет выполняться отправка логов Агентом ETL;ETLLogInterval— интервал отправки логов Агентом ETL в базу ETL;ETLSuccessURL— адрес публикации базы ETL, по которому выполняется прием квитанции от Агента ETL о завершении сбора данных;ЛОГИНиПАРОЛЬвETLLogURLиETLSuccessURL— логин и пароль пользователя, созданного в основной базе ETL, который будет использоваться Агентом ETL для подключения к публикации.
Настройка базы ETL для взаимодействия с Агентом
Для создания записи в базе ETL об Агенте необходимо сначала включить возможность использования Агентов.
Для этого надо перейти в «Главное» / «Информация» / «Основные настройки» / «Настройки получения данных»:


При активации этого признака, в базе ETL становится доступным использование функциональных возможностей Агентов ETL в части сбора данных, выполнения различных SQL скриптов. Последнее необходимо при разворачивании продукта Modus ETL на операционных системах семейства Linux.
Далее следует добавить Агента ETL с логином и паролем из файла настроек «setting.json» Агента ETL (параметры Login, Password).
Для этого переходим по гиперссылке «Агенты ETL» в основных настройках и нажимаем кнопку «Создать».
Для проверки подключения доступна команда «Проверить доступность»:

2.6 - Установка адаптера ETL
Адаптер ETL предназначен для сбора данных Модус ETL из информационных систем на платформе 1С: Предприятие.
Адаптер поставляется в виде подсистемы в составе файла конфигурации «.cf» или расширения «.cfe».
Требования к информационным базам для установки Адаптера ETL
Для установки из файла конфигурации «.cf»:
- нужна версия платформы 1С:Предприятия не ниже 8.3.5
Для установки из файла расширения «.cfe»:
- нужна версия платформы 1С:Предприятия не ниже 8.3.9;
- требуется режим совместимости конфигурации не ниже 8.3.9.
Установка Адаптера ETL в информационную базу
Добавление Адаптера при помощи расширения из «.cfe» файла (рекомендуется)
-
Открыть информационную базу в режиме конфигуратора.
-
Перейти «Конфигурация» / «Расширения конфигураций».
-
В открывшемся окне нажать кнопку «Добавить». В открывшемся окне добавить установить назначение «Дополнение», нажать «Ок».
-
Выбрать строку с вновь добавленным расширением снять флаг «безопасный режим», перейти в раздел «Конфигурация» / «Сравнить объединить с конфигурацией из файла».
-
В открывшемся окне «Сравнение, объединение» снять все флажки. Для этого достаточно снять флаг с корня конфигурации.
-
В открывшемся окне выбрать поставляемый в папке Адаптера файл «.cfe», нажать кнопку «Выбрать».
-
Перейти: «Действия» / «Установить режим для всех». В открывшемся окне выбрать: режим объединения «из файла», порядок объектов «из файла», по подсистемам файла.
-
Перейти: «Действия» / «Отметить по подсистемам файла», в открывшемся списке выбрать: «ХС_ETL_Адаптер».
-
Проверить, если в конфигурации расширения остался объект «Основная роль», ее желательно удалить из расширения.
-
Нажать «Выполнить». После выполнения объединения сохранить изменения «Конфигурация» / «Сохранить конфигурацию» и обновить конфигурацию базы данных «Конфигурация» / «Обновить конфигурацию базы данных».
Добавить расширение можно из режима 1С предприятия подробнее читать здесь.
При добавлении Адаптера ETL в конфигурацию базы, из «.cf» файла
Такой способ является устаревшим и предназначен для конфигураций не поддерживающих работу расширений. После добавления изменений автоматическое обновление конфигурации станет недоступно.
- Открыть информационную базу в режиме конфигуратора.
- Включить возможность изменения корня конфигурации.
- В режиме конфигуратора перейти в пункт «Конфигурация» / «Поддержка конфигурации» / «Настройка поддержки».
- В открывшемся окне нажать кнопку «Включить возможность изменения конфигурации».
- Выбрать режим «Включить возможность изменения с сохранением поддержки».
- Нажать кнопку «Применить», сохранить изменения конфигурации.
- Загрузить изменения Адаптера ETL.
- В режиме конфигуратор перейти в пункт «Конфигурация» / «Сравнить объединить с конфигурацией из файла».
- В открывшемся окне выбрать поставляемый в папке Адаптера файл «.cf». Нажать кнопку «Выбрать».
- В появившемся окне о предложении постановки на поддержку нажать кнопку «Принять».
- В открывшемся окне «Сравнение, объединение» снять все флажки. Для этого достаточно снять флаг с корня конфигурации.
- Перейти: «Действия» / «Установить режим для всех». В открывшемся окне выбрать: режим объединения «из файла», порядок объектов «из файла», по подсистемам файла.
- Перейти: «Действия» / «Отметить по подсистемам файла», в открывшемся списке выбрать: «ХС_ETL_Адаптер».
- Нажать «Выполнить». После выполнения объединения сохранить изменения «Конфигурация» / «Сохранить конфигурацию» и обновить конфигурацию базы данных «Конфигурация» / «Обновить конфигурацию базы данных».
Публикация информационной базы на веб-сервере
Для работ Адаптера ETL необходимо выполнить публикацию http-сервиса «ХС_ПолучениеДанных» на веб-сервере.
При работе базы в инфраструктуре 1С:Fresh публикация должна быть внутренней для доступа к http-сервису в неразделенном режиме.
Инструкции по настройке веб-серверов и способах публикации доступны в руководстве администратора на сайте Информационно-технологического сопровождения 1C.
См. также Инструкция публикации IIS на инфостарт.
Для публикации сервиса Адаптера необходимо:
- В режиме конфигуратора перейти: «Администрирование» / «Публикация на веб. сервере…»;
- В открывшемся окне выбрать вкладку HTTP сервисы, и установить флаг «Публиковать http сервисы расширений по умолчанию»;
Если данный флаг не устанавливать, то необходимо вручную внести записи о публикуемом http сервисе адаптера в файл default.vrd - Сохранить настройки и перезагрузить веб-сервер.
Создание пользователя Адаптера ETL
Для доступа Модус ETL через HTTP сервис ему необходим специальный пользователь, обладающий правами, поставляемыми в расширении.
Для конфигураций:
- «Управление торговлей» 11;
- «Управление производственным предприятием (ERP)» ред. 2;
- «Бухгалтерия предприятия» ред. 3;
- «Управление нашей фирмой»;
- «Зарплата и управление персоналом» ред. 2;
- других конфигураций использующих «Библиотеку стандартных подсистем» ред. 2.4 и выше,
добавлять пользователя необходимо в режиме 1С Предприятия.
Для этого в режиме 1С Предприятия необходимо:
- Добавить профиль групп доступа с ролью: «Выполнение методов Адаптера ETL» или «Выполнение безопасных методов Адаптера ETL»;
- Добавить группу доступа с созданным профилем;
- Добавить пользователя (например Адаптер ETL), назначить пользователю созданный в п. 1 профиль.
Для конфигураций без «Библиотеки стандартных подсистем» пользователя необходимо добавить в режиме конфигуратора.
Для этого надо в режиме конфигуратора:
- Перейти «Администрирование» / «Пользователи»;
- Нажать «Добавить», в открывшемся меню ввести имя пользователя, пароль и выбрать в списке необходимые роли адаптера;
- Сохранить пользователя.
Добавленного пользователя необходимо указывать при добавлении базы данных в список источников в Модус ETL.
Важно: Для 1С:Fresh — созданный пользователь должен быть неразделенный.
Выбор области, из которой получаются данные происходит после подключения.
Для переключения области пользователю должна быть дополнительно назначена роль «Базовые права БСП»
Настройка прав доступа пользователя для сбора данных
Адаптер ETL предоставляет набор ролей, с помощью которых возможно регулировать доступ к данным и различным функциям Адаптера ETL.
Доступны для использования следующие роли:
-
«Использование методов http-адаптера ETL». При назначении данной роли пользователю, ему будет доступно:
- Получение данных с помощью запросов, СКД, получение метаданных базы источника, выполнение вспомогательных сервисных методов Адаптера ETL
- Выполнение запросов и получение данных будет выполняться в привилегированном режиме. Никаких дополнительных прав добавлять не требуется.
Ответственность за доступ к данным контролируется только разработчиками ETL-процессов. - Доступ к работе с блоком модулей сбора данных не предоставляется.
-
«Использование безопасных методов http-адаптера ETL». При назначении данной роли пользователю, ему будет доступно:
- Получение данных с помощью запросов, СКД, получение метаданных базы источника, выполнение вспомогательных сервисных методов Адаптера ETL
- Выполнение запросов и получение данных будет выполняться в обычном, не привилегированном режиме. Все методы получения данных на стороне адаптера выполняются в обычном, не привилегированном режиме. При отсутствии каких либо прав, сбор данных будет прерван. Подобная настройка позволяет ограничивать доступ к данным на стороне базы данных источника и не зависеть от разработчика ETL процессов.
В настройках базы данных в ETL должен быть установлен признак «Использовать безопасные методы адаптера». - Доступ к работе с блоком модулей сбора данных не предоставляется.
-
«Использование модулей получения данных». Вспомогательная роль, назначается в дополнение к ролям: «Использование методов http-адаптера ETL» или «Использование безопасных методов http-адаптера ETL». При назначении данной роли пользователю, ему будет доступно:
- Работа с блоком модулей сбора данных. При наличии роли «Использование методов http-адаптера ETL» работа обработчиков модулей сбора данных будет выполняться в привилегированном режиме.
Важно: при использовании БСП в базе источнике назначать роль «Полные права» пользователю, который будет подключаться через Адаптер ETL, нельзя. Это связано с тем, что механизмы БСП для «полноправных пользователей» контролируют наличие дополнительных ролей. И «лишние» роли, в том числе из Адаптера ETL, будут автоматически удаляться.
2.7 - Обновление Modus ETL
Порядок обновления конфигурации ETL
Для обновления версии конфигурации следует использовать режим «Обновление конфигураций». Файл конфигурации 1cv8.cf находится в каталоге шаблонов (по умолчанию — подкаталог «tmplts\» каталога перемещаемых служебных файлов профиля пользователя), в подкаталоге «\BIPro\ETL\».
-
Установите 1С:Предприятие 8.
Внимание! Минимальная версия для работы с текущей версией конфигурации 8.3.17.
-
Сделайте резервную копию вашей информационной базы.
Резервную копию можно создать:
- при использовании клиент-серверного варианта 1С:Предприятия 8 средствами СУБД.
- режиме «Конфигуратор» в меню «Администрирование» выберите пункт «Выгрузить информационную базу».
-
Запустите 1С:Предприятие 8 в режиме «Конфигуратор».
-
Откройте конфигурацию, для этого в меню «Конфигурация» выберите пункт «Открыть конфигурацию».
-
Вызовите режим «Обновление конфигураций», для этого в меню «Конфигурация», подменю «Поддержка», выберите пункт «Обновить конфигурацию».
-
В диалоге выбора обновления в качестве источника обновления укажите «Доступные обновления», после чего выберите нужное обновление в соответствующем списке.
-
Если в списке обновлений необходимое обновление отсутствует, то в диалоге выбора обновления в качестве источника обновления укажите «Файл обновления», после чего выберите нужный файл обновления (по умолчанию «1cv8.cfu»).
-
В окне «Обновление конфигураций» нажмите кнопку «OK» для продолжения обновления конфигурации.
-
После завершения будет открыто окно «Конфигурация», содержащее конфигурацию с внесенными изменениями. Выполните сохранение конфигурации.
-
Запустите систему 1С:Предприятие в режиме «Предприятие».
-
Проследите за выполнением процедур отложенной обработки данных, до их завершения данные в базе могут быть некорректными. Работа пользователей в базе возможна с ограничениями.
Внимание! При обновлении конфигурации будут автоматически произведены необходимые изменения в структуре информационной базы. Процесс обновления может занять продолжительное время
Обновление Агента ETL
- Перед обновление Агента ETL необходимо скопировать файл конфигурации «settings.json», расположенный в каталоге с исполняемым файлом.
- Обновление выполняется запуском установочного файла Установка Агента ETL.
- Для ОС Windows при появления окна настройки конфигурации, оставить предлагаемые параметры по умолчанию, не изменяя их.
Обновление Адаптера ETL
- Запустите 1С:Предприятие 8 в режиме «Конфигуратор».
- Откройте конфигурацию, для этого в меню «Конфигурация» выберите пункт «Расширения».
- Выберите расширение «Адаптер ETL».
- В открывшемся окне в меню «Конфигурация» выберите пункт «Загрузить конфигурацию из файла».
- Выберите файл обновления с расширением «.cfe».
- Примите изменения и запустите информационную базу в режиме предприятие.
2.8 - Создание базы данных хранилища
Данные, получаемые из баз-источников, сохраняются в отдельную базу данных — хранилище.
База хранилища должна быть создана администратором баз данных вручную на сервере баз данных (далее — БД). Рекомендуемое название базы хранилища — DWH, но можно задать любое подходящее имя. Подключение базы хранилища к программному продукту: Модус: Управление корпоративным хранилищем данных (ETL) (далее — программный продукт или Modus ETL), происходит во время первого входа в систему во время работы мастера (помощника) первичной настройки». К этому моменту база хранилища должна быть создана.
Мастер (помощник) первичной настройки
В программном продукте создан специальный мастер настройки, который запускается автоматически при первом входе в систему. Этот мастер также можно запустить на любом этапе работы, использовав интерфейс «Главное» / «Сервис» / «Помощник первоначальной настройки»:

Переходя по шагам мастера, пользователь может установить все необходимые для работы настройки. Настройки, не требующие выбора пользователя, устанавливаются автоматически.
Начальная страница «Помощника первоначальной настройки» представлена на рисунке ниже:

Рекомендуется последовательно сделать настройки, распределенные по нескольким разделам, устанавливая отметки на завершенных разделах.
Ниже описаны основные шаги по настройке программного продукта, используя мастер настройки.
Раздел настроек 1. Основные настройки
Пункт меню 1.1. Помощник настройки лицензирования СЛК

Заполнение параметров связи с сервером СЛК:

Установка и обновление лицензий СЛК: для запуска процедур по установке и активации лицензий используется интерфейс, представленный на рисунке ниже:

Консоль сервера лицензирования выводит текущие параметры СЛК и служит для диагностики проблем:

Пункт меню 1.2. Настройки получения данных

Параметры подключения к базам-источникам: введенные логин и пароль будут использоваться для доступа к базам-источникам по умолчанию.
Примечание: при необходимости для каждой базы-источника возможно настроить свои (отличные от параметров по умолчанию) параметры доступа (логин-пароль) в справочнике «Базы данных».

Получение и обработка данных (настройки записи в базу-приемник): надо установить режим записи данных в таблицу-приемник.
Режимы:
- «Добавить» — добавлять данные к уже имеющимся в таблице;
- «Очистить и добавить» — удалить имеющиеся данные и загрузить полученные данные;
- «Скопировать и добавить» — сделать копию имеющихся данных (создается новая таблица с тем же именем и постфиксом-датой_временем операции), очистить имеющиеся данные и загрузить заново.
Пример имени таблицы с поcтфиксом: «tech_20180202_0908».
Установка базы хранилища данных по умолчанию:

Настройки интерфейса «Контроль работы»:

Подключение подсистем:

- «Использовать шаблоны шагов сценария» — включено по умолчанию. Шаблоны позволяют формировать скрипт трансформации данных для шага сценария, используя визуальный интерфейс.
- «Использовать верификацию данных» — для включения механизмов проверки данных на соответствие стандарту, на соответствие эталонным значениям (по умолчанию — выключено).
- «Верификация данных. Настроить имена SQL-таблиц» для журналов процессов и ошибок.
- «Интерфейсные настройки»: следует выбирать только «Пользовательские типы» в поля выбора типов, например, в документах вида «Установить правила выгрузки».
- «Агенты ETL»: включают возможность использовать Агента ETL для получения и записи данных.
- «Обезличивание данных»: использовать обезличивание персональных данных при получнии данных
- «Настройка моделей»: мспользование механизма трансформации таблиц в схему «звезда».
- «Выгрузка и загрузка настроек»: использование пресетов.
Пункт меню 1.3. Ввод параметров баз данных (источников и приемников)
Ввод параметров источников данных. Регистрация наборов источников:

Чтобы добавить 1С-источник, надо выбрать «Способ доступа (тип подключения)»: «Адаптер для 1С» или «COM-Connector».
Для типа подключения с использованием «Адаптера для 1С» настроить:
- тип базы данных: 1C;
- способ доступа: Адаптер для 1С;
- адрес публикации ИС.

Для типа подключения с использованием «COM-Connector» следует заполнить:
- тип базы данных: 1C;
- способ доступа: COM-Connector;
- версию платформы 1C (8.3/8.2/8.1);
- описание;
- имя сервера 1С;
- имя пользователя;
- пароль.

Ограничение для типа подключения COM-Connector: версии платформы 1С для базы-источника и для программного продукта должны быть одинаковые. Поэтому если необходимо подключаться к источникам на разных платформах 1С, то предпочтительно использовать Адаптер 1С.
Чтобы добавить базу-источник (СУБД), требуется указать:
- наименование;
- тип базы данных выбрать из списка: Oracle / MSSQL / PostgreSQL;
- способ доступа: «ADODB»;
- описание;
- имя сервера 1С;
- имя пользователя;
- пароль.

Пункт меню 1.4. Настройка пользователей и прав (стандартный интерфейс 1С)

Раздел настроек 2. Экспертные настройки
Настройки параметров очередей, фоновых заданий, и очистки журнала событий:

Секция «Настройки очереди» (см. рисунок выше, 1) – предназначены для оптимизации процесса загрузки/выгрузки: рекомендуется использовать настройки по умолчанию. Описание настроек очереди:
- «Максимальное количество потоков задания сбора данных» — количество параллельно запускаемых фоновых заданий при работе регламентного задания Сбора данных, при увеличении количества потоков увеличивается скорость получения данных, но до определенного предела, так как при исчерпании ресурсов (памяти и процессора) вместо увеличения скорости может произойти снижение производительности. Определение оптимального количества потоков – задача, которая решается экспериментально администратором программного продукта на основании анализа измененийвременных характеристик операций получения данных (по отчетам и регистрам документов «Факт выгрузки») истатистики изменения утилизации памяти и процессора при увеличении количества фоновых заданий (потоков) получения данных;
- «Максимальное количество попыток обработки задания» — для настройки количества попыток выполнения задания несколько раз, что нужно для случая, если подключение к источнику данных не стабильно и однократное обращение может привести к ошибке;
- «Номер попытки, с которой выполнять замену символов» — бывают ситуации, когда не удается записать полученные данные в базу данных хранилища, так как данные содержат символы, недопустимые для записи в БД. В системе настроена замена некоторых символов: апострофа «’» на «`», «?» — на пустое значениеи т.д. Операция замены делается построчно для каждого полученного строкового значения и потому — относительно медленно, поэтому имеет смысл задавать номер попытки получения-записи данных, с которой следует делать попытки замены символов;
- «Количество источников для обработки» — это максимальное количество, которое фоновое задание может взять в обработку;
- «Процент необработанных источников очереди» — это количество допустимых ошибок в очереди. Например, получаем данные из 100 источников, считаем, что если из 90 или более источников данные получены, то получение прошло успешно. Тогда устанавливаем процент — 10;
- секция «Таймауты фоновых заданий» (см. рисунок выше, 2) задаёт время (в минутах) ожидания при выполнении фонового задания:
- таймаут неактивного фонового задания;
- таймаут работы фонового задания.
При превышении таймаута фоновое задание считается «зависшим» и перезапускается.
Рекомендуется использовать настройки по умолчанию;
- секция «Прочее» (см. рисунок выше, 3):
- «Глубина хранения журнала событий (в днях)» — количество дней, по прошествии которых будут автоматически очищены записи в журналах, относящиеся к фактам выгрузки, сценариям обработки данных. Периодическая очистка позволяет оптимизировать объем, занятый логами, и способствует быстрой работе отчетов по логам.
Настройка подключения к базе-источнику
Для указания источника данных нужно настроить подключение к базе-источнику данных. Возможно получать данные из нескольких баз-источников. Для удобства работы однотипные источники объединяются в наборы источников. В наборе может быть один или несколько источников данных.
Поскольку источники данных могут менять месторасположение, менять платформу и т.п., а по сути, остаются тем же самым источником данных, для описания набора источников используется многоуровневая структура метаданных:
- для хранения объекта «Набор источников» служит справочник «Набор источников»;
- для хранения объекта «Источник данных» служит справочник «Источники данных»;
- источники данных объединяются в набор при помощи документа «Регистрация набора источников»:

Поддерживается выбор значения по показателям:
- для одного набора источников может быть создан один документ «Регистрация набора источников»;
- один источник данных может одновременно входить в несколько наборов данных.
Настройка подключения к источнику состоит из трёх этапов:
- установить настройку соединения с базой;
- создать элемент справочника «Источник данных»;
- создать элемент справочника «Набор источников».
Подробное описание настройки источника — ниже.
1. Установить настройку соединения с базой
Настроить список доступных баз данных можно в разделе меню: «Размещение данных» / «Базы данных».

Нажмите кнопку «Создать», в открывшемся окне заполните название базы данных (см. рисунок ниже, 1). Для базы 1С установить тип базы «1С» и тип подключения «COM-Connector» или «Адаптер для 1С»)(см. рисунок ниже, 2). Для типа подключения «COM-Connector» выберите версию платформы 1С (см. рисунок ниже, 3) и заполните имя сервера 1С (см. рисунок ниже, 4), и, при необходимости, имя дублирующего сервера, например, сервера с копией базы-источника (если имеется). Укажите имя пользователя и пароль (см. рисунок ниже, 5):

Для базы СУБД — надо выбрать тип базы (MS SQL / PostgreSQL / Oracle / Vertica / ClickHouse / …) и способ доступа («ADODB»). Заполните имя сервера, имя пользователя и пароль для подключения:

Сохраните настройки при помощи кнопки «Записать».
После заполнения настроек проверьте наличие подключения к базе при помощи кнопки «Проверить подключение» (см. предыдущий рисунок, 6).
2. Создать элемент справочника «Источник данных»
Для создания источника данных для настроенной базы данных, нажмите кнопку «Создать на основании».
В открывшемся окне укажите наименование источника (см. рисунок ниже, 1), ранее настроенная база данных уже заполнена (см. рисунок ниже, 2), укажите название организации (см. рисунок ниже, 3). Сохраните источник данных при помощи кнопки «Записать»:

3. Создать элемент справочника «Набор источников»
Для создания элемента используйте команды интерфейса: «Начальная страница» / «Сбор данных» / «Регистрация набора источников» или меню: «Размещение данных» / «Регистрация набора источников».
Далее, следует:

- нажать кнопку «Создать»;
- указать наименование «Набора источников»;
- заполнить таблицу «Источники данных». По кнопке «Добавить» (см. рисунок выше) – добавляется 1 строка – элемент из справочника «Источники данных», выбрать ранее созданный источник данных из справочника;
- нажать кнопку «Записать и закрыть», при проведении происходит запись в
РегистрСведений.Набор_источников:

Настройка подключения к базе хранилища данных
Настроить список доступных баз данных можно в разделе меню: «Размещение данных» / «Базы данных».
Нажмите кнопку «Создать», в открывшемся окне (см. рисунок ниже) заполните название базы данных (см. рисунок ниже, 1), тип базы установите «MS_SQL» или «PostgreSQL» и тип подключения «ADODB», укажите сервер, где расположена база (см. рисунок ниже, 3). Укажите имя пользователя и пароль (см. рисунок ниже, 4). Сохраните настройки при помощи кнопки «Записать».
После заполнения настроек проверьте наличие подключения к базе при помощи кнопки «Проверить подключение» (см. рисунок ниже, 5).

Настройка профилей и групп пользователей
При первом запуске автоматически создаются следующие профили групп доступа («Администрирование» / «Настройки пользователей и прав» / «Группы доступа» / «Профили групп доступа»):
- «Администраторы ETL» — Изменяют основные настройки ETL и подключают базы данных;
- «Аналитики» — могут настраивать все процессы по получению и обработке данных, настраивать источники данных, правила получения данных, расписание запуска пакетов, просматривать журналы и лог-файлы процессов и ошибки;
- «Наблюдатели» — могут запускать получение данных вручную, просматривать журналы и лог-файлы процессов и ошибки;
- «Только просмотр» — может отслеживать протекание процессов, просматривать журналы и лог-файлы процессов и ошибки.
Необходимо перейти в «Администрирование» / «Настройки пользователей и прав» / «Группы доступа» и создать одноименные группы доступа с привязанными профилями в соответствии с таблицей соответствия:
Описание профилей пользователе по группам доступа
| Группа доступа | Профиль пользователей |
|---|---|
| Администраторы ETL | Администраторы ETL |
| Аналитики | Аналитики |
| Наблюдатели | Наблюдатели |
| Только просмотр | Только просмотр |
Для добавления пользователей необходимо перейти в пункт «Администрирование» / «Настройки пользователей и прав» / «Пользователи»:

В списке пользователей нажать кнопку «Создать»:

В форме «Пользователь (создание)» заполнить параметры:
- «Вход в программу»: «разрешен»;
- полное наименование (согласно принятым правилам);
- имя для вход» (согласно принятым правилам);
- «Физ. лицо»;
- пароль (необязательно для заполнения);
- «Аутентификация операционной системы»: «Установлено»;
- пользователя операционной системы (чтобы не устанавливать пароли);
- режим запуска: «Авто».
Установить на соответствующих закладках:
- E-mail;
- профили (в соответствии с правами доступа):


2.9 - Подключение ClickHouse
Подключение баз ClickHouse в ОС Windows
Перед подключением баз данных СУБД ClickHouse, если Аналитический портал, Агент ETL развернуты в операционной системе Windows, необходимо настроить базу часовых поясов.
Для этого необходимо:
- cкачать файл zoneinfo.zip и переместить его в локальный каталог (например, «D:\bi-portal\zoneinfo».zip). Или в каталог с Аналитическим порталом/Агентом ETL;
- перейти в «Свойства системы» / «Дополнительно» / «Переменные среды»;
- создать новую системную переменную
ZONEINFOв разделе системные переменные и указать в ней полный путь к файлу «zoneinfo.zip»:

- После необходимо перезапустить службу Агента ETL и / или Modus Аналитический портал.
Агент ETL и Modus Аналитический портал используют в работе ClickHouse TCP-protocol, поэтому при настройке подключения нового источника, следует указывать порт 9000 (по умолчанию).
2.10 - Разграничение доступа в разрезе проектов
В Модус ETL можно разграничить доступ к базам данных, источникам данных, составам выгрузки, правилам выгрузки, сценариям и пакетам обработки данных. Для этого реализовано разграничение доступа по проектам. Разграничение доступа работает для пользователей с правами аналитика.
Если пользователю назначены права администратора системы, разделение доступа по проектам игнорируется.
Для ограничения доступа вам необходимо:
- включить учет в разрезе проектов;
- включить ограничение доступа на уровне записей;
- создать профиль доступа с разграничением доступа;
- создать группу доступа;
- назначить пользователя в выбранную группу доступа.
Включение учета в разрезе проектов
Для включения учета по проектам в Модус ETL необходимо осуществить ряд шагов.
Перейти в подсистему «Главное» / «Информация» / «Основные настройки», затем на вкладку «Проекты» и установите флажок «Использовать проекты», после нажать кнопку «Записать и закрыть».
Создайте нужные проекты, по которым необходимо разделять доступ «Главное» / «Настройки» / «Проекты».
Выйдите из Модус ETL.
Зайдите в форму выбора запуска информационной базы, выберите из списка информационную базу ETL и нажмите «Изменить»:

Перейдите с помощью вкладки далее до поля «Дополнительные параметры запуска», введите в поле текст:
/C ЗапуститьОбновлениеИнформационнойБазы

Запустите информационную базу. После удалите текст в дополнительных параметрах запуска.
Ограничение доступа на уровне записей
Перейдите в «Администрирование» / «Настройки пользователей и прав»:

Установите флажок «Ограничивать доступ на уровне записей».
Создание группы пользователей с разграничением доступа
Перейдите в «Администрирование» / «Настройки пользователей и прав» / «Группы доступа» и нажмите «Создать».
В открывшейся форме заполните наименование группы, поле «Профиль» выберите профиль «Аналитики», перейдите на вкладку «Ограничения доступа» и в нижней табличной части установите пользователю доступные ему проекты, затем нажмите кнопку «Записать и закрыть».
Создание пользователя с правами аналитика
Перейдите в подсистему «Администрирование» / «Настройки пользователей и прав» / «Пользователи». Нажмите кнопку создать и заполните учетные данные карточки. После перейдите на закладку «Права доступа» и выберите нужную группу пользователю.
Настройка учета по проектам в объектах ETL
В объектах «Базы данных», «Источники данных», «Установка правил выгрузки», «Наборы наборов источников», «Составы выгрузок», «Сценарии обработки данных», «Пакеты обработки данных» и некоторых других, реализованы разделения доступа по проектам. Информация о проектах настраивается в карточке доступа.
Особенности работы с проектами
База данных может быть отнесена к нескольким проектам, источник данных может быть отнесен только к одному проекту. Для использования одной базы данных в нескольких проектах, необходимо создать свой источник, с ссылкой на базу данных для каждого проекта, где она указана.
Набор источников, источник и правило выгрузки должны иметь один и тот же проект, что и состав выгрузки, иначе его выполнение прервется по ошибке.
2.11 - Запуск пакетов, составов, сценариев используя API
В Modus ETL реализован API в виде http-сервиса для запуска Составов выгрузки, Сценариев, Пакетов обработки данных.
Публикация на веб-сервере
Для работы сервиса необходимо выполнить его публикацию на веб-сервере.
Инструкции для публикации информационной базы на веб-сервере доступны в руководстве администратора на сайте Информационно-технологического сопровождения 1C.
См. также Инструкция публикации IIS на инфостарт.
Для публикации сервиса необходимо:
- В режиме конфигуратора перейти: «Администрирование» / «Публикация на веб. сервере…».
- В открывшемся окне выбрать вкладку http-сервисы, и установить флаг напротив сервиса «хс_ЗапускОбъектов».
- Сохранить настройки и перезагрузить веб-сервер.
Запуск объектов
Для запуска объекта необходимо отправить http-запрос на адрес: «/object/run». Пользователь для подключения должен иметь роль «Запуск объектов».
В случае удачного запуска сервис вернет код состояния 200 и текстовое сообщение об успешном запуске. В противном случае сервис вернет текст ошибки.
Сервис логирует свои действия в журнал регистрации. Имя области: «Запуск объектов через сервис».
Пример JSON для запуска состава выгрузки
{
"object": "composition",
"uuid": "00000000-0000-0000-0000-000000000000",
"parameters": [
{
"parameterName": "name",
"parameterValue": "value",
"parameterType": "date",
"packageNumber": 1},
{
"parameterName": "name",
"parameterValue": "valule",
"packageNumber": 1},
]
}
Параметры object и uuid обязательны для заполнения. uuid выводится в форме состава выгрузки.
Параметр parameterType должен принимать значение date, если передается параметра типа Дата.
Пример JSON для запуска сценария
{
"object": "scenario",
"uuid": "00000000-0000-0000-0000-000000000000",
"parameters": [
{
"parameterName": "name",
"parameterValue": "value",
"parameterType": "date",
}
]
}
Параметры object и uuid обязательны для заполнения. uuid выводится в форме сценария.
Параметр parameterType должен принимать значение date, если передается параметра типа Дата.
Пример JSON для запуска пакета обработки данных
{
"object": "package",
"uuid": "00000000-0000-0000-0000-000000000000"
}
Оба параметра обязательны. uuid выводится в форме пакета обработки данных.
2.12 - Технические настройки для подготовки к работе
1. Основные настройки
Для работы системы необходимо установить настройки, регулирующие доступ к данным и получение данных.
Расположение в меню: «Главное» / «Информация» / «Основные настройки».
Здесь устанавливают настройки, которые будут использоваться по умолчанию. Пользователь может изменить их для однократного использования.
Описание настроек:
- Закладка «Настройки получения данных» (см. рисунок выше) — устанавливаются правила, по которым обновляются данные.
Использовать менеджер сервиса 1С: Fresh — загрузка справочной информации из менеджера сервиса.
При загрузке справочных данных:
- «Обновлять имеющиеся» — найти имеющиеся данные и, если нашли, обновить их, новые элементы не добавлять;
- «Загружать отсутствующие» — проверить имеются ли данные, если нет — добавить, если есть — ничего не делать;
- «Обновлять имеющиеся и загружать отсутствующие» — комбинация предыдущих пунктов: проверить имеются ли данные, если нет — добавить, если есть — обновить.
Остановить выполнение пакета при отсутствии лога — останавливает выполнение пакета при отсутствии документа «Факт выгрузки».
Режим записи данных во внешний приемник:
- «Добавить» — дополнить уже имеющийся набор данных (данные могут дублироваться);
- «Очистить и добавить» — удалить имеющиеся данные и загрузить заново;
- «Скопировать и добавить» — сделать копию имеющихся данных (создается новая таблица тем же именем и постфиксом-датой операции), удалить имеющиеся данные и загрузить заново.
Использовать агентов — использовать агентов для сбора данных и / или выполнения запросов к СУБД
- Агент для выполнения сценариев — агент, который используется для выполнения запросов к БД
- Агенты ETL — переход к списку всех агентов
- Максимальное количество заданий агентам — количество заданий по сбору данных из одного источника по одному правилу
Использовать обезличивание при получении данных — возможность настройки обезличивания в правиле выгрузки
Тип сериализации объектов при работе через Адаптер ETL:
- «JSON»;
- «JSONORIG»;
- «XML»;
- «INT».
- Закладка «Настройка пользователя ETL» (см. рисунок ниже) — параметры доступа (логин и пароль) к базам-источникам по умолчанию. При необходимости возможно для каждой базы-источника настроить свои параметры доступа в справочнике «Базы данных»:
- Закладка «Настройки очереди» — настройки, предназначенные для оптимизации процесса загрузки / выгрузки данных:
- «Максимальное количество потоков задания сбора данных» — количество параллельно запускаемых фоновых заданий при работе регламентного задания сбора данных. При увеличении количества потоков увеличивается скорость получения данных, но когда потоков слишком много они начинают мешать друг другу и вместо увеличения скорости происходит задержка;
- «Максимальное количество попыток обработки задания очереди» — позволяет пытаться выполнить задание несколько раз, это нужно из-за того, что подключение к источнику данных может быть нестабильно и однократное обращение может привести к ошибке;
- «Номер попытки, с которой выполнять замену символов» — бывают ситуации, когда не удается записать полученные данные, так как они содержат спецсимволы. В системе настроена замена некоторых символов («’», «-», «>», «`», …), можно их искать и заменять в первой же, но тогда идет увеличение времени получения данных, поэтому устанавливаем номер попытки — т.е. если в первых попытках записать не получилось, то пробовать сделать замену символов;
- «Настроить символы для замены» — замена символов в строках получаемых данных;
- «Процент необработанных источников очереди» — это количество допустимых ошибок в очереди. Например, получаем данные из 100 источников, считаем, что если из 90 или более источников данные получены, то получение прошло успешно. Тогда устанавливаем процент — 10.
- «Коэффициент понижения количества захватываемых в очереди» — влияет на количество заданий в очереди, захватываемых фоновым заданием при распределении.
- «Ограничения количества источников порции» — минимальное и максимальное количество источников, которое фоновое задание может взять в обработку.
- Закладка «Таймауты» — настройки времени ожидания при выполнении фонового задания:
- Закладка «COM-connector» — для настройки COM-connector:
- Закладка «Верификация»:
- «Использовать верификацию данных» — включение механизмов проверки данных на соответствие стандарту, на соответствие эталонным значениям.
- Закладка «Управление хранилищем» (см. рисунок ниже, «Основные настройки» / «Управление хранилищем»):
- «БД SQL по умолчанию» — база данных — хранилище по умолчанию;
- «Использовать трансформацию таблиц» — включает подсистему трансформации таблиц в схему звезда
- Закладка «Интерфейс» (см. рисунок ниже, «Основные настройки» / «Интерфейс»):
- «Количество отображаемых пакетов виджетом контроля» — количество отображаемых пакетов виджетом контроля на начальной странице;
- «Количество отображаемых прогрессов очередей виджета очередей» — количество отображаемых прогрессов очередей виджета очередей на начальной странице;
- «Выбирать только пользовательские типы в полях выбора типов» — ограничивает выбор типа поля только пользовательским типом;
- «Упрощенный ввод квалификаторов типов» — упрощенный режим ввода квалификаторов типа.
- Закладка «Пресеты»:
- «Использовать пресеты» — включает подсистему «Пресеты», используемую для выгрузки и загрузки настроек.
- Закладка «Проекты»:
- «Использовать проекты» — включает возможность указания проектов.
- Закладка «KPI» (см. рисунок ниже, «Основные настройки» / «KPI»):
- «База данных для KPI» — база данных, в которой будут сформированы таблицы KPI;
- «Использовать KPI» — создание и выполнение сценария формирования таблиц KPI в указанной базе данных.
- Закладка «НСИ»:
- «Использовать НСИ» — включает модуль учета нормативно-справочной информации, предназначенный для хранения и использования объектов НСИ — справочников и маппингов (маппинг — соответствие / связь элементов первичных данных элементам справочников).
- Закладка «СЛК» (см. рисунок ниже, «Основные настройки» / «СЛК») — настройки системы лицензирования и защиты конфигурации:
- «Параметры связи» – настройка параметров связи с сервером СЛК;
- «Консоль сервера» – консоль сервера лицензирования выводит текущие параметры СЛК и служит для диагностики проблем;
- «Установка/обновление лицензий» – интерфейс для запуска процедур по установке и активации лицензий.
- Закладка «Прочее» (см. рисунок ниже, «Основные настройки» / «Прочее»):
- «Глубина хранения журнала событий (количество дней)» — количество дней, по прошествии которых будут автоматически очищены записи в журналах, относящиеся к фактам выгрузки, сценариям обработки данных. Периодическая очистка позволяет оптимизировать объем, занятый логами, и способствует быстрой работе отчетов по логам;
- «Максимальное количество источников при очистке» — максимальное количество источников, по которым будут очищены записи в журнале событий сбора данных;
- «Путь к comconnector оригинальной версии (версии сервера 1С)» — имя компьютера, на котором будет создан com объект;
- «Использовать шаблоны шагов сценариев» — шаблоны позволяют формировать скрипт трансформации данных для шага сценария, используя визуальный интерфейс;
- «Использовать интеграцию с OLAP-сервером» — для включения возможности интеграции с «Полиматикой»;
- «Группа агрегатных функций» — агрегатные функции, доступные для выбора в мастере группировки данных;
- «Режим заполнения служебных полей приемника по умолчанию» — режим заполнения служебных полей в правиле выгрузки по умолчанию;
- «Постфикс для публикации адаптера» — постфикс базы данных источника;
- «Использовать механизм распараллеливания записи в приемник» — признак доступности пакетной записи для базы данных;
- «Взаимодействие с python» — использование предсказательной аналитики, если флаг установлен, то в сценарии доступны мастера «Кластеризация» и «Линейная регрессия»;
- «Использовать WorkFlow» — визуальный интерфейс проектирования сценариев обработки данных.
2. Параметры администрирования
Для выполнения различных административных действий на кластере серверов 1С, необходимо установить параметры администрирования кластера. Расположение в меню: «Главное» / «Информация» / «Параметры администрирования»:
В открывшейся форме (см. рисунок ниже), заполнить требуемые поля:
- логин / пароль администратора кластера;
- «Порт кластера серверов» (менеджер кластера);
- вариант «Подключения к кластеру серверов»;
- «Адрес» (адрес сервера 1С);
- «Порт» (порт агента сервер).
Важно! Если сервер 1С развернут на ОС Linux, в качестве способа подключения к кластеру серверов выбирать «Через сервер администрирования (ras)»
Предварительно на сервере приложений 1С должен быть установлен сервер администрирования кластера серверов (ras).
Инструкции по установке доступны в Руководстве администратора на сайте Информационно-технологического сопровождения 1C.
2.13 - Контрольные метрики
HTTP-сервис предназначен для получения контрольных метрик.
Публикация на веб-сервере
Для работы сервиса необходимо выполнить его публикацию на веб-сервере.
Инструкции для публикации информационной базы на веб-сервере доступны в Руководстве администратора на сайте Информационно-технологического сопровождения 1C.
Cм. также Инструкция публикации IIS на инфостарт.
Для публикации сервиса необходимо:
- в режиме конфигуратора перейти: «Администрирование / «Публикация на веб. сервере…»;
- в открывшемся окне выбрать вкладку http-сервисы, и установить флаг напротив сервиса «хс_Метрики»;
- сохранить настройки и перезагрузить веб-сервер.
Настройка контрольной метрики
Для получения контрольной метрики необходимо выполнить ее настройку.
Список контрольных метрик находится: «Главное» / «Настройки» / «Контрольные метрики».
Для добавления/изменения контрольной метрики пользователь должен иметь роль Добавление изменение метрик.
Реквизиты контрольной метрики:
- «Наименование» — наименование контрольной метрики;
- «Ключ» — уникальный идентификатор контрольной метрики. Используется для поиска метрики;
- «Текст запроса» — текст запроса на языке запросов 1С. Запрос выполняется при получении метрики. Результатом запроса может быть:
- Структура, если в результате выполнения запроса одна строка. Ключи структуры соответствуют полям выборки запроса;
- Массив из Структура, если в результате запроса более одной строки. Ключи структуры соответствуют полям выборки запроса;
- «После выполнения запроса» — текст обработчика на языке 1С. Выполняется после выполнения запроса. Предназначен для обработки результата выполнения запроса.
Получение контрольной метрики
Для получения контрольной метрики необходимо отправить http-запрос на адрес: «/metrics/get_data».
Пользователь для подключения должен иметь одну из ролей «Добавление изменение метрик» или «Чтение метрик».
В случае удачного получения сервис вернет код состояния 200 и значение метрики. В противном случае сервис вернет текст ошибки.
Сервис логирует свои действия в журнал регистрации. Имя области: «Контрольные метрики».
Пример JSON для получения метрики
{
"КлючМетрики1": {
"Параметр1": "ЗначениеПараметра1"
},
"КлючМетрики2": null
}
3 - Сбор данных
3.1 - Настройка соединения с БД
Настройка подключения к базе-источнику
Для указания источника данных нужно настроить подключение к базе-источнику данных. Возможно получать данные из нескольких баз-источников. Для удобства работы однотипные источники объединяются в наборы источников. В наборе может быть один или несколько источников данных.
Т.к. источники данных могут менять месторасположение, менять платформу и т.п., а по сути, остаются тем же самым источником данных, для описания набора источников используется многоуровневая структура метаданных:
- Для хранения объекта «Набор источников» служит справочник «Набор источников»;
- Для хранения объекта «Источник данных» служит справочник «Источники данных»;
- Источники данных объединяются в набор при помощи документа «Регистрация набора источников»:
Поддерживается выбор значения по показателям:
- для одного набора источников может быть создан один документ «Регистрация набора источников»;
- один источник данных может одновременно входить в несколько наборов данных.
Настройка подключения к источнику состоит из трёх этапов:
- установить настройку соединения с базой;
- создать элемент справочника «Источник данных»;
- создать элемент справочника «Набор источников».
Подробное описание настройки источника – ниже.
Установка соединения с базой
Настроить список доступных баз данных можно в разделе меню: «Размещение данных» / «Базы данных».
Нажмите кнопку «Создать», в открывшемся окне заполните название базы данных (см. рисунок ниже, 1).
Для базы 1С установить тип базы «1С» и тип подключения «COM-Connector» или «Адаптер для 1С») (см. рисунок ниже, 2).
Для типа подключения «COM-Connector» выберите версию платформы 1С (см. рисунок ниже, 3) и заполните имя сервера 1С (см. рисунок ниже, 4), и, при необходимости, имя дублирующего сервера, например, сервера с копией базы-источника (если имеется). Укажите имя пользователя и пароль (см. рисунок ниже, 5):
Для базы СУБД:
выбрать тип базы (MS SQL / PostgreSQL / Oracle / Vertica / ClickHouse / …) и способ доступа («ADODB»). Заполните имя сервера, имя пользователя и пароль для подключения:
Сохраните настройки при помощи кнопки «Записать».
После заполнения настроек проверьте наличие подключения к базе при помощи кнопки «Проверить подключение».
Настройка подключения к базе хранилища данных
Настроить список доступных баз данных можно в разделе меню: «Размещение данных» / «Базы данных».
Нажмите кнопку «Создать», в открывшемся окне (см. рисунок ниже) заполните название базы данных (см. рисунок ниже, 1), тип базы установите «MS SQL» или «PostgreSQL» и тип подключения «ADODB» (см. рисунок ниже, 2), укажите сервер, где расположена база (см. рисунок ниже, 3). Укажите имя пользователя и пароль (см. рисунок ниже, 4). Сохраните настройки при помощи кнопки «Записать».
После заполнения настроек проверьте наличие подключения к базе при помощи кнопки «Проверить подключение» (см. рисунок ниже 5).
3.2 - Источники данных
Источниками данных для ModusETL могут быть:
- базы данных (СУБД);
- приложения 1С:Предприятие 8 (базы данных 1С);
- файлы;
- веб-сервисы.
В ModusETL различают сущности «База данных» и «Источник данных».
- «База данных» — описывает подключение к базе данных. Содержит тип СУБД, способ и параметры подключения (адрес / путь, логин, пароль). При этом база данных может выступать как источником данных, так и приемником — хранилищем данных.
- «Источник данных» — описывает конкретный источник для получения данных. Источник с видом «База данных» и «Файл» содержит ссылку на «Базу данных», дополнительные параметры подключения (например, «Номер области для облачных баз 1С»), а также дополнительные атрибуты («Организация», «Абонент», «Статус данных» и т.п.). Особенностью для «Источника данных« с видом «веб-сервис» является отсутствие ссылки на «Базу данных», так как параметры подключения задаются в правиле выгрузки.
Для обычных баз данных и 1С-приложений: одна «База данных» — это один «Источник».
Для облачных баз данных 1С, работающих по технологии 1C: Fresh — одна база содержит несколько областей данных и номер области служит разделителем учета для разных организаций. В этом случае источником данных в терминах программного продукта будет конкретная область. Для дальнейшего получения данных определенной организации нужно подключиться к базе данных и установить разделитель учета — номер области.
Для настройки получения данных однотипные источники, из которых требуется получать данные в одном ETL-процессе, необходимо объединять в наборы источников. В наборе может быть один или несколько источников данных.
3.2.1 - Настройка источников данных
1. Создание подключения — настройка «Базы данных»
Для настройки подключения к источникам (базам данных,1С-приложениям, файлам) или приемникам (в т.ч. хранилищам данных), нужно перейти в «База данных» одним из способов: «Начальная страница» / «Источники данных» / «База данных» или меню: «Размещение данных» / «Справочная информация» / «База данных»:
Для добавления нового подключения нажать кнопку «Добавить» (см. рисунок ниже, 1) и в открывшейся форме выбрать прежде всего тип БД / подключения ( рисунок ниже, 2). Для каждого типа подключения специфичны свои настройки:
Из общих настроек здесь следует упомянуть флаг «Используется для получения данных» (см. рисунок ниже, 1), который влияет на отображение в форме списка:
Флаг «Использовать дублирующий сервер» и поле «Дублирующий сервер» (см. рисунок выше, 2) с адресом альтернативного сервера, на котором может быть размещена копия основной БД.
Если флаг не установлен, то строка для неиспользуемого элемента будет отображаться в форме неактивной:
2. Создание нового источника данных
Чтобы создать новый источник данных, нужно перейти в «Источники данных» одним из способов: «Начальная страница» / «Источники данных» или меню: «Размещение данных» / «Справочная информация» / «Источники данных»:
Элемент справочника можно создать кнопкой «Создать» или копированием существующего источника или кнопкой «Создать элементы по шаблону»:
Дальнейшая настройка зависит от вида источника данных.
3. Настройка разных видов источников данных
Источниками данных могут быть:
- база данных (1С или СУБД);
- веб-сервис;
- файл.
3.1. Настройка для вида «База данных»
Если видом источника данных является «База данных», то необходимо заполнить поля «Вид источника» и «База данных»:
«Базу данных» возможно выбрать из списка настроенных подключений (см. рисунок ниже, 1) или создать новое подключение по кнопке «+Добавить» (см. рисунок ниже, 2):
3.2. Настройка для вида «Веб сервис»
Основная настройка доступа к веб-сервису происходит при установке правил выгрузки. В настройке источника данных на вкладке «Основная» нужно указать вид «Веб-сервис» и при необходимости указать доп.атрибуты (например, организацию, к которой будут относиться полученные данные и прочее).
На вкладке «Дополнительные настойки» необходимо указать «Адрес сервера»:
3.3. Настройка для вида «Файл»
Вид источника данных «Файл» предполагает регулярную загрузку данных из файлов (xlsx, xls или csv), которые размещаются в определенном каталоге, а после обработки переносятся в другой каталог — «Каталог обработанных файлов».
Важно: каталоги должны располагаться на сервере, где находится 1С: ETL.
Источники описывают шаблон группы файлов.
Для источников вида «Файл» указываются следующие параметры:
- «Вид источника» — файл;
- «База данных» — выбор из справочника «Базы данных». Заполняется если получение данных происходит через ADO-ODBC. Настройка базы данных, описывающей конкретный файл или каталог с файлами, подробнее описана ниже в п.3.4;
- «Каталог к файлу» — каталог, с новыми файлами для загрузки;
- «Маска файлов» — маска, по которой будет происходить поиск новых файлов в Каталоге к файлу;
- «Каталог обработанных файлов, Каталог файлов с ошибками» — каталоги, куда после обработки (успешной или нет) будут перемещены новые файлы;
3.4. Настройка подключения к источнику типа «Файл»
Используется при получении данных через ADO-ODBC.
При настройке «Базы данных» для файлов «XLSX» и «XLS» указываются следующие параметры:
- «Тип базы данных» — файл;
- «Провайдер СУБД» — шаблон строки подключения с драйверами нужной разрядности;
- «Способ доступа» — «ADODB»;
- «Путь к файлу» — путь к одному из файлов. При получении данных через «Состав выгрузки» этот параметр может быть переопределен в зависимости от настроек конкретного источника данных
При настройке базы данных — файла «CSV» указываются следующие параметры:
- «Тип базы данных» — файл;
- «Провайдер СУБД» — шаблон строки подключения с драйверами нужной разрядности;
- «Способ доступа» — «ADODB»;
- «Каталог», из которого будут загружаться «CSV» файлы нужно указывать не в «Пути к файлу», а в другом параметре — «Имя пользователя».
Сохранить настройки, нажав кнопку «Сохранить».
После настройки базы данных можно выполнить проверку корректности настроек — нажать кнопку «Проверить подключение».
3.4.1. Требования к исходным файлам загрузки
Файлы Excel («XLSX», «XLS»):
- в заголовках колонок не должно быть символов перевод строки, точка, запятая, точка с запятой (если в заголовке есть пробелы, то заголовок нужно заключать в квадратные скобки в запросе правила);
- длина заголовков колонок не должна превышать 64 символа;
- у колонок с данными типа дата должен быть определен формат ячеек — «Дата».
Файлы «CSV»:
- заголовки не должны содержать символы «.», «,», перевод строки (если в заголовке есть пробелы, то заголовок нужно заключать в двойные кавычки в запросе правила и в схеме);
- если значение содержит в себе
CRLF,CR,LF(символы-разделители строк), двойную кавычку или запятую (символ-разделитель полей), то заключение значения в кавычки обязательно. В противном случае — допустимо; - если внутри закавыченной части встречаются двойные кавычки, то используется специфический квотинг кавычек в «CSV» — их дублирование;
- ограничить длину наименования названия поля (
AS) до 20 символов.
4. Регистрация набора источников
«Регистрация набора источников» предназначена для объединения аналогичных по структуре / конфигурации источников в группу, с тем, чтобы получать данные по единым правилам сразу для всей группы. Открыть форму «Регистрации набора источников» возможно либо с начальной страницы, либо через раздел меню: «Главное» / «Настройки» / «Регистрация набора источников»:
4.1. Заполнение «Регистрации набора источников»:
-
Выбрать существующий или создать и выбрать новый «Набор источников».
-
Заполнить таблицу «Источники данных». Варианты заполнения:
-
по кнопке «Добавить» (см. рисунок выше, 1) — добавляется одна строка при выборе из «Источников данных»;
-
по кнопке «Подбор» (см. рисунок выше, 2) — возможно открыть форму для «Подбора источников для набора…», для добавления / удаления сразу нескольких источников данных, удовлетворяющих условиям отбора (см. рисунок ниже):
Последовательность действий описана ниже.
- Настроить отборы в верхней таблице. По кнопке «Добавить новый элемент» (см. рисунок выше, 3) добавляется строка в таблицу отборов. Настройка отбора осуществляется стандартным для 1С образом.
- Автоматически заполнится таблица «Новые источники» с подходящими условиями отбора и еще «не зарегистрированными» элементами для этого набора источников (см. рисунок выше, 4). Возможно установить / снять отметки для конкретной строки таблицы или для всех строк, используя кнопки.
- Также автоматически заполнится таблица «Источники для удаления», в которую попадают уже зарегистрированные в наборе источники, но которые не соответствуют текущим условиям отбора (см. рисунок выше, 5).
- После нажатия кнопки «ОК» (см. рисунок выше, 6) отмеченные в таблицах «Новые источники» / «Источники для удаления» элементы будут добавлены / удалены из Набора источников.
Для облачных баз 1С: Fresh:
- по кнопке «Загрузить из файла» (см. рисунок выше, 3 или рисунок выше, 7) — можно загрузить список областей из xlsx-файла, содержащего номера областей 1С:Fresh. Возможно управлять режимом добавления новых строк — при установленном флаге «Отчищать таблицу» (см. рисунок выше, 4), предварительно очищается табличная часть документа;
- по умолчанию включенные в набор источники получают признак «Включить», что говорит о том, что из этого источника будут получаться данные. Сняв этот признак можно исключить источник из Набора источников (эта возможность используется обычно для временного выключения источников из набора).
- для проставления / снятия признака «Включить» для всех строк служат кнопки (см. рисунок выше, 5);
- в наборе источников выведены также информационные панели, отображающие количество источников в наборе («Всего») и количество источников, для которых установлен флаг «Включено» (см. рисунок выше, 6 и 7);
- для случаев, когда возникает ошибка подключения, связанная с временной недоступностью источника, следует указать значение для параметра «Таймаут ожидания» — время ожидания в минутах перед повторной попыткой подключения. Если параметр не указывать, повторная попытка подключения произойдет практически сразу (см. рисунок выше, 8).
Для сохранения настроек нажать кнопку «Записать» / «Записать и закрыть».
Аналогичные описанным выше действиям по заполнению и корректировке набора источников, возможно осуществить в интерфейсе, открывающемся по кнопке «Показать регистрацию» и представленном на следующем рисунке:
5 Сервисные функции по управлению источниками данных
5.1. 1С: Fresh-источники. Интеграция с менеджером облачного сервиса для обновление справочной информации о источниках данных
Для облачных баз 1C: Fresh описание источников данных обычно содержится в Менеджере сервиса и возможно обновлять справочник «Источники данных», подключаясь к Менеджеру сервиса с помощью web-сервиса.
Источники данных и связанные с ними справочники — приложения, базы данных, организации — возможно обновлять вручную или автоматически (регламентным заданием).
Для запуска регламентного задания необходимо настроить «Менеджер облачного сервиса», при помощи которого можно получать информацию об источниках данных. Регламентное задание позволяет устанавливать разные режимы обновления. Например, режим обновления «Обновлять имеющиеся, загружать отсутствующие», позволяющий:
- для существующих записей (элемент найден по ключу) обновлять изменившиеся поля;
- для новых (элемент не найден по ключевому полю) в справочник добавлять новые записи.
Для активации функционала перейти в меню: «Главное» / «Информация» / «Основные настройки» / «Настройки получения данных» и включите флаг «Использовать менеджер сервиса 1С: Fresh»:
5.1.1. Запуск процедуры вручную
Для запуска процедуры вручную — перейти а меню: «Главное» / «Сервис» / «Загрузка справочной информации»:
5.1.2. Автообновление
Настройка регламентного задания загрузки данных об источниках (областях) через web-сервис осуществляется через меню: «Администрирование» / «Обслуживание» / «Регламентные операции» / «Регламентные и фоновые задания» / «Задание» — «Загрузка Справочной Информации». Регламентное задание нужно создать:
Затем установить флаг «Включено» и настроить расписание обновления:
5.2. Проверка доступности баз данных
5.2.1 Для проверки подключения к конкретной базе данных:
Меню: «Размещение данных» / «Базы данных» / «Выбрать базу», кнопка «Проверить подключение»:
В случае недоступности будет выведено подробное сообщение об ошибке:
5.2.2. Для проверки доступности всех БД
Меню: «Размещение данных» / «Базы данных», установить признак «Для всех баз» и запустить по кнопке «Проверить подключение». После проверки будет выведен отчет о доступности всех подключенных баз данных:
3.2.2 - Регистрация набора источников
«Регистрация набора источников» предназначена для объединения аналогичных по структуре / конфигурации источников в группу, с тем, чтобы получать данные по единым правилам сразу для всей группы. Открыть форму «Регистрации набора источников» возможно либо с начальной страницы, либо через раздел меню: «Главное» / «Настройки» / «Регистрация набора источников»:
Заполнение «Регистрации набора источников»:
- Выбрать существующий или создать и выбрать новый «Набор источников».
-
Заполнить таблицу «Источники данных». Варианты заполнения:
-
По кнопке «Добавить» (см. рисунок выше, 1) — добавляется одна строка при выборе из «Источников данных»;
-
По кнопке «Подбор» (см. рисунок выше, 2) — возможно открыть форму для «Подбора источников для набора…», для добавления / удаления сразу нескольких источников данных, удовлетворяющих условиям отбора (см. рисунок ниже):
Последовательность действий описана ниже.
- Настроить отборы в верхней таблице. По кнопке «Добавить новый элемент» (см. рисунок выше, 3) добавляется строка в таблицу отборов. Настройка отбора осуществляется стандартным для 1С образом.
- Автоматически заполнится таблица «Новые источники» с подходящими условиями отбора и еще «не зарегистрированными» элементами для этого набора источников (см. рисунок выше, 4). Возможно установить/снять отметки для конкретной строки таблицы или для всех строк, используя кнопки.
- Также автоматически заполнится таблица «Источники для удаления», в которую попадают уже зарегистрированные в наборе источники, но которые не соответствуют текущим условиям отбора (см. рисунок выше, 5).
- После нажатия кнопки «ОК» (см. рисунок выше, 6) отмеченные в таблицах «Новые источники» / «Источники для удаления» элементы будут добавлены / удалены из Набора источников.
Для облачных баз 1С: Fresh:
- по кнопке «Загрузить из файла» (см. рисунок выше, 3) — можно загрузить список областей из xlsx-файла, содержащего номера областей 1С: Fresh. Возможно управлять режимом добавления новых строк — при установленном флаге «Отчищать таблицу» (см. рисунок выше, 4), предварительно очищается табличная часть документа;
- по умолчанию включенные в набор источники получают признак «Включить», что говорит о том, что из этого источника будут получаться данные. Сняв этот признак можно исключить источник из набора источников (эта возможность используется обычно для временного выключения источников из набора).
- для проставления / снятия признака «Включить» для всех строк служат кнопки (см. рисунок выше, 5);
- в Наборе источников выведены также информационные панели, отображающие количество источников в наборе («Всего») и количество источников, для которых установлен флаг «Включено» (см. рисунок выше, 6 и 7);
- для случаев, когда возникает ошибка подключения, связанная с временной недоступностью источника, следует указать значение для параметра «Таймаут ожидания» — время ожидания в минутах перед повторной попыткой подключения. Если параметр не указывать, повторная попытка подключения произойдет практически сразу (см. рисунок выше, 8).
Для сохранения настроек нажать кнопку «Записать» / «Записать и закрыть».
Аналогичные описанным выше действиям по заполнению и корректировке набора источников, возможно осуществить в интерфейсе, открывающемся по кнопке «Показать регистрацию»:
3.3 - Загрузка данных из файлов
3.3.1 - Загрузка файлов csv и xlsx
Функциональность загрузки файлов дает возможность загрузить данные сформированные и / или обработанные вручную в Excel или данные текстовых файлов «CSV» в таблицу хранилища данных. Чтобы загрузка прошла успешно к содержанию и названию файлам предъявляются обязательные требования:
- Заголовки столбцов в загружаемых таблицах не должны содержать управляющие спецсимволы:
- «;»;
- «&»;
- переход на новую строку;
- Данные в загружаемых таблицах должны быть отформатированы в соответствии с составом данных и содержать однородную информацию в столбцах:
- текст;
- число;
- дата;
- В наборах данных не должно быть пустых строк и столбцов.
1. Мастер загрузки
Доступ к сервису осуществляется через меню: «Главное» / «Сервис» / «Загрузка файла в БД (мастер настройки)»:
Порядок работы:
- двигайтесь по шагам мастера;
- пока не выполнены условия для перехода на следующий шаг, перейти дальше нельзя;
- можно возвращаться на предыдущие шаги и изменять введенные настройки загрузки, а потом продолжать настройки;
- в любой момент можно остановить настройку с помощью мастера, при этом уже сделанные настройки не сохранятся;
- по окончании настройки можно сохранить сделанные настройки и использовать их для последующих загрузок из файлов аналогичной структуры.
Шаг 1 «Выберите исходный файл и место назначения данных»:
- укажите, требуется ли выгружать данные (см. рисунок выше, 1);
- выберите базу данных-приемник (см. рисунок выше, 2);
- выберите в новую или существующую таблицу должны загрузиться данные (см. рисунок выше, 3);
- если был выбран вариант загрузки в существующую таблицу, укажите таблицу выгрузки (вручную или выбрав из списка) (см. рисунок выше, 4);
- выберите тип файла (см. рисунок выше, 5);
- выберите файл для загрузки (см. рисунок выше, 6);
- когда выбран файл и приемник, становится доступна кнопка «Далее» (см. рисунок выше, 7), которая переводит процесс на следующий шаг.
Шаг 2 «Выберите лист»:
- по умолчанию для загрузки предлагается первый лист в файле, можно выбрать другой лист (см. рисунок выше, 1);
- после выбора листа можно просмотреть данные, которые на нем находятся и убедиться, что лист выбран правильно (см. рисунок выше, 2);
- если все верно, переходите на следующий шаг кнопка «Далее» (см. рисунок выше, 3).
Шаг 3 «Настройте диапазон загрузки»:
- уточните, где на выбранном листе находится строка заголовка (см. рисунок выше, 1);
- начало и окончание диапазона загрузки (см. рисунок выше, 2 и 3);
- количество строк предпросмотра на экране ограничено значением 50, так как чем больше строк нужно отобразить, тем дольше будет работать мастер. При необходимости можно увеличить количество строк предпросмотра вручную (см. рисунок выше, 4), строки предпросмотра отображаются (см. рисунок выше, 6);
- включенный флаг «Распространить значение в объединенных ячейках» означает, что при наличии в выбранном диапазоне объединенных ячеек, мастер разделит их и все заполнит текущим значением, если флаг выключить (см. рисунок выше, 5);
- если все настроено верно, переходите на следующий шаг, нажав кнопку «Далее» (см. рисунок выше, 7).
Шаг 4 «Соответствие исходных данных и таблицы-приемника»:
- выбирайте в области предпросмотра нужный столбец, нажимая на его заголовок (см. рисунок выше, 1);
- проверьте правильность предложенного системой названия поля, при необходимости измените его (см. рисунок выше, 2);
- проверьте правильность предложенного системой типа данных, при необходимости измените его (см. рисунок выше, 3);
- если столбец загружать не нужно, то установите переключатель «Импортировать поле» в положение «Нет» (см. рисунок выше, 4);
- если все столбцы настроены верно, переходите на следующий шаг, нажав кнопку «Далее» (см. рисунок выше, 5).
Шаг 5 «Проверьте структуру новой таблицы»:
- проверьте получившуюся структуру перед загрузкой данных, при необходимости можно поменять названия поле и тип данных (см. рисунок выше, 1);
- если структура данных настроена верно, переходите на следующий шаг, нажав кнопку «Далее» (см. рисунок выше, 2).
Шаг 6 «Введите название таблицы и запустите процесс»:
- введите название таблицы-приемника (см. рисунок выше, 1);
- флаг «Сохранить ошибки при загрузке строк из файла» включает запись ошибок (см. рисунок выше, 2);
- если все настроено верно, запустите процесс загрузки, нажав кнопку «Далее» (см. рисунок выше, 3).
2. Настройка загрузки вручную
Доступ к сервису через начальную страницу или через меню: «Главное» / «Сервис» / «Загрузка файла в SQL»:
Порядок работы:
-
на закладке «Основная» — выбрать файл для загрузки (см. рисунок выше, 1);
-
нажать кнопку «1. Проанализировать файл». При этом заполнится табличная часть со списком полей таблицы (см. рисунок выше, 2);
-
в табличной части при необходимости возможно отредактировать «Наименование», «Тип» и «Длину поля в создаваемой SQL-таблице» (см. рисунок выше, 3);
-
на вкладке «Пред. просмотр» возможно посмотреть, как будет выглядеть таблица:
- заполнить параметры на закладке «Все настройки»:
-
«База данных», «Имя таблицы», «Режим записи в SQL» (см. рисунок выше, 1);
-
параметры файла, в зависимости от типа (см. рисунок выше, 2, 4);
-
прочие настройки (см. рисунок выше, 3);
-
вернуться на закладку «Основная» нажать кнопку «Создать таблицу SQL». Если все верно, выведется сообщение о создании таблицы, иначе — описание ошибки;
-
нажать кнопку «Загрузить данные в SQL» (вкладка «Основная»). Данные из файла запишутся в SQL-таблицу.
3. Особенности использования «ADO-ODBC»
В ETL есть возможность использования «ADO-ODBC» для загрузки данных файлов.
Примечание: для использования «ADO-ODBC», необходимы соответствующие драйвера.
Для таких источников, со способом подключения «ADODB», в правилах выгрузки используется вид правила «Запрос» и формируется обычный SQL-запрос. Из особенностей можно выделить только описание секции FROM в запросе:
- для файлов «XLSX» и «XLS» в секции
FROMуказывается имя листа, из которого получаются данные в форматеИмяЛиста$. Например, для листа «Лист1» секцияFROMбудет выглядеть какFROM [Лист1$]; - для файлов «CSV» в секции
FROMуказывается имя файла. Например,SELECT * FROM datafile.csv.
При получении данных через «ADO-ODBC», есть возможность использовать Агента ETL:
- для Windows — опционально.
- для Unix-подобных систем — обязательно.
Для использования Агента ETL необходимо выбрать его в составе выгрузки на вкладке «Дополнительно»:
3.3.2 - Загрузка JSON файлов
«Сырые» (первичные) данные — данные, полученные от источника, в формате специфичном для источника, но необязательно совпадающем с форматом данных, используемым в хранилище. Если формат «сырых» данных делает невозможным прямое их помещение в хранилище, необходимо применить алгоритмы извлечения. Выбор алгоритма обусловлен типом данных. Алгоритм извлечения данных нуждается в некоторых настройках, предварительно выполненных пользователем. Данные настройки специфичны как для формата данных, так и для конкретной структуры данных.
Сумма таких настроек является правилом разбора данных.
В ETL правила разбора данных находятся в справочнике «Правила разбора данных». Для того, чтобы открыть справочник «Правила разбора данных»,перейдите в «Панель функций», разделы «Главное» / «Настройки» / «Установить правила разбора данных»:

Правило разбора данных
Задача правила — указать алгоритму извлечения, где в данных находится нужная информация, в какие поля таблицы-приёмника и с каким типом следует её поместить.
Форма правила:

Описание табличной части правила
- «Колонка таблицы» (2) — имя колонки таблицы, в которую следует поместить значение из первичных данных.
- «Тип поля» (3) — тип данных колонки таблицы.
- «Путь к элементу» (4) — описание пути к элементу внутри первичных данных. Используется формат, специфичный для типа первичных данных. Для «JSON» — используется
JSONPath, для «XML» —XMLPathи т.д. - «Тип элемента» (5) — ожидаемый тип элемента в первичных данных. Используется для проверки / приведения типа.
Если тип элемента в первичных данных не соответствует указанному, данные элемента загружены не будут.
Если выбрать тип элемента аналогичный типу первичных данных (пример: «JSON-json»), то данные элемента будут загружены в оригинальном формате. Таким образом, можно загружать целиком блоки данных, например массив «JSON» можно поместить в одну колонку таблицы с типом «text» или «jsonb». Если тип поля таблицы и тип поля элемента отличаются, будет выполнена попытка приведения типа элемент к типу поля. В ситуациях когда приведение не очевидно, есть варианты для таких типов, например: «Дата строкой (ISO)» подсказывает что данные имеют строковой тип, но представляют собой дату в ISO-формате. - «!» (6) — флаг необязательного элемента. Необязательным является такой элемент, данные из которого не нужны сами по себе, а только совместно с данными обязательных элементов. Следовательно, если данных в обязательных элементах не окажется, не обязательные загружены не будут.
- «По умолчанию» (7) — значение по умолчанию для колонки таблицы. Используется если элемент в данных отсутствует, не содержит значение, или не может быть приведён к типу данных колонки таблицы.
- «Набор» (1) — произвольное имя, используется для объединения отдельных строк правила в набор. Наборов может быть несколько. Все наборы описывают общую структуру таблицы приёмника, но содержат разные пути к элементам. Позволяет в одну таблицу загружать строки, полученные из разных областей первичных данных.
Общие свойства правила
- «Тип данных» — тип первичных данных, требуется для выбора алгоритма при разборе данных по правилу.
- «Кодировка» — позволяет точно указать кодировку элементов с типом «текст» в первичных данных.
Конструкторы правил — инструменты для создания правил на основании образца первичных данных.
Открыть конструктор с пустым правилом возможно из формы списка справочника «Правила разбора данных» используя кнопку:

Из формы элемента справочника «Правила разбора данных» можно открыть в конструкторе конкретное правило используя кнопку:

3.3.2.1 - Конструктор правил разбора JSON
Конструктор правил выборки позволяет создавать правила выгрузки на основании имеющегося образца с данными в формате «JSON», а также просматривать данные в формате «JSON».
Конструктор умеет собирать статистику по повторяющимся структурам в данных «JSON». Используется это для прогнозирования формата данных и размерностей полей таблицы приёмника, а также визуальной оценки заполняемости полей данными.
Ключевые понятия
-
«Дерево данных» — структура данных свойственная таким типам данных как «JSON», «XML». В такой структуре каждый элемент может находится в отношениях родитель/подчинённый к другим элементам структуры.
-
«Узел дерева» — синоним элемента структуры дерева.
-
«Корень (дерева данных)» — первый узел в иерархии подчинённости дерева данных обозначается как «$».
-
«Путь элемента» — последовательность имен или индексов узлов от корня дерева до указанного элемента (включительно).
Например:$.ServiceResponses[0].application.details.accident[0].accident_date. -
«Точка итерации» — элемент дерева, подчиненные элементы которого имеют одинаковую структуру или тип данных. Обозначается как: «<ИмяЭлемента>[<Параметры среза>]».
-
«Параметры среза» — параметры описывающие какие именно подчиненные элементы участвуют в выборке.
Для типа данных «Объект» допустимо указание параметров среза только:- [
*] — все элементы.
Для типа данных «Массив»: - [
*] — все элементы; - [
0,1,2,3] — элементы с индексами 0, 1, 2, 3; - [
20:100] — (диапазон) элементы с индексами от 20 до 100; - [
20:100,200:300] — (диапазон) элементы с индексами от 20 до 100 и от 200 до 300; - [
20:-1] — (диапазон) элементы от 20 до последнего; - [
-1] — последний элемент.
Все диапазоны указываются включительно (содержат в том числе и граничные элементы)
- [
-
«Путь итерации» — последовательность имен или индексов узлов от корня дерева до крайней точки итерации с указанием параметров среза точек итерации.
Например:$.ServiceResponses[-].application.details.accident[0:5]. -
«Итерационный путь элемента» — последовательность имен или индексов узлов от корня дерева до указанного элемента (включительно), с указанием параметров среза точек итерации.
Например:$.ServiceResponses[-].application.details.accident[0:5] .accident_date. -
«Правила разбора данных» — совокупность путей до элементов и / или итерационных путей элементов участвующих в выборке, с указанием сопутствующих параметров (типы данных, имена полей и т.д.).
-
«Набор правил» — совокупность путей до элементов и / или итерационных путей элементов участвующих в выборке, относящихся к одному пути итерации.
-
«Распределённый элемент» — элемент, присутствующий в разных ветвях дерева данных, но имеющий для всех экземпляров одинаковый итерационный путь элемента.
-
«Статистика элемента» — расчётные показатели распределённого элемента, такие как:
- тип данных;
- % в наличии;
- % Null;
- % пустых;
- минимальное и максимальное значение;
- рекомендуемая длина и точность поля таблицы приёмника для элемента.
-
«Псевдоэлемент дерева» — элемент отображаемого дерева данных, не имеющий под собой конкретной основы в данных. Служит для настройки или асоциации с текущим (на момент выборки) элементом. Например элементы отображающие параметры среза для точки итерации, или элементы означающие имя / индекс текущего (на момент выборки) элемента.
Диалог конструктора
Диалог конструктора имеет две рабочие области (область данных и облать правил) и панель с кнопками служебных функций.
При открытии конструктора для редактирования правила, область данных будет скрыта, а область правила показана. При отрытии конструктора для просмотра данных, наоборот область правила будет скрыта, а область данных показана. Если конструктор открывается для создания / редактирования правила, но с передачей в него данных, обе область быдут показаны.
Однако вы в любой момент можете включить / выключить видимость нужных вам областей при помощи кнопок на панели функций:


Область данных
Область данных служит для отображения загруженных данных.
Просмотр данных возможен как в виде дерева, так и в виде текста. Снизу расположены вкладки «Данные (дерево)» и «Данные (текст)», перемещаясь по которым можно изменять способ отображения (дерево или текст).
Отображение в виде дерева позволяет только просматривать структуру данных. Текст же можно редактировать.
Дерево имеет два режима просмотра: режим просмотра значений элементов и режим просмотра статистики по значениям распределённых элементов.

Область правил
Область правил содержит коллекцию правил выборки элементов и описание структуры полей таблицы приёмника.

Панель служебных функций
Позволяет:
- выполнять выборку данных из предварительно загруженных «JSON»-данных;
- управлять праметрами выборки;
- загружать «JSON»-данные;
- выбирать кодировку элементов «JSON» текстового типа;
- устанавливать значение предела итераций для области просмотра данных;
- управлять видимостью Области данных;
- управлять видимостью Области правил;
- отслеживать текущие процессы конструктора (отображается в правом верхнем углу);
- переключать режим отображения дерева данных (статистика / значения).

Представленные функции
«Загрузить JSON» — позволяет загрузить JSON данные. После загрузки данные будут доступны для просмотра в Области данных.

«Кодировка» — позволяет явно указать какую кодировку нужно использовать при выборки данных текстового типа.
Автоопределение будет срабатывать только при наличии в загруженных данных Byte Order Mark (BOM).

«Предел итераций» — позволяет ограничить количество элементов отображающихся в узле дерева данных выбранным значением.

Также влияет на количество элементов участвующих в расчёте статистики, ограничивая его выбранным значением для каждого узла (точки) итерации (например для значения в 100 элементов при 2 точках итерации (в пути до элемента) фактическое количество будет равно 100 - 100 = 10 000).
Цель данного ограничителя — снизить нагрузку на сервер и тем самым сократить временные задержки в реакции интерфейса пользователя, при разворачивании дерева данных в области данных конструктора.
Если необходимо расчитать статистику максимально точно, целесобразно увеличить значение до максимально необходимого, что конечно приведёт к увеличению задержки при разворачивании узлов дерева.
Предел итераций влияет только на отображаемые данные.
На результат извлечения данных предел итераций никак не виляет.
«Видимость области данных» — включает / выключает отображение области данных конструктора:
«Видимость области правил» — включает / выключает отображение области правил конструктора:
«Выбрать данные» — запускает процесс извлечения данных по правилу. По окончании процесса откроется окно просмотра выбранных по правилу данных:

«Параметры выборки» — позволяет указать дополнительные параметры выборки.
Доступные параметры:
- «Использовать null как значение по умолчанию» — при активизации данного параметра алгоритм выборки будет игнорировать настройки правила в части установленных значений по умолчанию, значения отсутствующих элементов будут загружены как null-значения.
Полезно для визуального анализа заполняемости таблицы приёмника данными.
Не влияет на последующее использование правила.

«Выбор режима дерева данных» — позволяет переключать дерево данных (в области данных) между режимами просмотра данных и просмотра статистики.
Состояние выключателя:
- включен — дерево отображает статистику;
- выключен — дерево отображает значения.

- «Текущий путь итерации» — путь итерации текущего набора правил.
Текущий путь итерации имеет два режима отображения. Режим отображения зависит от режима отображения дерева данных:
- «Режим отображения дерева данных» — показывать статистику:

Если текущий путь итерации не умещается целиком на экране, при помощи кнопок:

можно сдвигать элементы пути вправо/влево для обзора всех элементов.
- «Режим отображения дерева данных» — показывать значения:

- «Сбросить текущий путь итерации» — позволяет сбросить текущий путь итерации в одно действие.
Доступна если список правил пуст или область правила откреплена от области данных.

Область данных
Область данных служит для отображение загруженных ранее данных.
Отображение возможно в виде дерева и в виде текста.
Дерево данных может отображать данные в режиме статистики и в режиме значений.
Дерево данных: режим статистики

Описание полей представлено ниже.

-
«Имя» — имя элемента дерева данных или имя псевдоэлемента или параметры среза в виде строки.
-
«Признак точки итерации» — обозначает узлы выбранные в качестве точек итерации:

- «Тип» — тип «JSON»-элемента. Если элементы, будучи распределёнными, имеют разные типы то они будут перечислены через запятую, а поле окрасится красным цветом. Данные из полей смешанного типа допускается собирать только в виде JSON данных (см. настроку правила).
- «Всего %» — процент значений элемента в выборке по текущему правилу от общего числа строк в результате выборки.
- «Null %» — процент отсутствующих значений элемента в выборке по текущему правилу от общего числа строк в результате выборки. Сюда входят как элементы со значениям null, так и элементы отсутствующие, но ожидаемые. Элемент является ожидаемым если в некоторых узлах он присутствует, а в других нет.
- «Пустые %» — процент пустых значений элемента в выборке от общего числа строк в результате выборки. К пустым относятся пустые строки для текстового типа элемента и нулевое значение элемента для числового типа элемента.
- «Мин.» — минимальное значение элемента в выборке. Для числового типа элемента — это минимальное числовое значение элемента. Для текстового типа элемента — это минимальная длина строки. По типам данных элемента отличным от текстового или числового данный показатель не рассчитывается.
- «Макс.» — максимальное значение элемента в выборке. Для числового типа элемента — это максимальное числовое значение элемента. Для текстового типа элемента — это максимальная длина строки. По типам данных элемента отличным от текстового или числового данный показатель не рассчитывается.
- «Длина» — рекомендуемая для поля таблицы приёмника длина. Для строкового типа — длина строки. Для числового — максимальное количество цифр в числе. Например, для числа 91234567.89 длина — 10. Этот показатель идентичен параметру поля таблицы СУБД
character_maximum_lengthиprecisionсоответственно для строк и чисел. Подсчитывается только для числового и текстового типов элемента. - «Точность» — рекомендуемая для поля таблицы приёмника размер дробной части. Этот показатель идентичен параметру поля таблицы СУБД
scale. Подсчитывается только для числового типа элемента.
При наличии точек итерации (относительно которых нижележащие структуры повторяются) в пути к элементу, расчёт показателей статистики происходит с помощью анализа значений повторяющихся структур. В отсутствии точек итерации статистические показатели расчитываются для единичных элементов.
Дерево данных: режим значений

Описание полей представлен ниже.

-
«Имя» — имя элемента дерева данных или имя псевдоэлемента или параметры среза в виде строки.
-
«Признак точки итерации» — обозначает узлы выбранные в качестве точек итерации:
- «Тип» — тип «JSON»-элемента.
- «Значение» — поле отображающее значение элементов чиcловых и булевых типов, а также null.
- «Строковое значение» — поле отображающее значение элементов строкового типа.
Разделение на разные колонки отображаемых значений по типам сделано для улучшения читаемости данных в таблице-дереве.
В режиме дерева данных «просмотр значений» функции по работе с точками итерации не доступны (выбор/отмена выбора узла в качестве точки итерации, настройка параметров среза).
Панель функций дерева данных



Позволяет выбрать элемент дерева в качестве точки итерации или отменить выбор элемента в качестве точки итерации. При отмене выбора элемента в качестве точки итерации все нижележащие точки итерации будут также отменены.
Чтобы выбрать элемент в качестве точки итерации его необходимо предварительно развернуть. В момент разворачивания будет прочитана структура нижележащих элементов и проведена оценка возможности использования данного узла в качестве точки итерации. Оценка проводится на предмет совпадения типов данных элементов. Типы должны быть одинаковыми и не содержать смешанные типы.
Доступна только в режиме просмотра статистики.

Кнопка на рисунке выше открывает диалог настройки параметров среза точки итерации. Доступна только для настройки параметров среза элемента типа Массив.
Для настройки параметров среза, необходимо предварительно развернуть узел дерева выбранного в качестве точки итерации. В списке элементов выбрать псевдоэлемент с изображением:

Кнопка функции станет активной.
Доступна только в режиме просмотра статистики.

Кнопка на рисунке выше позволяет посмотреть все значения распределённого элемента. Предварительно нужный элемент необходимо выбрать в дереве данных.
Отображается только в режиме просмотра статистики.

Кнопка на рисунке выше включает / отключает сбор и отображение статистики в режиме просмотра статистики.
Если объём данных большой, а посмотреть нужно только структуру дерева, можно использовать эту функцию и отключить сбор статистики. Вернуться к сбору статистики можно в любой момент.
Отображается только в режиме просмотра статистики.

Кнопка на рисунке выше отображает путь до текущего выбранного элемента дерева.
Псевдоэлементы дерева данных
При выборе элемента дерева в качестве точки итерации элемент сворачивается, а в его содержимом появляется два псевдоэлемента:
«Параметры среза» — отображает текущую настройку среза в виде строки вида “[0:5, 10, 20:-1]” или “[-]”. Содержит в качестве дочерних элементов свернутую структуру повторяющихся элементов. По двойному нажатию открывает диалог настройки параметров среза. В контекстном меню элемента присутствует команда «Параметры среза», которая также открывает диалог настройки параметров среза.

«Текущее положение» — имя элемента зависит от типа радителя, для массива — «Индекс элемента», для объекта «Имя элемента». Используется для формирования правила выборки имени / индекса текущего элемента, методом перетаскивания в область правила. Если в результатах выборки нужно получать не только данные элементов, но и их имена/индексы, используйте этот элемент для формирования соответствующей строки правила.
Контекстное меню дерева данных
Отображается по правому клику мыши на элементе дерева данных.
Функциональность аналогична «Панели функций дерева данных».

Диалог настройки параметров среза
Отображает настройки параметров среза выбранного элемента.
Каждая строка задаёт диапазон значениий или единичный элемент. Единичные элементы указываются ввиде одинаковых индексов для начала и конца диапазона. Нумерация индексов начинается с нуля. Если необходимо указать элементы с конца, необходимо указывать отрицательные знаяения:
- «-1» — последний элемент;
- «-2» — предпоследний и т.д.
Внесённые изменения применятся при закрытии окна диалога настроек параметров среза.
Если в списке правила присутствуют элементы содержащие в пути настраиваемую точку итерации, их пути автоматически скорректируются под новые параметры среза.

Просмотр данных в виде текста
В нижнем левом углу присутствуют вкладки:

перемещаясь по которым, можно изменять способ отображения данных (дерево или текст). Дерево позволяет только просматривать структуру данных JSON. Текст можно редактировать. Окно просмотра данных в виде текста находится на вкладке «Данные (текст)».

В окне просмотра текста имеется кнопка команды позволяющая отформатировать текст для улучшения читаемости.

Область правила
Область правил содержит коллекцию строк с правилами выбора значений и панель с функциями для работы с коллекцией.
Коллекция строк с правилами выбора значений

Значения колонок таблицы коллекции:

- «Имя поля» — имя колонки таблицы в которую следует поместить значение из первичных данных.
- «Тип поля» — тип данных колонки таблицы
- «Путь к элементу» — описание пути к элементу внутри первичных данных в формате «JSONPath».
- «Тип элемента» — ожидаемый тип элемента в первичных данных. Используется для проверки/приведения типа. Если тип элемента в первичных данных не соответствует указанному, данные элемента загружены не будут. Если выбрать тип элемента аналогичный типу первичных данных (пример: «JSON-JSON»), то данные элемента будут загружены в оригинальном формате. Таким образом можно загружать целиком блоки данных, например массив «JSON» можно поместить в одну колонку таблицы с типом text или «JSONb». Если тип поля таблицы и тип поля элемента отличаются, будет выполнена попытка приведения типа элемент к типу поля. В ситуациях когда приведение не очевидно, есть варианты для таких типов, например: «Дата строкой (ISO)» подсказывает, что данные имеют строковой тип, но представляют собой дату в ISO формате.
- «!» — флаг необязательного элемента. Необязательным является такой элемент, данные из которого не нужны сами по себе, а только совместно с данными обязательных элементов. Таким образом, если данных в обязательных элементах не окажется, не обязательные загружены не будут.
- «По умолчанию» — значение по умолчанию для колонки таблицы. Используется если элемент в данных отсутствует, не содержит значение или не может быть приведён к типу данных колонки таблицы.
Если данные были загружены в конструктор, но отображение панели данных не включено, то будет показана ещё одна колонка:

В этой колонке отображаются кнопки:

по нажатии на которые окрывется панель данных (панель правил при этом скрывается), что позволяет выбрать в дереве данных целевой элемент для строки правила. Выбор осуществляется двойным нажатием кнопки мыши. Такой вариан использования подойдёт, если разрешение монитора не позволяет разместить панель данных и панель правила одновременно на экране.
Внизу коллекции строк находятся вкладки наборов:

Наборы позволяют загружать в одну таблицу строки, полученные из разных областей первичных данных. Все наборы описывают общую структуру таблицы приёмника, но содержат разные пути к элементам. Для добавления / удаления наборов используются кнопки на панели функций.
Панель функций

На панели функций представлены следующие функции для работы с коллекцией.

Перемещение строк коллекции по списку. При этом меняется очерёдность в которой колонки будут описаны при создании таблицы.

Добавляет новую строку правила загрузки элемента в коллекцию.

Сортирует строки коллекции по имени колонки (по возрастанию).

Очищает пути к элементам у всех строк текущего набора.

Полностью очищает коллекцию правил

Заполняет значения по умолчанию типовыми значениями. Заполняются только те позиции в коллекции, значение по умолчанию для которых выставлено в Null.

Открывает коллекцию как таблицу в отдельном окне. Эта функция позволяет сохранить правила в табличный документ (файл), или перенести коллекцию (через буфер обмена) в другое правило или в другой конструктор. Например из ETL тестового контура в рабочий. Таблица доступна для редактирования. Все внесённые изменения отразятся на коллекции правил после закрытия окна с таблицей.

Сохраняет текущее правило в справочник правил разбора данных. Если правило новое, то будет предложено ввести имя. Если правило модифицируется пользователем, то данная кнопка подсвечивается розовым контуром, для сигнализации о необходимости сохранения изменений.

Поле с именем текущего правила разбора данных. При необходимости, правило можно поменять через стандартный диалог выбора из выпадающего списка.

Открепляет / прикрепляет правила к дереву данных. Дерево данных сворачивается согласно пути итерации текущего набора. При модификации пути итерации будет происходить автоматическая синхронизация путей правил с путём итерации. Если необходимо временно отключить автоматическую синхронизацию, то с помощью данной функции это можно сделать. При это откреплённое правило будет отображать свой собственный путь итерации соответствующий правилу

Кнопка:

служит для ручной синхронизации итерационного пути дерева с итерационным путём правила.

Меняет местами панель данных и панель правила.

Показывает / скрывает колонку значений по умолчанию.

Добавляет новый набор.

Позволяет задать произвольное имя текущего набора.

Удаляет текущий набор.
Добавление элементов в коллекцию строк правила
Добавить новый элемент в коллекцию можно:
- перетащив его из дерева данных в область правила. При этом, если это единичный элемент будет создана одна строка в правиле. Если элемент содержит дочерние элементы и развернут, то в правило будут добавлены строки соответствующие дочерним элементам с типами строка, число, булево. Если элемент не развёрнут, то он добавится в виде одной строки с типом данных JSON, что позволит загрузить всю ветвь в виде строки в ячейку таблицы;
- перетащив его из дерева данных в область правила на поле «Путь к элементу» с незаполненым путем. Имя поля таблицы и тип поля останутся без изменения, а путь и тип элемента заполнятся значениями перетаскиваемого элемента;
- предварительно выдилив в дереве данных несколько элементов, перетащить их на область правила. Добавится столько строк правила, сколько было выделено элементов типа строка, число, булево;
- при отключенной панели данных двойным щелчком на поле с изображением:
открыть область данных и в ней выбрать (двойным щелчком) целевой элемент дерева.
3.4 - Настройка выгрузки данных
3.4.1 - Настройка правил выгрузки данных
Создать новый / отредактировать существующий документ «Установить правила выгрузки».
Заполнение:
- «Правило выгрузки» — выбрать из справочника, при необходимости создать новое;
- «Тип правила» («Рабочее», «Разовое» и т.п.) — информационное поле для удобства поиска правил с определенным типом / статусом;
- «Тип приемника» — выбрать из вариантов:
- «Таблица произвольной СУБД (ADO)» — не требует доп. настроек, используется по умолчанию;
- «Таблица внешнего источника данных» — требует настройки внешнего источника в конфигураторе 1С;
- «Вид правила» — от вида правила зависит способ получения данных.
Виды правил выгрузки: - «Вкладка «SQL»:
- база данных (см. рисунок ниже, 1) — выбрать из справочника баз данных базу-приемник;
- таблица выгрузки (см. рисунок ниже, 2) — таблица-приемник. Эта таблица может уже существовать в базе-приемнике или можно ввести название еще несуществующей таблицы, а в последствии, когда ее поля будут описаны на вкладке «SQL» (см. рисунок ниже, 4) создать ее при помощи кнопки «Создать таблицу в SQL» (см. рисунок ниже, 3);
- «Описание полей запроса и полей таблицы-приемника. Описывать поля запроса и поля выгрузки можно после соответствующих настроек для вида правила (см. ниже). Заполнять описание полей не обязательно, если предполагается получать данные разово в отчет или в файл;
- версионирование для таблицы-приемника включается отдельной процедурой;

- вкладка «Обработчики» — используется для настройки постобработки данных в особых случаях. Например, для преобразования / форматирования полученных значений; заполнения геокоординат по адресу и т.д.;
- вкладка «Служебные поля» — используется для настройки аудиторских полей. После выбора режима, при создании таблицы поля будут добавлены в нее вместе с полями на вкладке SQL. По умолчанию используется режим — основной;
- «Провести документ» — кнопка «Провести» / «Провести и закрыть». При проведении происходит запись («Период», «Регистратор», «Правило») в регистр «Правила выгрузки». Этот регистр служит для хранения истории документов-регистраторов для конкретного правила и получения актуального правила и актуального регистратора, что используется, например, в «Обработке выгрузки данных».
Настройка собственно правил получения данных зависит от вида правила выгрузки.
3.4.1.1 - Настройка служебных полей
В документе «Настройка правил выгрузки» перейти на вкладку «Служебные поля» и выбрать из выпадающего списка режим заполнения служебных полей:

При необходимости можно отредактировать — нажать:

или создать новый режим — нажать:

в выпадающем списке:

При создании добавить нужные поля. Для вывода различных значений можно использовать поле «ATTRIBUTE» (по умолчанию не содержит значения). Или добавить новое поле:

Значения можно выбрать из готового списка реквизитов справочника «Источники данных»:

или использовать выражения в контексте 1C, для вывода определенного значения:

Далее сохранить изменения и закрыть форму, нажав кнопку «Записать и закрыть».
Примечание. При редактировании режима изменения повлияют на все правила, где он используется.
3.4.1.2 - Настройка правила вида «Запрос»

Перечень дествий описан ниже.
Заполнить «Текст запроса» на языке 1C или SQL. Заполнить «Параметры запроса» (типичным параметром является период выгрузки, в этом случае установить параметры «ДатаНачала» и «ДатаКонца»). Для добавления параметра необходимо перейти на вкладку «Настройка параметров» и нажать ссылку «Настроить параметры»:

Откроется интерфейс, в котором возможно:

- заполнить наименования параметров из запроса по кнопке «Заполнить из запроса» (см. рисунок выше, 1);
- добавить строки параметров по кнопке «Добавить» (см. рисунок выше, 2) и заполнить поля: «Имя параметра», «Номер пакета / этапа» (если пакет / этап один, то выбрать «=1»), «Значение параметра» (см. рисунок выше, 3).
Вместо значения параметра возможно, проставив соответствующий флаг, заполнить поле «Выражение для вычисления параметра» на языке 1С (см. рисунок выше, 4). Результат расчета выражения возможно проконтролировать в поле «Значение» (см. рисунок выше, 5).
При необходимости следует запускать запрос более 1 раза с разными значениями параметров. Возможно заполнить значения параметров, объединенных в наборы / пакеты, заполняя для строк параметров объединяющий признак «Номер пакета». Это необходимо в случае, если из-за особенностей запроса его можно запускать, например, только помесячно, но требуется получить данные за несколько (N) месяцев — при этом запрос будет запускаться N раз с периодом 1 месяц.
Для параметров типа «дата / дата-время» существует помощник заполнения наборов / пакетов, запускаемый по кнопке «Заполнить наборы параметров» (см. рисунок выше, 6).
В форме необходимо ввести период дат «с … по», периодичность (день / неделя / месяц / квартал), смещение (время в секундах, которое будет добавлено к параметру даты) и вид периода (начало / конец периода) и нажать кнопку «Заполнить»:

Результатом будут заполненные строки параметров для пакетов получения данных:

3.4.1.3 - Настройка правила вида «Произвольный код»
Такие правила используются для источников отличных от баз данных SQL / 1С, например, получения данных из web-сервисов и разрабатываются квалифицированным разработчиком 1С.
Требуется заполнить вкладки:
- «Обработчик получения списка полей таблицы»;
- «Обработчик получения данных»;
- «Обработчик получения списка параметров»;
- «Данные модуля»;
- «Настройка параметров».

3.4.1.4 - Настройка правила вида «Загрузка из файла»
При загрузке из файла необходимо настроить правила работы с данным файлом. Для хранения этих правил создан справочник «Настройки загрузки из файла».
Примечание. Для получения данных через «ADO-ODBC» необходимо использовать правила выгрузки вида «Запрос».

Установка настроек загрузки из файла
Примечание. «Настройки загрузки из файла» удобно формировать с помощью обработок «Загрузка файла в БД» и «Загрузка файла в БД (мастер настройки)», которые подробно описаны в п. 14.1.
Открыть справочник можно из формы документа «Установить правила выгрузки», либо через меню «Главное» / «Настройки» / «Настройки загрузки из файла».

Необходимо создать новый элемент. В новом элементе нужно заполнить название настройки и следующие вкладки:
- «Основная» — заполнить путь к файлу и список колонок, содержащихся в файле, название выходного поля, номер колонки в файле и тип данных.

- «Правила исключения строк» — можно настроить правила отбора строк, которые не должны загружаться.

- «Настройки» — установить настройки куда выгружать данные и режим записи, настройки получения данных из файла.

- Дополнительно можно заполнить описание на вкладке «Описание» и использовать обработчики — специальные скрипты, которые можно внести в поле на вкладке «Обработчики».
3.4.1.5 - Настройка правила вида «Схема источника (СКД)» для 1С-источника
В качестве «Схемы источника» используется настройка отчета через систему компоновки данных (СКД) в базе определенной конфигурации 1С. Такой способ получения данных предполагает управление схемой СКД источника из Modus: ETL, передавая параметры и правила компоновки данных. Способ управления схемой СКД отчета в источнике используется, когда необходимые данные проблематично получить 1С-запросами, например, для среднесписочной численности работников.
Настройки отчета источника сохраняются в специальном справочнике «Отчеты конфигураций». Открыть справочник можно из формы документа «Установить правила выгрузки» (размещение: «Начальная страница» / «Сбор данных» / «Установка правил выгрузки»).
Создайте новый документ «Установить правила выгрузки». Выберите вид правила «Схема источника (СКД)».
Раскройте раздел «Настройки схемы компоновки данных». И в выпадающем списке «Схема источника» нажмите «Показать все» и выберите нужный отчет:

Откроется справочник «Схемы компоновки данных источников». Для создания нового элемента нажмите кнопку «Создать»:

Настройка элемента справочника «Схемы компоновки данных источников»
При настройке элемента справочника «Схемы компоновки данных источников» используются настройки из базы-источника. Для получения этих настроек, в форме нового элемента необходимо выбрать «Расположение схемы» и нажать кнопку «Импортировать из источника»:

Сделайте необходимые установки в мастере для импорта отчета:
- выберите базу-источник;
- выберите тип метаданных («Отчет» или «Справочники»);
- выберите требуемый объект для импорта (настроенный на СКД отчет);
- в открывшемся списке схем отчета, настроенного на СКД, выберите схему отчета для импорта (если нужно получать данные по нескольким схемам, для каждой схемы настройте отдельный элемент справочника «Схемы компоновки данных источников»);
- выберите вариант настроенного на СКД отчета, (если нужно получать данные по нескольким вариантам отчета, для каждого варианта настройте отдельный элемент справочника «Схемы компоновки данных источников»).

В результате работы мастера по импорту настроек отчета из СКД:
- будет автоматически заполнено «Наименование элемента справочника», оно компонуется из названия базы-источника, названия отчета и названия варианта отчета. Таким образом легко идентифицировать импортированные настройки;
- будут загружены все настройки из выбранного отчета, выбранной схемы и выбранного варианта на закладах «Отбор», «Параметры», «Порядок», «Условное форматирование», «Поля», «Настройки»;
- будут заполнены информационные поля на закладке «Дополнительно»:

Если в исходном отчете дополнительно к схеме есть настройки в виде программного кода, требуется установить флаг «Отчет требует инициализации» на закладке «Дополнительно». Сама инициализация, т.е. получение и запуск программного кода, будет происходить при исполнении отчета (получении данных).
В импортированные настройки можно вносить изменения: добавлять и группировать поля. При добавлении поля можно использовать вложенные данные до второго уровня вложенности. Например, «Организация.ИНН».
Сохраните элемент справочника и выберите его из списка в документе «Установка правил выгрузки».
Настройка правила на основе схемы источника
Настройка схемы компоновки данных:
- на вкладке «Страница основная» выберите элемент справочника «Схема источника»;
- набор параметров на вкладке «Настройка параметров» заполнится автоматически из настроек схемы отчета в выбранном элементе. Если в исходном варианте отчета на СКД в базе данных были внесены изменения в параметры, можно получить эти изменения при помощи кнопки «Обновить отчет» на вкладке «Страница основная».
Вкладка «SQL»:
- поля запроса и выходные поля таблицы заполнены автоматически из настроек выбранного элемента справочника «Схемы компоновки данных источников»;
- требуется заполнить типы полей.
На вкладке «Настройки представления полей» требуется указать, поля типа «ссылка» для автоматической генерации представления. При получении данных, ссылки будут заменены на строковые значения полей.
Остальные настройки аналогичны настройкам правила вида «Запрос».
Запуск правила вида «Схема источника» может быть только в автоматическом режиме через механизм «Состав выгрузки». Получить данные через сервис «Выгрузка в отчет» невозможно.
Ограничения при использовании СКД
Расположение схемы «База-источник»
Нельзя использовать СКД, у которых:
- в настройках используется кросс-таблица;
- в параметрах используются не примитивные типы (ссылки, массивы ссылок и т.п.);
- есть набор данных — объект;
- запросы в наборах данных требуют программной модификации / перезаполнения.
Расположение схемы «Локально в хранилище ETL»
Здесь действуют те же ограничения, что и в пп. 6.6.3.1, но так как схему можно изменить (создать с нуля), то эти ограничения можно обойти, например, вместо ссылок использовать код или наименование.
Для любых схем
Схему в ETL можно настраивать только в толстом клиенте.
Нельзя получить данные с видом правила «Схема источника» через агента ETL.
Особенности формирования схемы СКД:
Параметры для виртуальных таблиц следует указывать в фигурных скобках:
Период— для таблиц «СрезПоследних», «СрезПервых», «Остатки»;НачалоПериода,КонецПериода— для таблиц «Обороты», «ОстаткиИОбороты».
Например:
ВЫБРАТЬ ИЗ
РегистрСведений.КурсыВалют.СрезПоследних({&ПараметрДата},
Валюта = &ПараметрВалюта)
В настройках схемы СКД следует, в общем случае, отключить вывод общих итогов по горизонтали и по вертикали.

3.4.2 - Настройка состава выгрузки данных
Для настройки связи правил выгрузки с набором источников данных, а также для уточнения параметров выгрузки и для возможности настраивать расписание получения данных (не обязательно) служит объект (справочник) «Составы выгрузок».
Размещение: через меню «Главная» / «Настройки» / «Составы выгрузок» или с начальной страницы:
Для создания нового элемента нажать кнопку «Создать» (рисунок выше, 1).
Возможна настройка запуска получения данных по расписанию и вручную. Для запуска получения данных с настроенным правилом выгрузки и набором данных (состав выгрузки) вручную, нужно выбрать «Состав выгрузки» и нажать кнопку «Направить задание в очередь» (рисунок выше, 2).
Недавно запущенные составы выгрузок можно увидеть в нижней части формы «Составы выгрузок» (рисунок выше, 3).
Порядок заполнения:
- заполнить «Набор источников» и «Правила выгрузки» (см. рисунок выше, 2 и 3) – наименование выгрузки (рисунок выше, 1) заполнится автоматически из названия набора источников и правила выгрузки;
- в поле «Таблица выгрузки (из правила)» отобразится таблица, в которую по умолчанию записываются данные. Потягивается из выбранного правила выгрузки (рисунок выше, 4).
- в поле «Таблица выгрузки (альтернативная)» можно ввести альтернативную таблицу, в которую требуется получить данные, вместо таблицы по умолчанию. Таблица должна быть в БД (рисунок выше, 5).
- установить режим записи данных (см. рисунок выше, 6):
- Добавить – дополнить исходную таблицу новыми данными;
- Очистить и добавить – очистить исходную таблицу и добавить туда полученные данные;
- Скопировать и добавить – скопировать исходную таблицу (у таблицы-копии добавится к названию исходной таблицы суффикс, содержащий дату и время обновления данных), после этого очистить таблицу и добавить туда полученные данные;
- установить флаг «Делить на потоки по параметрам» (см. рисунок выше, 7), если требуется разделить получение данных на потоки, зависящие от пакетов (наборов) параметров. Не используется при получении данных правилом выгрузки вида «Загрузка из файла».
- установить требуемые параметры и пакеты параметров (см. рисунок выше, 8).
1. Параметры для получения данных
Для настройки параметров в «Составе выгрузки» переходим по ссылке «Настроить параметры» («Изменить параметры») (см. рисунок выше, 8):
- по умолчанию набор и значения параметров заполняются из выбранного «Правила выгрузки», значения параметров в «Составе выгрузки» можно изменить;
- если в правиле выгрузки требуется несколько параметров, то нужно добавить и заполнить их;
- если необходимо использовать несколько запусков получения данных и соответственно несколько групп параметров (например, несколько раз запускать получение данных за разные месяцы), то каждой группе назначаем номер запуска (вручную, для каждого параметра из группы) (см. рисунок ниже, 1);
- параметры можно задавать не только константой (см. рисунок ниже, 2) , но и вычисляемым выражением (см. рисунок ниже, 3), в этом случае проверить значение выражения можно в специальном поле. Для этого нужно установить курсор на выражение в параметре и его значение отобразиться в поле «Значение» (см. рисунок ниже, 6). Также можно вручную написать текст для вычисления выражения в поле «Выражение для вычисления параметра» (см. рисунок ниже, 4) и нажать на кнопку «=» (см. рисунок ниже, 5);
- пока не включен флаг у выражения, оно не будет включаться в запрос получения данных, в этом случае будет использовано значение параметра в виде константы.
Рисунок 4. Вычисление выражения.
Параметры тип дата можно заполнить, используя функции для работы с датами:
ТекущаяДата()— текущая (системная) дата;ДобавитьМесяц(<Дата>, <ЧислоМесяцев>)— добавляет (или вычитает) к указанной дате заданное число месяцев. Если<ЧислоМесяцев>принимает отрицательное значение, то число месяцев вычитается;НачалоГода(<Дата>)— определяет дату и время начала года для указанной даты;НачалоКвартала(<Дата>)— определяет дату и время начала квартала для указанной даты;НачалоМесяца(<Дата>)— определяет дату и время начала месяца для указанной даты;НачалоНедели(<Дата>)— определяет дату и время начала недели для указанной даты;НачалоДня(<Дата>)— определяет дату и время начала дня для указанной даты;НачалоЧаса(<Дата>)— определяет дату и время начала часа для указанной даты;НачалоМинуты(<Дата>)— определяет дату и время начала минуты для указанной даты;КонецГода(<Дата>)— определяет дату и время конца года для указанной даты;КонецКвартала(<Дата>)— определяет дату и время конца квартала для указанной даты;КонецМесяца(<Дата>)— определяет дату и время конца месяца для указанной даты;КонецНедели(<Дата>)— определяет дату и время конца недели для указанной даты;КонецДня(<Дата>)— определяет дату и время конца дня для указанной даты;КонецЧаса(<Дата>)— определяет дату и время конца часа для указанной даты;КонецМинуты(<Дата>)— определяет дату и время конца минуты для указанной даты.
2. Обработчики
Когда требуется дополнительно обработать данные или скорректировать параметры выполнения (до того как будет получен результат и записан в таблицу хранилища), используются обработчики — специальные скрипты, которые можно внести в поле на вкладке «Обработчики»:
- «Перед постановкой в очередь» — используется в основном для обработки данных с помощью плагинов (вид правила – «Произвольный код»), если требуется дополнительная обработка данных до записи их в таблицу хранилища;
- «После получения параметров» — для переопределения параметров и шаблонов запроса. Может использоваться, например, для инкрементального получения данных с даты последнего обновления — с помощью произвольного кода 1С возможно устанавливать параметр в составе выгрузки в значение, с учетом даты обновления данных, которое сохранено в определеном поле таблицы хранилища. Подробности для разработчика описаны в разделе «Подсказка»:
3. Дополнительные настройки
Необязательные настройки вынесены на закладку «Дополнительно».
Для установки автоматического запуска получения данных используется «Расписание запуска регламентного задания» (см. рисунок выше, 1). Как настроить расписание, подробно описывается в этой статье.
Дополнительно можно установить приоритет состава выгрузки (см. рисунок выше, 2). Приоритет учитывается в случае, когда одновременно запущены процессы получения данных через несколько составов выгрузки. Так как каждый процесс получения делится на потоки, и они работают по очереди, первым будет обрабатываться процесс с более высоким приоритетом.
Идентификатор регламентного задания (см. рисунок выше, 3) устанавливается системой автоматически и используется для отслеживания работы процессов.
Агент для получения данных (см. рисунок выше, 4) выбирается, если требуется получение данных с помощью Агента ETL.
3.4.3 - Механизм извлечения данных с использованием обработок plug-in’ов (модулей получения данных)
Для придания большей гибкости конфигурации в части механизмов получения данных, так как именно эта часть является часто изменяемой, был разработан механизм «Модулей получения данных». На низком уровне он представляет из себя «Дополнительные обработки» библиотеки стандартных подсистем 1С, которые предоставляют стандартный API для простого использования в конфигурации программного продукта.
Последовательность настройки описана ниже.
- Создать обработку для получения данных (например, используя сторонние web-сервисы).
- Добавить внешнюю обработку в список «Дополнительных обработок».


При добавлении следует особое внимание обратить на режим работы: если предполагается работать с внешними ресурсами, то режим должен быть «Не безопасный».
- Добавить обработку в качестве «Модуля получения данных».

При создании нового «Модуля получения данных», в списке «Обработок» отображаются все «Дополнительные обработки». Заполнение таблицы с информацией об обработчиках, предоставляемых Модулем, заполняется с использованием программного интерфейса (API) дополнительной обработки.

Обязательными обработчиками являются:
- «Обработчик получения данных» — вызывается при обработке очереди получения данных.
- «Обработчик получения параметров при постановке в очередь» — функция,которая формирует коллекцию параметров, в разрезе которых возможнопостроить очередь. Минимально коллекция должна быть из одного параметра, чтобы очередь могла состоять из одного элемента. Параметрами могут быть любые сущности, которые зависят не от пользователя (например, список «Организаций», по которым требуется получить информацию, или список «Видов спорта», по которым нужно получить список действующих тренеров).
Необязательными обработчиками являются:
- «Обработчик получения списка полей таблицы» — функция формирования списка типизированных поле, которые являются полями результирующей таблицы данных. В контексте запроса – это поля запроса. Поля используются для сопоставления полей источника и полей приемника в документе «Установка правил выгрузки».
- «Обработчик получения списка параметров пользователя» — функция, формирующая список параметров, которые нужно указать пользователю для корректного получения данных.
- Настроить правило выгрузки с использованием нового «Модуля получения данных». Для этого в «Виде запроса» выбираем «Произвольный код». На вкладке «Данные модуля» выбираем «Модуль получения данных».

После выбора «Модуля получения данных», автоматически будет заполнен список доступных «Идентификаторов групп обработчиков». Это строки табличной части «Модуля» для упрощенной настройки кода вызова обработчиков.

После заполнения Идентификатора будет предложено автоматически заполнить соответствующие страницы с программным кодом вызова обработчиков.


Важно! Программный код вызова обработчиков можно заполнить и вручную, механизм модулей — это лишь помощь в настройке.
Код может быть произвольным. Контекст вызова каждого обработчика можно посмотреть в «Подсказке» (символ «?» на форме).
- Настроить «Состав выгрузки» для правила (более подробно о настройке написано в п. 7).

Ниже приведен пример алгоритма работы получения данных с использованием «Модулей получения данных».
Пусть состав настроен для «Набора источников» который состоит из 6 «Источников» (здесь источник — это просто абстрактная сущность для деления данных на порции в очереди) и «Правила получения данных» по образовательным учреждениям с использованием механизма «Модуля получения данных».
- При формировании очереди вызывается обработчик «Перед постановкой в очередь» из состава выгрузки (в данном обработчике пусть получается список Идентификаторов образовательных учреждений, к примеру, список состоит из 1200 образовательных учреждений). Список из 1200 образовательных учреждений делится на 6 «Источников» и записывается очередь в разрезе Источников.
- При получении данных из очереди для каждого источника вызывается «Обработчик получения данных» из «Установки правила выгрузки данных» в контексте 200 образовательных учреждений из очереди, данные формализуются в виде таблицы значений и отдаются механизму сопоставления полей и записи в «Хранилище данных (DWH)».
3.4.4 - Настройка инкрементальной загрузки из 1С
Инкрементальная загрузка из 1С предназначена для получения измененных данных из 1С в целевое хранилище ETL. Регистрация изменений в базе источнике выполняется на узлах обмена, а в ETL выполняется получение только зарегистрированных к отправке данных. После успешного получения данных регистрация изменений очищается.
Перед настройкой база-источник должна быть подключена в ETL при помощи Адаптера ETL, а также между ETL и базой-источником должна проходить проверка соединения
Настройка на стороне источника
- Выбрать план обмена, который будет выполнять регистрацию сведений. Подробней про планы обмена можно прочитать по ссылке https://v8.1c.ru/platforma/plan-obmena/. Вам необходимо выбрать или создать такой план обмена, чтобы на нем регистрировались метаданные конфигурации, которые вы намерены получить. Можно выбирать любой план обмена, который есть в конфигурации, или создать свой при помощи доработки конфигурации или создания расширения, которое будет содержать новый план обмена.
- После выбора плана обмена, необходимо перейти в список узлов выбранного плана обмена и создать новый Узел обмена. Для каждого объекта метаданных необходимо создавать свой экземпляр узла, каждый экземпляр узла должен иметь уникальный код и наименование.
Например, необходимо загружать изменения справочника «Контрагенты» и справочника «Номенклатура», тогда для каждого справочника вам нужно создать собственный элемент узла плана обмена. - Установить код у предопределенного узла обмена «Этот узел». «Этот узел» это специальный узел обмена, который создается автоматически. Для того чтобы механизм инкрементальной загрузки работал корректно нужно указать любой код в его карточке. Проверить регистрацию на узлах можно при помощи стандартной обработки «Регистрация изменений для обмена», которая есть в типовых конфигурациях или при помощи внешней обработки https://its.1c.ru/db/metod8dev/content/5013/hdoc.
На стороне ETL
- Загрузить информацию о плане обмена. Для этого необходимо в разделе «Источники данных» выбрать источник данных, который соответствует вашей базе в его карточке, на вкладке «Дополнительные настройки» нажать «Загрузить узлы планов обмена».
- Создать новые правила выгрузки данных и в верхней части документа установить признак «Загрузка изменений по плану обмена (1С)».
- Написать запрос для получения данных. Запрос к данным должен получать только измененные данные. Для этого в языке запросов 1С есть специальная конструкция «<ИмяТаблицы.Изменения». Обращаясь к таблице изменений объекта метаданных, пользователь получает информацию о ссылках на измененные или удаленные объекты или ключи регистов сведений, по которым произошли изменения.
Например, текст запроса получения данных контрагентов имеет следующий вид:
ВЫБРАТЬ
Контрагенты.Ссылка,
Контрагенты.ИНН,
Контрагенты.КПП,
Контрагенты.Наименование,
Контрагенты.Ответственный
ИЗ
Справочник.Контрагенты КАК Контрагенты
Для получения изменений его необходимо привести в следующий вид:
ВЫБРАТЬ
Контрагенты.ИНН,
Контрагенты.КПП,
Контрагенты.Наименование,
Контрагенты.Ответственный,
КонтрагентыИзменения.Ссылка КАК Ссылка
ИЗ
Справочник.Контрагенты.Изменения КАК КонтрагентыИзменения
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
ПО КонтрагентыИзменения.Ссылка = Контрагенты.Ссылка
ГДЕ
КонтрагентыИзменения.Узел = &ПланОбмена_Узел
И &ПланОбмена_НомерПринятогоСообщения <> -1
-
В запросе необходимо обязательно указать два обязательных параметра
= &ПланОбмена_Узел,&ПланОбмена_НомерПринятогоСообщения.Для параметра
&ПланОбмена\_НомерПринятогоСообщениярекомендуется устанавливать конструкцию-заглушку&ПланОбмена_НомерПринятогоСообщения <> -1. -
Выполнить оставшуюся настройку правил выгрузки, провести и закрыть документ.
-
Создать состав выгрузки, указать созданные выше правила выгрузки. При выборе правила инкрементальной загрузки в форме появится раздел «Узлы обмена». В открывшейся таблице нужно нажать кнопку «Заполнить» и после загрузки списка узлов, заполнить колонку «Узел обмена».
-
Записать и закрыть состав выгрузки.
Рекомендации по написанию запросов инкрементальной загрузки
-
Для получения изменений узла обмена нужно использовать таблицу изменений:
- для объектных типов (справочников, документов, планов видов характеристик и тд.) ключом изменения является ссылка;
- для регистров накопления, расчетов, бухгалтерии и зависимых регистров сведений — регистратор;
- для независимых регистров — комбинация измерений.
-
Организовывать структуру таблиц-приемника нужно таким образом, чтобы таблицы всегда содержали колонку регистратора изменений или ключи независимого регистра сведений.
-
В запросе не должно быть отборов. Изменение объекта может привести к тому что объект не будет получен из-за отбора, и в хранилище останется его неактуальная версия.
-
Для получения данных нужно использовать ЛЕВОЕ соединение таблицы изменений с основной таблицей. Ключевые поля должны браться из таблицы изменений, остальные из основной таблицы.
Например, правила выгрузки содержат запрос:
ВЫБРАТЬ
Контрагенты.ИНН,
Контрагенты.КПП,
Контрагенты.Наименование,
Контрагенты.Ответственный,
КонтрагентыИзменения.Ссылка КАК Ссылка
ИЗ
Справочник.Контрагенты.Изменения КАК КонтрагентыИзменения
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
ПО КонтрагентыИзменения.Ссылка = Контрагенты.Ссылка
ГДЕ
КонтрагентыИзменения.Узел = &ПланОбмена_Узел
И &ПланОбмена_НомерПринятогоСообщения <> -1
Если на узле зарегистрировано изменение данных и удаление вернутся следующие данные:
| Ссылка | ИНН | КПП | Наименование | Ответственный |
|---|---|---|---|---|
| 1 | 83b70f0d-f7f4-11e5-943d-00155d000f03 | 8813084210 | 495445951 | ООО «Рога и Копыта» |
| 2 | 511c9ecf-584c-11e8-944c-00155d000f02 |
Выборка запроса вернула две строки: первая строка вернула информацию о измененном контрагенте, который существует в основных данных,вторая строка вернула только идентификатор измененного объекта, но не вернула другие данные. Это значит, что второй элемент выборки был удален. ИНН, КПП, Наименование и Ответственный имеют пустое значение (IS NULL).
- Предусмотрите, что удаленные объекты вернутся из запроса в виде заполненных ключевых полей без заполненных полей основной таблицы.
- Допускается получение данных записей зависимых регистров или по их таблице регистрации, или по таблице регистрации документа-регистратора.
Пример создания инкрементальной выгрузки
Получим данные по изменениям контрагентов из конфигурации «Документооборот 2.0». В качестве плана обмена выберем «Полный обмен данными». Перейдем в функции для технического специалиста, выберем план обмена «Полный обмен данными».

Убедимся, что в форме есть предопределенный узел с признаком «Этот узел», у которого заполнен код.
Создадим узел обмена «Контрагенты»:

Изменим один элемент, и убедимся при помощи обработки «Регистрация изменения для обмена», что изменения зарегистрировались на узле.

В ETL, в источниках данных, обновим информацию о узлах обмена.

Создадим новое правило выгрузки данных, установим текст запроса:
ВЫБРАТЬ
Контрагенты.ИНН,
Контрагенты.КПП,
Контрагенты.Наименование,
Контрагенты.Ответственный,
КонтрагентыИзменения.Ссылка КАК Ссылка
ИЗ
Справочник.Контрагенты.Изменения КАК КонтрагентыИзменения
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
ПО КонтрагентыИзменения.Ссылка = Контрагенты.Ссылка
ГДЕ
КонтрагентыИзменения.Узел = &ПланОбмена_Узел
И &ПланОбмена_НомерПринятогоСообщения <> -1

Перейдем в состав выгрузки и укажем правило, вкладке дополнительно выберем нужный узел обмена.

Направим задание в очередь, проверим полученные данные. Настройка инкрементального получения выполнена.

3.4.5 - Загрузка данных в таблицу из файлов JSON
Загрузка данных состоит из трёх этапов:
- подготовка источников данных;
- разбор файла «JSON»;
- создание правила выгрузки.
Подготовка источников данных
Для обработки файла «JSON» первым шагом необходимо настроить его как источник данных. Для этого перейдите в раздел «Источники данных» и создайте новый источник данных с типом «файл».
Далее, необходимо зарегистрировать набор источников. Подробнее про источники данных можно почитать тут.

Разбор файла JSON
Для подробного ознакомления с интерфейсом конструктора правил разбора «JSON» можно перейти по ссылке.
Необходимо перейти в «Конструктор правил выборки «JSON». Это можно сделать через раздел «Сервис».

После, необходимо загрузить файл «JSON» для того, чтобы ETL получил структуру файла. Необходимо нажать на кнопку «Загрузить JSON», загрузить сам файл и нажать на «Показывать данные».
Следующий этап — разбор файла. Для этого необходимо перенести столбцы в поле выбора. Если они расположены в массиве, нужно нажать на строчку и поставить точку итерации.

Правило разбора данных готово! Осталось его сохранить и использовать в правилах выгрузки.
Создание правила выгрузки
Подробно про правила выгрузки можно почитать тут.
Последовательность действий описана ниже.
- Создать новое правило выгрузки и выбрать вид правила «Произвольный код».

- Перейти в «Настройки произвольного кода» / «Данные модуля» и выбрать в «Модуль получения данных» значение «Разбор JSON по правилам», в «Идентификатор группа обработчиков» выбрать «Выбрать данные из файла» и подтвердить заполнение обработчиков. Результат можно посмотреть во вкладке «Получение списка полей».

- После заполнения раздела «Получение списка полей», необходимо записать правило выгрузки и перейти во вкладку «Настройки параметров».

- В «Настройках параметров выполнения» необходимо нажать на «Заполнить согласно модулю сбора» и для единственного параметра выбрать то правило разбора данных, которое было создано выше и сохранить настройки.

В настройках произвольного кода в разделе «Настройка параметров» появится новый параметр.

- Далее, необходимо заполнить соответствие полей и создать таблицу, в которую будут выгружены данные из файлов.
3.4.6 - Загрузка данных из Битрикс24
Для примера интеграции с Битрикс24 разработана дополнительная обработка «Загрузка из Битрикс». Для работы с обработкой ее необходимо разместить во внешних отчетах и обработках. Их настройка описывается в этой статье.
Для установки правил разбора можно использовать конструктор запросов к веб сервису. Тексты запросов можно посмотреть в режиме отладки.
3.4.7 - Получение данных из web сервисов
Вместе с ETL поставляется модуль получения данных из различных web сервисов с помощью относительно простых http запросов.
Предварительная настройка правила выгрузки
Для получения данных из web сервиса при помощи простого http запроса выполните следующие предварительные действия.
- Создайте «Установку правила выгрузки» с новым правилом выгрузки.
- Задайте вид правила: «Произвольный код».
- Разверните группу формы «Произвольный код».
- Перейдите на вкладку «Данные модуля».
- В качестве модуля получения данных выберите «WEB сервис».
- Нажмите кнопку сохранить.

Открываем мастер настройки простого запроса кнопкой:

Описание настроек мастера

- Тип запроса — «POST» или «GET».
- Строка запроса — URL ресурса. Для GET запроса можно указать вместе с параметрами запроса.
- Таймаут — таймаут запроса в секундах. При превышении интервала — соединение разрывается, а запрос завершается ошибкой.
- Вкладка «Параметры» — параметры запроса. Таблица вида ключ-значение. Для «GET»-запроса таблица синхронизирована с URL сервиса, изменения в таблице влияют на URL, изменения URL в части параметров отражаются в таблице. Для «POST»-запроса данная вкладка доступна только при отсутствии тела запроса и по сути заменяет его, содержимое таблицы кодируется как JSON объект и размещается в теле.
- Вкладка «Тело запроса» — тело «POST-запроса.

- Вкладка «Заголовки» — таблица вида ключ-значение, содержит заголовки запроса.
- Кнопка «Типовые заголовки» — добавляет в таблице заголовков типовые заголовки.

- Вкладка «Куки» — таблица вида ключ-значение, позволяет сопровождать запрос куками.
Конвертирует содержимое таблицы в строку видаkey1=val1;key2=val2;key3=val3;....

- Вкладка «Редирект» — позволяет настроить прараметры редиректа:
- «Переключатель «Выполнять переход» — включает / отключает функцию редиректа;
- «Параметр «Максимум переходов» — ограничивает количество переходов при редиректе;
- «Переключатель «Использовать заголовки основного запроса» — позволяет использовать в запросах перехода заголовки от основного запроса;
- «Переключатель «Использовать логин и пароль основного запроса» — позволяет использовать в запросах перехода параметры аутентификации основного запроса.

- Вкладка «Авторизация» — позволяет настроить параметры авторизации для запроса.
Поддерживаемые варианты:
- «Basic access authentication» — логин и пароль;
- заранее полученный токен. Можно указать имя ключа токена и место его размещения — тело / заголовки.

- Токен получаемый предварительным запросом. Для этого варианта использования токена, нужно:
- в секции «Получение»:
- поставить переключатель «Требуется автоматическое получение токена» в положение «Включено»;
- выбрать тип запроса авторизации «GET / POST»;
- указать URL запроса;
- можно указать значение логина, имя ключа логина и место его расположения;
- можно указать значение пароля, имя ключа пароля и место его расположения;
- иИмя ключа того параметра в котором ожидается токен, а также место его расположения.
- в секции «Использование»:
- Указать имя ключа для полученного токена и его местоположение при запросе
- в секции «Получение»:

Правило

Нижняя часть окна мастера отведена под функции работы с правилом разбора данных.
По кнопке «Открыть в конструкторе» мастер выполнит запрос по ранее настроенным параметрам и откроет полученные данные в конструкторе в режиме просмотра.
Если необходимо выполнить тестовый запрос нужно нажать кнопку:

Если запрос выполнится без ошибок, то мастер предложит сохранить полученные данные в файл.
Если во время выполнения запроса произошла ошибка — будет выведен лог исполнения вместе с подробным описанием ошибки.
Переключатель:

в верхней части окна, позволяет выполнять тестовые запросы в режиме отладки, при котором подробно фиксируются все параметры запроса, и по окончании выполнения показывается окно с полным списком имеющихся параметров.
Окно отладки:

Лог отладки
Лог отладки — инструмент для детального анализа процесса выполнения web запроса. Имеет в своём составе следующие компоненты:
- «Консоль лога» — список событий с описаниями;
- «Просмотр значений» — окно просмотра значения отдельных элементов запроса (тело запроса, тело ответа, заголовки запроса, заголовки ответа). Для отображения в окне просмотра значения, его нужно выбрать в списке запросов;
- «Ответ как веб документ» — диалог для просмотра тела ответа в окне встроенного браузера;
- «Список запросов» — таблица в которой строки — отдельные запросы, а колонки — значения элементов запроса доступные для просмотра (тело запроса, тело ответа, заголовки запроса, заголовки ответа). Для запроса без редиректа содержит одну строку. Если был осуществлён переход по адресам редиректа, то для каждого перехода (запроса) будет отдельная строка.
Повторное использование настроенного правила запроса к web сервису
По завершению этапа подготовки запроса к web сервису, необходимо настроить поля, которые впоследствии станут колонками в таблице хранилища. Эта таблица предназанчена для хранения даныых полученых из web сервиса.
Настройка повторной выгрузки
- Находясь в подготовленном окне запроса к web сервису, нажать кнопку «Открыть в конструкторе», произвести настройку полей и сохранить правило разбора.
- Закрыть окно «Конструктора» и окно «Источник данных: Web сервис».
- Перейти на вкладку «Настройка параметров». Если всё настроено верно, в данной вкладке отображаются порядка 20 строк параметров.

Стоит обратить внимание на строку 3 «ПравилоРазбора», если она пустая, необходимо перейти в параметры и из выпадающего списка выбрать настроенное ранее правило.
- Далее производится стандартная настройка правила выгрузки
Настройка источника
В качестве источника данных для использования в составе выгрузки, необходимо применять настроенный заранее источник и зарегистрировать этот источник в наборе.
Состав выгрузки
По завершению всех настроек, источник и правило получения данных необходимо объединить в состав выгрузки.
Обратите внимание, что при выборе настроенного на web сервис правила, все параметры должны появится на вкладке «параметры запроса” данного состава выгрузки.

По завершению настройки состава, станет возможным многократный запрос к web сервису и сохранение полученных данных в таблицу хранилища.
3.5 - Настройка процесса выгрузки данных
3.5.1 - Однократный запуск получения данных (запуск «вручную»)
В случае, когда требуется получить данные разово («ad-hoc»), а также для тестирования правил выгрузки (рекомендуется тестировать вручную на ограниченном наборе данных), возможно получить данные однократно, не настраивая расписание запуска.
Есть два варианта ручного запуска выгрузки данных:
- выгрузка в отчет (возможна выгрузка в отчет на экране, в файл, в SQL-таблицу, указанную в правиле выгрузки);
- запуск состава выгрузки (производится выгрузка в SQL-таблицу, указанную в правиле выгрузки).
Основное отличие этих вариантов в случае выгрузки в таблицу в том, что при выгрузке в отчет используются настройки и параметры из документа «Установить правила выгрузки», а при выгрузке с использованием документа «Состав выгрузки» настройки и параметры из документа «Состав выгрузки». Вместе с этим, при запуске с помощью выгрузки в отчет создается специальный, служебный «Состав выгрузки».
1. Запуск выгрузки данных в отчет
Перейти к обработке выгрузки в отчет можно через «Начальную страницу» или через меню «Главное» / «Сервис» / «Выгрузка в отчет»:

«Выгрузка в отчет» это полнофункциональный вариант получения данных, с тем лишь отличием, что при выводе данных на экран, либо при сохранении в файл, все собранные данные хранятся во временных структурах базы Modus ETL. Поэтому не рекомендуется использовать этот вариант для получение большого количества данных.
Сервис «Выгрузка в отчет» предлагается в трёх вариантах:
- вывод на экран — выведет данные в таблицу на экран;
- выгрузка в файл — выведет данные в файл выбранного формата в выбранный каталог;
- выгрузка в таблицу БД — запишет данные в таблицу БД, если она указана в выбранном правиле выгрузки.

Порядок настройки:
- выбрать набор источников (см. рисунок выше, 1);
- выбрать правило выгрузки (см. рисунок выше, 2);
- для вывода данных на экран дополнительные настройки не нужны, достаточно нажать кнопку «Вывести на экран» (см. рисунок выше, 3);
- для выгрузки в файл по умолчанию установлен тип файла «xlsx», можно установить переключатель на другой тип файла («dbf»/«mxl»/«xls»/«xlsx») и нажать кнопку «Выгрузить в файл» (см. рисунок выше, 4);
- для выгрузки в таблицу нужно выбрать режим записи (аналогично режимам записи в составе выгрузки), установить при необходимости флаг «Заменить спец. символы» (см. рисунок выше, 7) (если предполагается, что выходной набор данных может содержать текстовые поля со спец. символами типа перевод строки, кавычки и т.п.) и нажать кнопку «Загрузить в таблицу БД» (см. рисунок выше, 5).
Прогресс процесса выгрузки данных можно наблюдать на индикаторе процесса (см. рисунок выше, 8).
Остановить процесс можно, нажав на кнопку «Остановить выполнение» (см. рисунок выше, 9).
2. Запуск выгрузки данных в таблицу через Состав выгрузки
Открыть справочник «Составы выгрузки» (меню «Главное» / «Настройки» / «Составы выгрузок»).

Для ручного запуска состава выгрузки, выбрать в списке нужный элемент справочника и нажать кнопку «Направить задание в очередь».
3.5.2 - Автоматический (регулярный) сбор данных
Для регулярного сбора и обработки данных, а также для рационального распределения ресурсов при получении больших массивов данных рекомендуется настроить расписание работы.
1. Настройка состава выгрузок и расписания запуска сбора данных
Размещение: меню: «Главное» / «Настройки» / «Составы выгрузок». Интерфейс (справочник)» «Составы выгрузок» также предназначен для настройки расписания выгрузок (подробно о заполнении состава выгрузок).
2. Настройка расписания запуска сбора данных
Порядок действий показан в таблице ниже.
Настройка расписания запуска сбора данных
| Закладка | Настройка | Скрин |
|---|---|---|
| Общий | ДатаНачала; Повторять каждые ___ (дн.); |

|
| Дневное | Время начала |

|
| Недельное | Дни_недели |

|
| Месячное | Месяцы |

|
3. Механизм очередей
Механизм очередей разработан для управления ресурсами при одновременном получении данных разными заданиями, разделения получения данных из большого количества источников на порции и управления ими.
Общие правила работы с очередями
Со стороны пользователя для настройки работы необходимо заполнить:
- основные настройки
- создать «Состав выгрузок» с указанием набора, правил, расписания запуска.
Для интерактивного контроля за работой очереди в форме списка «Составы выгрузок» внизу формы есть сводная информация по очереди «Набор» / «Правило» / «Количество элементов». Из формы «Составы выгрузок» можно направить выбранный состав в очередь вручную, для этого предназначена команда «Направить задание в очередь»:

Разработано три «службы» (регламентных задания) для работы с очередью получения данных.
3.1. Постановщик источников в очередь
Данная служба привязана к «Составам выгрузок». В нем настраивается связь «Набор источников» — «Правило выгрузки». Если «Состав выгрузок» активен и настроено расписание, создается регламентное задание для постановки источников в очередь из выбранного набора.
- При запуске регламентного задания выполняются подготовительные действия в соответствии с «Режимом записи данных» («Добавить», «Очистить и добавить», «Скопировать и добавить»). Если в «Составе выгрузок» режим записи не указан, то берется режим из основных настроек.
- При создании состава выгрузок можно указать приоритет при выгрузке – чем меньше число, тем выше приоритет.
- Также при постановке «набора» по «правилу» в очередь, создается документ «Факт выгрузки». Логи обработки очереди привязаны к этому документу.
3.2. Запуск заданий обработки очереди
Служба анализирует сколько уже запущено фоновых заданий по обработке очереди. Анализируются настройки максимального количество возможных заданий и выполняется до-запуск нужного количество фоновых заданий-обработчиков.
Каждое фоновое задание «ОбработкаОчередиРегламентом» анализирует очередь, и выбирает «порцию» согласно основным настройкам. В элементы очереди, которые заняты конкретным фоновым заданием, записывается Id фонового задания.
При записи данных во внешнюю базу происходит удаление элемента из очереди по источнику. Это происходит в одной транзакции, поэтому не должно быть ситуация, когда во внешний источник записали данные, а из очереди не удалили.
3.3. Перепостановка элементов очереди
Регламентное задание, которое анализирует текущие фоновые задания «ОбработкаОчередиРегламентом» и если в очереди есть задания с Id, которого нет среди работающих, то Id записи очищается и считается, что данный источник необходимо обработать заново.
В очереди также хранятся дополнительные данные:
- количество попыток — сколько раз пытались обработать этот источник;
- зависшие задания — массив Id заданий, которые «зависли». Заполняется для будущего анализа.
4. Обработка «Контроль работы»

Форма (см. рисунок выше) состоит из двух списков, которые автоматически обновляются каждые 60 секунд:
- список последних выполняемых пакетов с указанием даты и времени запуска, названием пакета и статусом выполнения;
- список текущей очереди выполняемых выгрузок данных, который содержит набор источников, правило выгрузки, факт выгрузки, количество элементов, количество работающих фоновых заданий.
По двойному клику по наименованию пакета открывается форма выполнения пакета.

Выбрав пакет двойным кликом в подчиненных документах, можно открыть форму пошагового выполнения пакета.

Также можно открыть правило выгрузки, набор источников или посмотреть факт выгрузки у текущего задания.
Через меню: «Главное» / «Сервис» / «Очередь обработки данных» можно посмотреть очередь из оставшихся источников выгрузки данных и количество попыток соединения с ними.

3.5.3 - Логирование выгрузки данных
В ходе выгрузки данных осуществляется логирование процесса — создаются записи в регистре сведений «Журнал событий сбора данных» и документ «Факт выгрузки», который отображает записи регистра для конкретной выгрузки данных.
Логирование происходит как при автоматической, так и при ручной выгрузке данных.
Есть два способа просмотреть лог выгрузки данных:
- документ «Факт выгрузки»;
- отчет «Анализ логов загрузки».
1. Документ «Факт выгрузки»
Просмотр списка документов — меню «Главное» / «Логи» / «Факт_выгрузки».
Документ формируется при выгрузке данных и отображает информацию об этапах выгрузки, ошибочных ситуациях и количественных показателях (времени выполнения, количестве строк данных, полученных из источника, и т.д.):

2. Отчет «Анализ логов загрузки»
Запуск отчета — «Начальная страница» / «Анализ логов загрузки»:

В интерфейсе отчета можно выбирать вариант (форму отчета) «Обычная» / «По областям» и настраивать отборы (период, документ и т.д.).
Возможно выводить только ошибки, установив соответствующий флаг:

3.6 - Загрузка данных из временных таблиц
При использовании временных таблиц в качестве источника, необходимо учитывать особенности конкретной СУБД.
PostgreSQL
При создании временной таблицы вы не можете явно указать схему (schema) для таблицы. Все временные таблицы в PostgreSQL попадают в соответствующую схему с именем pg_temp_xxx, где «xxx» — номер сессии (например pg_temp_8 или pg_temp_165).
Схема для сессии создаётся автоматически самим PostgreSQL.
Для возможности сделать запрос к временной таблице, необходимо указать правильную схему, что является не тривиальной задачей при периодическом обновлении. Скорее всего понадобится специальная обработка для ETL.
Если подразумевается единоразовая выгрузка, то необходимо определить схему, в которой создалась временная таблица и указать её в запросе либо в шаблоне сценария.
Запрос должен строится следующем образом:
SELECT col1, col2, col-n From pg_temp_xxx.tmp_table_name
где «xxx» — номер сессии, а tmp_table_name — наименование временной таблицы.
Для определения схемы временной таблицы можно воспользоваться запросом:
SELECT schemaname FROM pg_catalog.pg_tables where tablename ='tmp_table_name'

MS SQL
После создания все временные таблицы сохраняются в схеме tempdb, которая имеется по умолчанию в MS SQL. Временные таблицы существуют на протяжении сессии базы данных.
Для взаимодействия с временными таблицами MS SQL через ETL, они должны быть глобальными, т.е. при создании указывается два знака ##.
Так же в запросе указывается схема временной таблицы:
SELECT * FROM tempdb.##tmp_table_name

3.7 - Мастер интеграции
Мастер интеграции – это универсальный инструмент ETL, который позволяет аналитику без привлечения программиста настраивать интеграцию с различными Сервисами-источниками для получения из них данных.
Интеграция с каждым Сервисом-источником осуществляется при помощи специального драйвера-коннектора. Пользователь при работе с Мастером интеграции выбирает доступный драйвер-коннектор к соответствующему Сервису-источнику и пошагово осуществляет настройку получения данных из этого Сервиса.
Список доступных драйверов-коннекторов:
P.S.: Список доступных драйверов-коннекторов Мастера интеграции будет постепенно расширяться, чтобы охватить наиболее востребованные Сервисы-источники.
Мастер интеграции, на основании созданной пользователем настройки, автоматически генерирует весь стандартный набор Объектов ETL, необходимых для получения данных (Источники, Наборы источников, Правила выгрузки, Составы выгрузки, Пакеты обработки данных и т.д).
Мастер интеграции позволяет проще и быстрее настраивать получение данных из различных информационных систем и сервисов, минимизируя необходимость вручную настраивать сложные параметры или писать код для обработки и передачи данных. Он обеспечивает удобный интерфейс для выбора источников данных, настройки параметров и создания интеграционных потоков, что делает процесс более доступным для пользователей без глубоких технических знаний.
3.7.1 - Общие настройки Мастера интеграции
Для начала работы с Мастером интеграции, перейдите на начальную страницу и выберите соответствующий пункт в меню.

Отображение Мастера интеграции
Если на начальной странице ETL Мастер интеграции не отображается его необходимо включить. Для отображения Мастера интеграции необходимо пользователю с ролью администратор:
- Выбрать на начальной странице ETL “Информация” → “Основные настройки”.
- В подменю “Управление хранилищем” проверить, установлена ли галочка напротив “Использовать управление хранилищем”.
- В подменю “Прочее” выбрать опцию “Использовать Мастер интеграции”.
Поскольку Мастер интеграции использует функционал по управлению хранилищем, даже если настройка “Управление хранилищем” не выбрана, соответствующий функционал будет автоматически активирован.


Основное меню Мастера интеграции
После входа в конфигуратор мастера интеграции пользователю предоставляется возможность либо выбрать существующий мастер интеграции, либо создать новый. Функционал мастера позволяет объединять группы интеграции для более эффективного управления данными.
Режим просмотра: С помощью кнопки ЕЩЕ пользователь может выбрать необходимый режим просмотра, такой как “Дерево”, “Список” или “Иерархический список”. Это обеспечивает удобство при визуализации и организации данных в соответствии с предпочтениями пользователя.
Мастер интеграции состоит из 6 шагов, представленных в виде вкладок, на каждой из которых производятся различные настройки. Перемещение между этими вкладками осуществляется с помощью кнопок Назад и Далее. Также можно перейти к предыдущему шагу, кликнув по названию соответствующей вкладки.
1. Вкладка “Сервис-источник”
Выбор Сервиса-источника: На этой вкладке пользователю предоставляется возможность настройки подключения к существующему сервису-источнику или создание нового. Для выбора существующей настройки подключения сервиса-источника - необходимо выбрать нужный сервис-источник и нажать кнопку Выбрать. После этого название источника будет выделено жирным шрифтом.
Создание новой настройки сервиса-источника: При создании нового сервиса-источника, система запросит указать и выбрать файл драйвера сервиса в формате *.epf. Можно отказаться от загрузки файла. В меню необходимо ввести название конфигурации, затем выбрать Вид объекта - Обработка конфигурации или Дополнительная обработка. В поле Основная обработка выбрать нужный драйвер-коннектор и нажать “Сохранить”. После этого, в разделе “Параметры” будет предложено ввести параметры подключения (например: webhook, логин и пароль). Параметры могут отличаться в зависимости от выбранного драйвера-коннектора. Нажмите на кнопку “Проверить подключение” (если поддерживается), чтобы убедиться, что подключение успешно установлено. По завершении настройки необходимо нажать Сохранить и закрыть.
Важно отметить, что создание нового подключения к Сервису-источнику доступно исключительно для пользователя ETL, обладающего ролью Администратора. Аналитики могут только открывать, просмотривать и использовать (выбирать) существующие подключения при создании настройки Мастера интеграции.
Кнопка Инсталлировать (Отображается, если данное действие поддерживается драйвером-коннектором) позволяет выполнить инсталляционные действия и заполнить параметры.
Кнопка Деинсталлировать (Отображается, если данное действие поддерживается драйвером-коннектором) позволяет выполнить деинсталляционные действия.
Кнопка Проверить подключение (Отображается, если данное действие поддерживается драйвером-коннектором) позволяет проверить корректность параметров подключения.

2. Вкладка “Разделы сервиса”
На данной вкладке пользователь имеет возможность выбора и настройки раздела сервиса.
Выбор раздела сервиса: для выбора нужного раздела необходимо нажать кнопку Выбрать. Важно учесть, что выбрать можно только один раздел сервиса.
Обновление списка разделов сервиса: если возникает необходимость обновить список разделов в соответствии с данными драйвера, следует нажать кнопку Обновить по данным сервиса.
Создание раздела сервиса вручную (если поддерживается): пользователь может создать раздел сервиса самостоятельно, указав все требуемые параметры, для этого необходимо нажать кнопку Создать.
3. Вкладка “Параметры раздела”
На этой вкладке пользователь вносит параметры раздела сервиса. Специфика и состав этих параметров варьируются в зависимости от выбранного сервиса. Важно отметить, что все параметры являются необязательными к заполнению. Для некоторых Сервисов-источников разделы могут вовсе не содержать параметров. В такой ситуации рекомендуется пропустить этот шаг, нажав кнопку Далее.
4. Вкладка “Объекты-источники”
На данной вкладке Отображаются только те объекты-источники, которые принадлежат выбранному разделу сервиса.
Для выбора объекта-источника необходимо нажать на кнопку Выбрать. Пользователь имеет возможность выбирать один или несколько объектов-источников для последующей настройки. Для отказа от ранее выбранного объекта следует нажать Отменить выбор.
Если необходимо обновить список объектов в соответствии с актуальными данными драйвера, можно воспользоваться кнопкой Обновить.
Для перехода к запросу примеров данных можно использовать кнопку Перейти, если драйвер поддерживает данную функциональность.
Создание объекта-источника вручную (если поддерживается): пользователь имеет возможность самостоятельно создать объект-источник, заполнив необходимые параметры. При созданни объекта-источника кнопка Заполнить по о правилу разбора данных (если поддерживается) позволяет автомматически заполнить поля объекта-источника в соответствии с установленными правилами разбора данных.
5. Вкладка “Таблицы-приемники”
На данной вкладке пользователь решает задачу создания и настройки Таблицы-приемника для каждого выбранного Объекта-источника. Этот процесс включает в себя выстраивание соответствия между полями Объекта-источника и полями Таблицы-приемника.
Пошаговая инструкция:
- Выбор Объекта-источника: В левой части интерфейса пользователь выбирает объект сервиса 1 и поля 2, которые требуется передать в Таблицу-приемник.
- Настройка таблицы-приемника 3:
- Выбор базы данных: Определяется база данных, в которой будет расположена Таблица-приемник.
- Выбор таблицы модели: Пользователь может использовать уже существующую таблицу, создать новую или изменить существующую. Для создания новой таблицы следует нажать кнопку + Создать и заполнить необходимые данные. После завершения настройки таблица будет создана в базе данных.
- Выбор режима записи данных: Определяется методика записи данных в таблицу. Доступные варианты: “Добавить”, “Очистить и добавить”, “Скопировать и добавить”.

- Сопоставление полей: Опции сопоставления полей:
Кнопка Автосопоставление - позволяет автоматически сопоставить поля объекта-источника и поля таблицы-приемника по именам и типам. Кнопка Очистить сопоставление - позволяет полностью очистить существующее сопоставление полей. Двойное нажатие на символ “х” в правой части таблицы позволяет очистить сопоставление по конретному полю.
Важные уточнения
- Пользователь может выбрать как существующую Таблицу-приемник, так и создать новую.
- При необходимости состав полей Таблицы-приемника можно изменить, что приведёт к её пересозданию. Следует учесть, что при этом все ранее записанные данные будут утеряны, и таблицу нужно будет заполнить заново.
- Переход к следующему шагу возможен только после того, как будут сопоставлены поля для всех выбранных ранее объектов сервиса.

6. Вкладка “Дополнительно”
На вкладке «Дополнительно» пользователь выполняет шаги для завершения настройки Мастера интеграции. Здесь можно создать расписание для «Пакета обработки данных», добавить в пакет сценарий обработки данных.
Также на этой вкладке пользователь может выполнить дополнительные действия:
-
Кнопка Создать объекты/Обновить объекты позволяет создать или обновить пакет обработки данных и вспомогательные объекты ETL.
-
Кнопка Запустить пакет позволяет запустить сбор данных по созданному пакету обработки данных.
-
Переключатель и гиперссылка Выполнять по расписанию позволяет настроить выполнение пакета обработки данных ETL “по расписанию”.
Важные уточнения
- После каждого изменения настроек Мастера интеграции необходимо обновить созданные объекты ETL.
- Настройка Мастера интеграции становится недоступной для редактирования во время выполнения пакета ETL. Для внесения изменений дождитесь завершения процесса, либо прервите выполнение пакета.
- Редактирование объектов ETL, созданых при помощи Мастера интеграции, возможно только через изменения параметров соответствующей настройки Мастера интеграции.
3.7.2 - Настройка мастера интеграции для Битрикс24
Мастер интеграции ETL позволяет настроить подключение к сервису Битрикс24, чтобы получать из него данные для их дальнейшей обработки и использования при построении визуализций.
Для успешной работы с этим инструментом необходимо выполнить первоначальные настройки, описанные в статье “Общие настройки мастера интеграции. Перед началом работы с Мастером интеграции необходимо непосредственно в сервисе Битрикс24 настроить вебхук для вызова REST API. Настройка вебхука требуется, чтобы Мастер интеграции смог подключиться к сервису Битрикс24. Для настройки вебхука пользователь должен иметь права администратора в рамках сервиса Битрикс24. Детальную инструкцию по настройке вебхука можно найти по ссылке: инструкция по настройке вебхука. https://helpdesk.bitrix24.ru/open/code_12337906/

1. Вкладка “Сервис-источник”
Для создания нового подключения к сервис-источнику в Битрикс24, Можно отказаться от загрузки файла. В меню необходимо ввести название конфигурации, за тем выбрать Вид объекта - Обработка конфигурации, основную обработку выбрать требуемую и нажать “Сохранить”. После этого, в разделе “Параметры” будет предложено ввести параметры подключения webhook, логин и пароль (параметры могут отличаться в зависимости от конфигурации). Нажмите на кнопку “Проверить подключение”. Если все данные введены верно, система выведет сообщение о том, что подключение успешно установлено. По завершении настройки необходимо нажать Сохранить и закрыть.
Важно отметить, что создание нового подключения к Сервису-источнику доступно исключительно для пользователя ETL, обладающего ролью Администратора. Пользователи с ролью аналитик могут только открывать существующие подключения, осуществлять их просмотр и выбирать подходящие для применения в рамках текущих настроек Мастера интеграции.

2. Вкладка “Разделы сервиса”
На этой вкладке пользователь выбирает необходимый раздел сервиса, используя кнопку Выбрать. Изначально список разделов отображается пустым. Чтобы отобразить список разделов сервиса в соответствии с данными драйвера, необходимо нажать кнопку Обновить по данным сервиса.

В структуре списка разделов, используемого при настройке Мастера интеграции, предусмотрены два смысловых уровня. Первый уровень представляет собой смысловые блоки из Битрикс24, такие как CRM, задачи, календари и так далее. Второй уровень обеспечивает более детализированное разделение в соответствии с логикой работы сервиса Битрикс24, включая более мелкие подразделы внутри каждого из блоков.
Для адаптации отображения и лучшего понимания иерархии разделов предусмотрена возможность выбора одного из трех режимов просмотра. Для этого необходимо воспользоваться кнопкой ЕЩЕ, затем выбрать опцию Режим просмотра. Этот шаг позволит увидеть и лучше понять разделение на уровни, облегчая процесс выбора необходимых разделов для работы в Мастере интеграции.
Пользователю предоставляется возможность выбора как разделов первого уровня, так и разделов второго уровня для настройки Мастера интеграции. Выбор раздела первого уровня автоматически предоставляет доступ ко всем объектам-источникам, относящимся к данному блоку, включая те, что находятся в разделах второго уровня. Важно помнить, что можно выбрать только один раздел для работы.

3. Вкладка “Параметры раздела”
Для Сервиса «Битрикс24» заполнение параметров не требуется и этот шаг следует пропускать, нажимая на кнопку Далее.
4. Вкладка “Объекты-источники”
На данной вкладке пользователь имеет возможность выбирать один или несколько объектов-источников для последующей настройки. Изначально список разделов отображается пустым. Чтобы отобразить список разделов сервиса в соответствии с данными драйвера, необходимо нажать кнопку Обновить по данным сервиса.
Для выбора доступно нажатие на кнопки Выбрать для подтверждения выбора или Отменить выбор для отказа от ранее выбранного объекта. Отображаются только те объекты, которые принадлежат выбранному разделу сервиса.
Для перехода к запросу примеров данных можно использовать кнопку Перейти, если драйвер поддерживает данную функциональность.
Создание объекта-источника вручную: пользователь имеет возможность самостоятельно создать объект-источник, заполнив необходимые параметры.
Заполнение по правилу разбора данных: Если драйвер предоставляет такую функцию, кнопка Заполнить по правилу разбора данных позволяет автоматически заполнить поля объекта сервиса в соответствии с установленными правилами разбора данных.
На этой вкладке предоставлена возможность просмотра сэмплов данных. При нажатии на ссылку «Перейти» (1) в строке соответствующего объекта открывается окно, где можно запросить (2) пример данных. После получения сэмпла доступен переход в конструктор (3), где предоставляется возможность просмотра и анализа полученного сэмпла данных. В конструкторе также можно настроить правила для разбора данных.

В остальных аспектах настройка Мастера интеграции для извлечения данных из сервиса «Битрикс24» выполняется в соответствии с предоставленными рекомендациями, приведёнными в статье “Общие настройки мастера интеграции
Описание полей выгружаемых мастером интеграции из Битрикс24:
3.7.2.1 - Описание полей Битрикс24
Раздел CRM
Подраздел “Лиды”
Таблица Лиды
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS | Строка(max) | Улица, дом, корпус, строение |
| ADDRESS_2 | Строка(max) | Квартира, офис |
| ADDRESS_CITY | Строка(max) | Город |
| ADDRESS_COUNTRY | Строка(max) | Страна |
| ADDRESS_COUNTRY_CODE | Строка(max) | Код страны |
| ADDRESS_LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| ADDRESS_POSTAL_CODE | Строка(max) | Почтовый индекс |
| ADDRESS_PROVINCE | Строка(max) | Область |
| ADDRESS_REGION | Строка(max) | Район |
| ASSIGNED_BY_ID | Число | Ответственный |
| BIRTHDATE | Строка(max) | Дата рождения контакта |
| COMMENTS | Строка(max) | Комментарии |
| COMPANY_ID | Число | Идентификатор компании |
| COMPANY_TITLE | Строка(max) | Название компании |
| CONTACT_ID | Число | Идентификатор контакта |
| CONTACT_IDS | Число | Идентификатор привязанного контакта |
| CREATED_BY_ID | Число | Создан |
| CURRENCY_ID | Строка | Идентификатор валюты |
| DATE_CLOSED | Дата и время | Дата закрытия |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| Строка(max) | ||
| HAS_EMAIL | Строка | Проверка заполненности поля электронной почты |
| HAS_IMOL | Строка | Задана открытая линия |
| HAS_PHONE | Строка | Проверка заполненности поля телефон |
| HONORIFIC | Строка | Вид обращения |
| ID | Число | Идентификатор лида. |
| IM | Строка(max) | Контакт в службе обмена мгновенными сообщениями |
| IS_MANUAL_OPPORTUNITY | Строка | Флаг “Режим расчета суммы”. По умолчанию “N” - сумма рассчитывается автоматически. |
| IS_RETURN_CUSTOMER | Строка | Признак повторного лида |
| LAST_ACTIVITY_BY | Число | LAST_ACTIVITY_BY |
| LAST_ACTIVITY_TIME | Дата и время | LAST_ACTIVITY_TIME |
| LAST_NAME | Строка(max) | Фамилия |
| LINK | Строка(max) | LINK |
| MODIFY_BY_ID | Число | Изменен |
| MOVED_BY_ID | Число | Идентификатор автора перемещения элемента на текущую стадию |
| MOVED_TIME | Дата и время | Дата перемещения элемента на текущую стадию |
| NAME | Строка(max) | Имя контакта |
| OPENED | Строка | Флаг “Доступен для всех” |
| OPPORTUNITY | Число | Предполагаемая сумма |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| PARENT_ID_159 | Строка(max) | Облако Модус |
| PHONE | Строка(max) | Телефон |
| POST | Строка(max) | Должность |
| SECOND_NAME | Строка(max) | Отчество контакта |
| SOURCE_DESCRIPTION | Строка(max) | Дополнительно об источнике |
| SOURCE_ID | Строка | Идентификатор источника |
| STATUS_DESCRIPTION | Строка(max) | Дополнительная информация о статусе |
| STATUS_ID | Строка | Идентификатор статуса лида |
| STATUS_SEMANTIC_ID | Строка(max) | Состояние статуса |
| TITLE | Строка(max) | Название лида. Обязательное поле. |
| UF_CRM_*** | Строка(max) | Пользовательские поля |
| UTM_CAMPAIGN | Строка(max) | Обозначение рекламной кампании |
| UTM_CONTENT | Строка(max) | Содержание кампании |
| UTM_MEDIUM | Строка(max) | Тип трафика |
| UTM_SOURCE | Строка(max) | Рекламная система |
| UTM_TERM | Строка(max) | Условие поиска кампании |
| WEB | Строка(max) | веб-сайт |
Таблица Лиды.Адреса
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS_1 | Строка(max) | Улица, дом, корпус, строение. |
| ADDRESS_2 | Строка(max) | Квартира, офис |
| ANCHOR_ID | Число | Примечание. Эти поля для служебного использования. Они нужны для решения задачи производительности в выборках по старшим сущностям (Компаниям/Контактам) в элементах CRM, которые с ними напрямую не связаны, а связаны опосредовано через другой элемент CRM. При добавлении записи Адреса обязательно указывается непосредственная привязка адреса к старшей сущности - ENTITY_ID, ENTITY_TYPE_ID . Например, это Реквизит. Но в поля записи Адреса ANCHOR_TYPE_ID и ANCHOR_ID автоматически проставится привязка к более старшей сущности самого Реквизита - Компании/Клиенту. |
| ANCHOR_TYPE_ID | Число | Родительская сущность, с которой связана текущая запись. |
| CITY | Строка(max) | Город. |
| COUNTRY | Строка(max) | Страна. |
| COUNTRY_CODE | Строка(max) | Код страны. |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| ENTITY_TYPE_ID | Число | Тип родительской сущности. Возможные типы: “Компания”, “Контакт”. Обязательное поле. |
| LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| POSTAL_CODE | Строка(max) | Почтовый индекс. |
| PROVINCE | Строка(max) | Область. |
| REGION | Строка(max) | Район. |
| TYPE_ID | Число | Тип контакта |
Таблица Лиды.Дела
| Имя | ТИП | Описание поля |
|---|---|---|
| ASSOCIATED_ENTITY_ID | Число | Идентификатор связанной с делом сущности |
| AUTHOR_ID | Число | Создатель дела |
| AUTOCOMPLETE_RULE | Число | Автозаполнение |
| BINDINGS | Строка(max) | Привязки |
| COMMUNICATIONS | Строка(max) | Канал коммуникации |
| COMPLETED | Строка | Завершено |
| CREATED | Дата и время | Создано |
| DEADLINE | Дата и время | Срок исполнения |
| DESCRIPTION | Строка(max) | Описание |
| DESCRIPTION_TYPE | Строка(max) | Тип описания |
| DIRECTION | Строка(max) | Направление дела: входящее/исходящее. |
| EDITOR_ID | Число | Кто изменил |
| END_TIME | Дата и время | Время завершения |
| FILES | Строка(max) | Добавленные файлы |
| ID | Число | Идентификатор лида. |
| IS_INCOMING_CHANNEL | Строка | IS_INCOMING_CHANNEL |
| LAST_UPDATED | Дата и время | Дата последнего обновления |
| LOCATION | Строка(max) | Местоположение. |
| NOTIFY_TYPE | Строка(max) | Тип уведомлений |
| NOTIFY_VALUE | Число | Параметр уведомления |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE_ID | Строка(max) | Тип собственника |
| PRIORITY | Строка(max) | Приоритет |
| PROVIDER_DATA | Строка(max) | Данные провайдера |
| PROVIDER_GROUP_ID | Строка(max) | Тип коннектора |
| PROVIDER_ID | Строка(max) | Идентификатор провайдера |
| PROVIDER_PARAMS | Строка(max) | Параметры провайдера |
| PROVIDER_TYPE_ID | Строка(max) | Идентификатор типа провайдера |
| RESPONSIBLE_ID | Число | Ответстветнный |
| RESULT_CURRENCY_ID | Строка(max) | RESULT_CURRENCY_ID |
| RESULT_MARK | Число | RESULT_MARK |
| RESULT_SOURCE_ID | Строка(max) | RESULT_SOURCE_ID |
| RESULT_STATUS | Число | RESULT_STATUS |
| RESULT_STREAM | Число | Статистика отчётов |
| RESULT_SUM | Число | RESULT_SUM |
| RESULT_VALUE | Число | RESULT_VALUE |
| SETTINGS | Строка(max) | Настройки |
| START_TIME | Дата и время | Время начала выполнения |
| STATUS | Строка(max) | Статус |
| SUBJECT | Строка(max) | Субьект |
| TYPE_ID | Строка(max) | Тип контакта |
| WEBDAV_ELEMENTS | Строка(max) | Добавленные файлы |
Таблица Лиды.Контакты
| Имя | ТИП | Описание поля |
|---|---|---|
| CONTACT_ID | Число | Идентификатор контактного лица |
| IS_PRIMARY | Строка | Первичный |
| OWNER_ID | Число | Собственник |
| SORT | Число | Сортировка |
Таблица Лиды.ТоварныеПозиции
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| CUSTOMIZED | Строка | Изменен |
| DISCOUNT_RATE | Число | Величина скидки |
| DISCOUNT_SUM | Число | Сумма скидки |
| DISCOUNT_TYPE_ID | Число | Тип скидки |
| MEASURE_CODE | Число | Код единицы измерения |
| MEASURE_NAME | Строка(max) | Единица измерения |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE | Строка(max) | Тип владельца |
| PRICE | Число | Цена |
| PRICE_BRUTTO | Число | PRICE_BRUTTO |
| PRICE_EXCLUSIVE | Число | Цена без налога со скидкой |
| PRICE_NETTO | Число | PRICE_NETTO |
| PRODUCT_ID | Число | Товар |
| PRODUCT_NAME | Строка(max) | Название товара |
| QUANTITY | Число | Количество |
| SORT | Число | Сортировка. |
| TAX_INCLUDED | Строка | Налог включен в цену |
| TAX_RATE | Число | Налог |
| TYPE | Число | TYPE |
Подраздел “Сделки”
Таблица Сделки
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDITIONAL_INFO | Строка(max) | Дополнительная информация |
| ASSIGNED_BY_ID | Число | Идентификатор ответственного за сделку |
| BEGINDATE | Строка(max) | Дата открытия сделки |
| CATEGORY_ID | Строка(max) | Идентификатор воронки. Связь с Таблицей “Сделки.Справочник_Воронки продаж” по полю ID |
| CLOSED | Строка | Флаг “Сделка закрыта” |
| CLOSEDATE | Строка(max) | Дата закрытия сделки |
| COMMENTS | Строка(max) | Комментарии |
| COMPANY_ID | Число | Идентификатор компании-контрагента сделки |
| CONTACT_ID | Число | Идентификатор контактного лица |
| CONTACT_IDS | Число | Идентификатор привязанного контакта |
| CREATED_BY_ID | Число | Идентификатор создавшего сделку |
| CURRENCY_ID | Строка | Валюта сделки |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| IS_MANUAL_OPPORTUNITY | Строка | Флаг “Режим расчета суммы”. По умолчанию “N” - сумма рассчитывается автоматически. |
| IS_NEW | Строка | Флаг новой сделки (т. е. сделка в первой стадии) |
| IS_RECURRING | Строка | Флаг шаблона регулярной сделки (если стоит Y, то это не сделка, а шаблон) |
| IS_REPEATED_APPROACH | Строка | Повторное обращение |
| IS_RETURN_CUSTOMER | Строка | Признак повторного лида |
| LAST_ACTIVITY_BY | Число | LAST_ACTIVITY_BY |
| LAST_ACTIVITY_TIME | Дата и время | LAST_ACTIVITY_TIME |
| LEAD_ID | Число | Идентификатор лида |
| LOCATION_ID | Строка(max) | Местоположение клиента |
| MODIFY_BY_ID | Число | Идентификатор изменившего сделку |
| MOVED_BY_ID | Число | Идентификатор автора перемещения элемента на текущую стадию |
| MOVED_TIME | Дата и время | Дата перемещения элемента на текущую стадию |
| OPENED | Строка | Флаг “Сделка доступна для всех” |
| OPPORTUNITY | Число | Сумма в валюте сделки |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| PROBABILITY | Число | Вероятность заключения сделки (в %) |
| QUOTE_ID | Число | Идентификатор квоты |
| SOURCE_DESCRIPTION | Строка(max) | Дополнительно об источнике |
| SOURCE_ID | Строка | Идентификатор источника |
| STAGE_ID | Строка | Идентификатор этапа сделки |
| STAGE_SEMANTIC_ID | Строка(max) | Имя |
| TAX_VALUE | Число | Ставка налога |
| TITLE | Строка(max) | Название сделки. Обязательное поле. |
| TYPE_ID | Строка | Идентификатор типа сделки |
| UTM_CAMPAIGN | Строка(max) | Обозначение рекламной кампании |
| UTM_CONTENT | Строка(max) | Содержание кампании |
| UTM_MEDIUM | Строка(max) | Тип трафика |
| UTM_SOURCE | Строка(max) | Рекламная система |
| UTM_TERM | Строка(max) | Условие поиска кампании |
Таблица Сделки.Дела
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| ASSOCIATED_ENTITY_ID | Число | Идентификатор связанной с делом сущности |
| AUTHOR_ID | Число | Создатель дела |
| AUTOCOMPLETE_RULE | Число | Автозаполнение |
| BINDINGS | Строка(max) | Привязки |
| COMMUNICATIONS | Строка(max) | Канал коммуникации |
| COMPLETED | Строка | Завершено |
| CREATED | Дата и время | Создано |
| DEADLINE | Дата и время | Срок исполнения |
| DESCRIPTION | Строка(max) | Описание |
| DESCRIPTION_TYPE | Строка(max) | Тип описания |
| DIRECTION | Строка(max) | Направление дела: входящее/исходящее. |
| EDITOR_ID | Число | Кто изменил |
| END_TIME | Дата и время | Время завершения |
| FILES | Строка(max) | Добавленные файлы |
| IS_INCOMING_CHANNEL | Строка | IS_INCOMING_CHANNEL |
| LAST_UPDATED | Дата и время | Дата последнего обновления |
| LOCATION | Строка(max) | Местоположение |
| NOTIFY_TYPE | Строка(max) | Тип уведомлений |
| NOTIFY_VALUE | Число | Параметр уведомления |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE_ID | Строка(max) | Тип собственника |
| PRIORITY | Строка(max) | Приоритет |
| PROVIDER_DATA | Строка(max) | Данные провайдера |
| PROVIDER_GROUP_ID | Строка(max) | Тип коннектора |
| PROVIDER_ID | Строка(max) | Идентификатор провайдера |
| PROVIDER_PARAMS | Строка(max) | Параметры провайдера |
| PROVIDER_TYPE_ID | Строка(max) | Идентификатор типа провайдера |
| RESPONSIBLE_ID | Число | Ответстветнный |
| RESULT_CURRENCY_ID | Строка(max) | RESULT_CURRENCY_ID |
| RESULT_MARK | Число | RESULT_MARK |
| RESULT_SOURCE_ID | Строка(max) | RESULT_SOURCE_ID |
| RESULT_STATUS | Число | RESULT_STATUS |
| RESULT_STREAM | Число | Статистика отчётов |
| RESULT_SUM | Число | RESULT_SUM |
| RESULT_VALUE | Число | RESULT_VALUE |
| SETTINGS | Строка(max) | Настройки |
| START_TIME | Дата и время | Время начала выполнения |
| STATUS | Строка(max) | Статус |
| SUBJECT | Строка(max) | Субьект |
| TYPE_ID | Строка(max) | Идентификатор типа сделки |
| WEBDAV_ELEMENTS | Строка(max) | Добавленные файлы |
Таблица Сделки.Контакты
| Имя | ТИП | Описание поля |
|---|---|---|
| CONTACT_ID | Число | Идентификатор контактного лица |
| IS_PRIMARY | Строка | Первичный |
| OWNER_ID | Число | Собственник |
| SORT | Число | Сортировка |
Таблица Сделки.Направления
| Имя | ТИП | Описание поля |
|---|---|---|
| entityTypeId | Число | ENTITY_TYPE_ID |
| id | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| isDefault | Строка(max) | IS_DEFAULT |
| name | Строка(max) | Имя контакта |
| originatorId | Строка(max) | ORIGINATOR_ID |
| originId | Строка(max) | ORIGIN_ID |
| sort | Число | Сортировка |
Таблица Сделки.ТоварныеПозиции
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| CUSTOMIZED | Строка | Изменен |
| DISCOUNT_RATE | Число | Величина скидки |
| DISCOUNT_SUM | Число | Сумма скидки |
| DISCOUNT_TYPE_ID | Число | Тип скидки |
| MEASURE_CODE | Число | Код единицы измерения |
| MEASURE_NAME | Строка(max) | Единица измерения |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE | Строка(max) | Тип владельца |
| PRICE | Число | Цена |
| PRICE_BRUTTO | Число | PRICE_BRUTTO |
| PRICE_EXCLUSIVE | Число | Цена без налога со скидкой |
| PRICE_NETTO | Число | PRICE_NETTO |
| PRODUCT_ID | Число | Товар |
| PRODUCT_NAME | Строка(max) | Название товара |
| QUANTITY | Число | Количество |
| SORT | Число | Сортировка |
| TAX_INCLUDED | Строка | Налог включен в цену |
| TAX_RATE | Число | Налог |
| TYPE | Число | TYPE |
Таблица Сделки.Справочник_Воронки продаж
| Имя | ТИП | Описание поля |
|---|---|---|
| ENTITY_TYPE_ID | Число | Тип родительской сущности. Возможные типы: “Компания”, “Контакт”. Обязательное поле. |
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД |
| IS_DEFAULT | Строка(max) | IS_DEFAULT |
| NAME | Строка(max) | Имя контакта |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком |
| SORT | Число | Сортировка |
Подраздел “Контрагенты”
Таблица Банковские реквизиты
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор реквизита. Создается автоматически и уникален в рамках БД. |
| ACTIVE | Строка | Признак активности |
| CODE | Строка(max) | Символьный код реквизита |
| COMMENTS | Строка(max) | Комментарий |
| COUNTRY_ID | Число | Идентификатор страны |
| CREATED_BY_ID | Число | Идентификатор создавшего реквизит |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| MODIFY_BY_ID | Число | Идентификатор изменившего реквизит |
| NAME | Строка(max) | Название реквизита |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| RQ_ACC_CURRENCY | Строка(max) | Валюта счёта |
| RQ_ACC_NAME | Строка(max) | Bank Account Holder Name |
| RQ_ACC_NUM | Строка(max) | Bank Account Number |
| RQ_ACC_TYPE | Строка(max) | RQ_ACC_TYPE |
| RQ_AGENCY_NAME | Строка(max) | RQ_AGENCY_NAME |
| RQ_BANK_ADDR | Строка(max) | Адрес банка |
| RQ_BANK_CODE | Строка(max) | RQ_BANK_CODE |
| RQ_BANK_NAME | Строка(max) | Наименование банка |
| RQ_BANK_ROUTE_NUM | Строка(max) | Bank Routing Number |
| RQ_BIC | Строка(max) | BIC |
| RQ_BIK | Строка(max) | БИК |
| RQ_CODEB | Строка(max) | RQ_CODEB |
| RQ_CODEG | Строка(max) | RQ_CODEG |
| RQ_COR_ACC_NUM | Строка(max) | Кор счёт |
| RQ_IBAN | Строка(max) | IBAN |
| RQ_IIK | Строка(max) | ИИК |
| RQ_MFO | Строка(max) | МФО |
| RQ_RIB | Строка(max) | RQ_RIB |
| RQ_SWIFT | Строка(max) | SWIFT |
| SORT | Число | Сортировка |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Таблица Компании
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS | Строка(max) | Улица, дом, корпус, строение (фактический адрес) |
| ADDRESS_2 | Строка(max) | Квартира / офис (фактический адрес) |
| ADDRESS_CITY | Строка(max) | Город (фактический адрес) |
| ADDRESS_COUNTRY | Строка(max) | Страна (фактический адрес) |
| ADDRESS_COUNTRY_CODE | Строка(max) | Код Страны (фактический адрес) |
| ADDRESS_LEGAL | Строка(max) | Юридический адрес |
| ADDRESS_LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| ADDRESS_POSTAL_CODE | Строка(max) | Почтовый индекс (фактический адрес) |
| ADDRESS_PROVINCE | Строка(max) | Область (фактический адрес) |
| ADDRESS_REGION | Строка(max) | Район (фактический адрес) |
| ASSIGNED_BY_ID | Число | Идентификатор ответственного |
| BANKING_DETAILS | Строка(max) | Банковские реквизиты |
| COMMENTS | Строка(max) | Комментарии |
| COMPANY_TYPE | Строка | Тип компании. Выбирается из списка |
| CONTACT_ID | Число | Привязка лида к контакту |
| CREATED_BY_ID | Число | Создал |
| CURRENCY_ID | Строка | Валюта расчетов |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| Строка(max) | ||
| EMPLOYEES | Строка | Количество сотрудников. Выбирается из списка |
| HAS_EMAIL | Строка | Проверка заполненности поля электронной почты |
| HAS_IMOL | Строка | Задана открытая линия |
| HAS_PHONE | Строка | Проверка заполненности поля телефон |
| ID | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| IM | Строка(max) | Контакт в службе обмена мгновенными сообщениями |
| INDUSTRY | Строка | Сфера деятельности. Выбирается из списка. |
| IS_MY_COMPANY | Строка | Моя компания |
| LAST_ACTIVITY_BY | Число | Кем осуществлена последняя активность в таймлайне |
| LAST_ACTIVITY_TIME | Дата и время | Последняя активность |
| LEAD_ID | Число | Идентификатор лида |
| LINK | Строка(max) | LINK |
| LOGO | Строка(max) | Логотип компании |
| MODIFY_BY_ID | Число | Изменил |
| OPENED | Строка | Флаг “Доступна для всех” |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGIN_VERSION | Строка(max) | Оригинальная версия |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| PHONE | Строка(max) | PHONE |
| REG_ADDRESS | Строка(max) | Улица, дом, корпус, строение (юридический адрес) |
| REG_ADDRESS_2 | Строка(max) | Квартира / офис (юридический адрес) |
| REG_ADDRESS_CITY | Строка(max) | Город (юридический адрес) |
| REG_ADDRESS_COUNTRY | Строка(max) | Страна (юридический адрес) |
| REG_ADDRESS_COUNTRY_CODE | Строка(max) | Код Страны (юридический адрес) |
| REG_ADDRESS_LOC_ADDR_ID | Число | Юридический адрес идентификатор адреса местоположения |
| REG_ADDRESS_POSTAL_CODE | Строка(max) | Почтовый индекс (юридический адрес) |
| REG_ADDRESS_PROVINCE | Строка(max) | Область (юридический адрес) |
| REG_ADDRESS_REGION | Строка(max) | Район (юридический адрес) |
| REVENUE | Число | Годовой оборот |
| TITLE | Строка(max) | Название компании. Обязательное поле.. |
| UTM_CAMPAIGN | Строка(max) | Обозначение рекламной кампании |
| UTM_CONTENT | Строка(max) | Содержание кампании |
| UTM_MEDIUM | Строка(max) | Тип трафика |
| UTM_SOURCE | Строка(max) | Рекламная система |
| UTM_TERM | Строка(max) | Условие поиска кампании |
| WEB | Строка(max) | веб-сайт |
Таблица Компании.Адреса
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS_1 | Строка(max) | Улица, дом, корпус, строение. |
| ADDRESS_2 | Строка(max) | Квартира / офис. |
| ANCHOR_ID | Число | Примечание. Эти поля для служебного использования. Они нужны для решения задачи производительности в выборках по старшим сущностям (Компаниям/Контактам) в элементах CRM, которые с ними напрямую не связаны, а связаны опосредовано через другой элемент CRM. При добавлении записи Адреса обязательно указывается непосредственная привязка адреса к старшей сущности - ENTITY_ID, ENTITY_TYPE_ID . Например, это Реквизит. Но в поля записи Адреса ANCHOR_TYPE_ID и ANCHOR_ID автоматически проставится привязка к более старшей сущности самого Реквизита - Компании/Клиенту. |
| ANCHOR_TYPE_ID | Число | Родительская сущность, с которой связана текущая запись. |
| CITY | Строка(max) | Город. |
| COUNTRY | Строка(max) | Страна. |
| COUNTRY_CODE | Строка(max) | Код страны. |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| ENTITY_TYPE_ID | Число | Тип родительской сущности. По умолчанию тип: “Реквизит”. Обязательное поле. |
| LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| POSTAL_CODE | Строка(max) | Почтовый индекс. |
| PROVINCE | Строка(max) | Область. |
| REGION | Строка(max) | Район. |
| TYPE_ID | Число | TYPE_ID |
Таблица Компании.Дела
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор реквизита. Создается автоматически и уникален в рамках БД. |
| ASSOCIATED_ENTITY_ID | Число | Идентификатор связанной с делом сущности |
| AUTHOR_ID | Число | Создатель дела |
| AUTOCOMPLETE_RULE | Число | Автозаполнение |
| BINDINGS | Строка(max) | Привязки |
| COMMUNICATIONS | Строка(max) | Канал коммуникации |
| COMPLETED | Строка | Завершено |
| CREATED | Дата и время | Создано |
| DEADLINE | Дата и время | Срок исполнения |
| DESCRIPTION | Строка(max) | Описание |
| DESCRIPTION_TYPE | Строка(max) | Тип описания |
| DIRECTION | Строка(max) | Направление дела: входящее/исходящее. |
| EDITOR_ID | Число | Кто изменил |
| END_TIME | Дата и время | Время завершения |
| FILES | Строка(max) | Добавленные файлы |
| IS_INCOMING_CHANNEL | Строка | IS_INCOMING_CHANNEL |
| LAST_UPDATED | Дата и время | Дата последнего обновления |
| LOCATION | Строка(max) | Местоположение. |
| NOTIFY_TYPE | Строка(max) | Тип уведомлений |
| NOTIFY_VALUE | Число | Параметр уведомления |
| ORIGIN_ID | Строка(max) | Идентификатор элемента в источнике данных |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE_ID | Строка(max) | Тип собственника |
| PRIORITY | Строка(max) | Приоритет |
| PROVIDER_DATA | Строка(max) | Данные провайдера |
| PROVIDER_GROUP_ID | Строка(max) | Тип коннектора |
| PROVIDER_ID | Строка(max) | Идентификатор провайдера |
| PROVIDER_PARAMS | Строка(max) | Параметры провайдера |
| PROVIDER_TYPE_ID | Строка(max) | Идентификатор типа провайдера |
| RESPONSIBLE_ID | Число | Ответстветнный |
| RESULT_CURRENCY_ID | Строка(max) | RESULT_CURRENCY_ID |
| RESULT_MARK | Число | RESULT_MARK |
| RESULT_SOURCE_ID | Строка(max) | RESULT_SOURCE_ID |
| RESULT_STATUS | Число | RESULT_STATUS |
| RESULT_STREAM | Число | Статистика отчётов |
| RESULT_SUM | Число | RESULT_SUM |
| RESULT_VALUE | Число | RESULT_VALUE |
| SETTINGS | Строка(max) | Настройки |
| START_TIME | Дата и время | Время начала выполнения |
| STATUS | Строка(max) | Статус |
| SUBJECT | Строка(max) | Субьект |
| TYPE_ID | Строка(max) | Идентификатор типа адреса. Обязательное поле. Элемент перечисления “Тип адреса”. |
| WEBDAV_ELEMENTS | Строка(max) | Добавленные файлы |
Таблица Компании.Контакты
| Имя | ТИП | Описание поля |
|---|---|---|
| CONTACT_ID | Число | Идентификатор контактного лица |
| IS_PRIMARY | Строка | Первичный |
| OWNER_ID | Число | Собственник |
| SORT | Число | Сортировка |
Таблица Компании.Направления
| Имя | ТИП | Описание поля |
|---|---|---|
| code | Строка(max) | Символьный код реквизита. |
| entityTypeId | Число | ENTITY_TYPE_ID |
| id | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| isDefault | Строка(max) | IS_DEFAULT |
| isSystem | Строка(max) | IS_SYSTEM |
| name | Строка(max) | Имя контакта. Обязательное поле |
| sort | Число | Сортировка. |
Таблица Компании.Реквизиты
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS_ONLY | Строка | ADDRESS_ONLY |
| RQ_EMAIL | Строка(max) | |
| RQ_USRLE | Строка(max) | Handelsregisternummer (для страны DE) |
| RQ_VAT_ID | Строка(max) | VAT ID (идентификационный номер (плательщика) НДС) |
| RQ_BIN | Строка(max) | БИН |
| RQ_IDENT_DOC | Строка(max) | Вид документа |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| RQ_DIRECTOR | Строка(max) | Ген директор |
| RQ_ACCOUNTANT | Строка(max) | Гл бухгалтер |
| RQ_IDENT_DOC_DATE | Строка(max) | дата выдачи |
| RQ_COMPANY_REG_DATE | Строка(max) | Дата государственной регистрации |
| DATE_MODIFY | Дата и время | Дата изменения |
| RQ_VAT_CERT_DATE | Строка(max) | Дата свидетельства по НДС |
| DATE_CREATE | Дата и время | Дата создания |
| RQ_CEO_WORK_POS | Строка(max) | Должность первого руководителя |
| RQ_DRFO | Строка(max) | ДРФО |
| RQ_EDRPOU | Строка(max) | ЄДРПОУ |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ID | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| PRESET_ID | Число | Идентификатор шаблона реквизитов. Обязательное поле. |
| MODIFY_BY_ID | Число | Изменил |
| RQ_IIN | Строка(max) | ИИН |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| RQ_FIRST_NAME | Строка(max) | Имя |
| RQ_INN | Строка(max) | ИНН |
| RQ_IFNS | Строка(max) | ИФНС |
| RQ_KBE | Строка(max) | КБЕ |
| RQ_IDENT_DOC_ISSUED_BY | Строка(max) | Кем выдан |
| RQ_IDENT_DOC_DEP_CODE | Строка(max) | Код подразделения |
| RQ_CONTACT | Строка(max) | Контактное лицо |
| RQ_KPP | Строка(max) | КПП |
| RQ_VAT_CERT_NUM | Строка(max) | Номер свидетельства по НДС |
| RQ_IDENT_DOC_NUM | Строка(max) | Номер |
| RQ_OGRN | Строка(max) | ОГРН |
| RQ_OGRNIP | Строка(max) | ОГРНИП |
| RQ_OKVED | Строка(max) | ОКВЭД |
| RQ_OKPO | Строка(max) | ОКПО |
| RQ_OKTMO | Строка(max) | ОКТМО |
| RQ_SECOND_NAME | Строка(max) | Отчество |
| RQ_VAT_PAYER | Строка | Платник ПДВ (для страны UA) |
| RQ_COMPANY_FULL_NAME | Строка(max) | Полное наименование организации |
| ACTIVE | Строка | Признак активности |
| RQ_VAT_CERT_SER | Строка(max) | Серия свидетельства по НДС |
| RQ_IDENT_DOC_SER | Строка(max) | серия |
| CODE | Строка(max) | Символьный код реквизита |
| CREATED_BY_ID | Число | Создал |
| RQ_COMPANY_NAME | Строка(max) | Сокращенное наименование организации |
| SORT | Число | Сортировка |
| RQ_RESIDENCE_COUNTRY | Строка(max) | Страна резидента |
| RQ_PHONE | Строка(max) | Телефон |
| ENTITY_TYPE_ID | Число | Тип родительской сущности. Возможные типы: “Компания”, “Контакт”. Обязательное поле. |
| RQ_NAME | Строка(max) | Ф.И.О. |
| RQ_FAX | Строка(max) | Факс |
| RQ_LAST_NAME | Строка(max) | Фамилия |
| RQ_CEO_NAME | Строка(max) | ФИО первого руководителя |
| RQ_BASE_DOC | Строка(max) | RQ_BASE_DOC |
| RQ_CAPITAL | Строка(max) | RQ_CAPITAL |
| RQ_CNPJ | Строка(max) | RQ_CNPJ |
| RQ_COMPANY_ID | Строка(max) | RQ_COMPANY_ID |
| RQ_CPF | Строка(max) | RQ_CPF |
| RQ_IDENT_DOC_PERS_NUM | Строка(max) | RQ_IDENT_DOC_PERS_NUM |
| RQ_IDENT_TYPE | Строка | RQ_IDENT_TYPE |
| RQ_KRS | Строка(max) | RQ_KRS |
| RQ_LEGAL_FORM | Строка(max) | RQ_LEGAL_FORM |
| RQ_MNPL_REG | Строка(max) | RQ_MNPL_REG |
| RQ_PESEL | Строка(max) | RQ_PESEL |
| RQ_RCS | Строка(max) | RQ_RCS |
| RQ_REGON | Строка(max) | RQ_REGON |
| RQ_SIREN | Строка(max) | RQ_SIREN |
| RQ_SIRET | Строка(max) | RQ_SIRET |
| RQ_STATE_REG | Строка(max) | RQ_STATE_REG |
| RQ_ST_CERT_DATE | Строка(max) | Дата св. о гос. регистрации |
| RQ_ST_CERT_NUM | Строка(max) | Номер св. о гос. регистрации |
| RQ_ST_CERT_SER | Строка(max) | Серия св. о гос. регистрации |
Таблица Контакты
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS | Строка(max) | Улица, дом, корпус, строение |
| ADDRESS_2 | Строка(max) | Квартира, офис |
| ADDRESS_CITY | Строка(max) | Город |
| ADDRESS_COUNTRY | Строка(max) | Страна |
| ADDRESS_COUNTRY_CODE | Строка(max) | Код страны |
| ADDRESS_LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| ADDRESS_POSTAL_CODE | Строка(max) | Почтовый индекс |
| ADDRESS_PROVINCE | Строка(max) | Область |
| ADDRESS_REGION | Строка(max) | Район |
| ASSIGNED_BY_ID | Число | Идентификатор ответственного |
| BIRTHDATE | Строка(max) | Дата рождения контакта |
| COMMENTS | Строка(max) | Комментарии |
| COMPANY_ID | Число | Идентификатор компании |
| COMPANY_IDS | Число | Привязка контакта к нескольким компаниям. |
| CREATED_BY_ID | Число | Создан |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| Строка(max) | ||
| EXPORT | Строка | Флаг разрешения экспорта |
| FACE_ID | Число | Привязка к лицам из модуля faceid |
| HAS_EMAIL | Строка | Проверка заполненности поля электронной почты |
| HAS_IMOL | Строка | Задана открытая линия |
| HAS_PHONE | Строка | Проверка заполненности поля телефон |
| HONORIFIC | Строка | Вид обращения |
| ID | Число | Идентификатор контакта. Создается автоматически и уникален в пределах БД |
| IM | Строка(max) | Контакт в службе обмена мгновенными сообщениями |
| LAST_ACTIVITY_BY | Число | Кем осуществлена последняя активность в таймлайне |
| LAST_ACTIVITY_TIME | Дата и время | Последняя активность |
| LAST_NAME | Строка(max) | Фамилия Контакта. Обязательное поле |
| LEAD_ID | Число | Идентификатор лида |
| LINK | Строка(max) | LINK |
| MODIFY_BY_ID | Число | Изменен |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| OPENED | Строка | Флаг “Доступен для всех” |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGIN_VERSION | Строка(max) | Оригинальная версия |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| PHONE | Строка(max) | PHONE |
| PHOTO | Строка(max) | Фотография контакта |
| POST | Строка(max) | Должность |
| SECOND_NAME | Строка(max) | Отчество контакта. Обязательное поле |
| SOURCE_DESCRIPTION | Строка(max) | Подробнее об источнике |
| SOURCE_ID | Строка | Источник |
| TYPE_ID | Строка | Тип контакта |
| UTM_CAMPAIGN | Строка(max) | Обозначение рекламной кампании |
| UTM_CONTENT | Строка(max) | Содержание кампании |
| UTM_MEDIUM | Строка(max) | Тип трафика |
| UTM_SOURCE | Строка(max) | Рекламная система |
| UTM_TERM | Строка(max) | Условие поиска кампании |
| WEB | Строка(max) | веб-сайт |
Таблица Контакты.Адреса
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS_1 | Строка(max) | Улица, дом, корпус, строение. |
| ADDRESS_2 | Строка(max) | Квартира, офис |
| ANCHOR_ID | Число | Примечание. Эти поля для служебного использования. Они нужны для решения задачи производительности в выборках по старшим сущностям (Компаниям/Контактам) в элементах CRM, которые с ними напрямую не связаны, а связаны опосредовано через другой элемент CRM. При добавлении записи Адреса обязательно указывается непосредственная привязка адреса к старшей сущности - ENTITY_ID, ENTITY_TYPE_ID . Например, это Реквизит. Но в поля записи Адреса ANCHOR_TYPE_ID и ANCHOR_ID автоматически проставится привязка к более старшей сущности самого Реквизита - Компании/Клиенту. |
| ANCHOR_TYPE_ID | Число | Родительская сущность, с которой связана текущая запись. |
| CITY | Строка(max) | Город. |
| COUNTRY | Строка(max) | Страна. |
| COUNTRY_CODE | Строка(max) | Код страны. |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| ENTITY_TYPE_ID | Число | Тип родительской сущности. Возможные типы: “Компания”, “Контакт”. Обязательное поле. |
| LOC_ADDR_ID | Число | Идентификатор адреса местоположения |
| POSTAL_CODE | Строка(max) | Почтовый индекс |
| PROVINCE | Строка(max) | Область |
| REGION | Строка(max) | Район |
| TYPE_ID | Число | Тип контакта |
Таблица Контакты.Дела
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор контакта. Создается автоматически и уникален в пределах БД |
| ASSOCIATED_ENTITY_ID | Число | Идентификатор связанной с делом сущности |
| AUTHOR_ID | Число | Создатель дела |
| AUTOCOMPLETE_RULE | Число | Автозаполнение |
| BINDINGS | Строка(max) | Привязки |
| COMMUNICATIONS | Строка(max) | Канал коммуникации |
| COMPLETED | Строка | Завершено |
| CREATED | Дата и время | Создано |
| DEADLINE | Дата и время | Срок исполнения |
| DESCRIPTION | Строка(max) | Описание |
| DESCRIPTION_TYPE | Строка(max) | Тип описания |
| DIRECTION | Строка(max) | Направление дела: входящее/исходящее. |
| EDITOR_ID | Число | Кто изменил |
| END_TIME | Дата и время | Время завершения |
| FILES | Строка(max) | Добавленные файлы |
| IS_INCOMING_CHANNEL | Строка | IS_INCOMING_CHANNEL |
| LAST_UPDATED | Дата и время | Дата последнего обновления |
| LOCATION | Строка(max) | Местоположение. |
| NOTIFY_TYPE | Строка(max) | Тип уведомлений |
| NOTIFY_VALUE | Число | Параметр уведомления |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE_ID | Строка(max) | Тип собственника |
| PRIORITY | Строка(max) | Приоритет |
| PROVIDER_DATA | Строка(max) | Данные провайдера |
| PROVIDER_GROUP_ID | Строка(max) | Тип коннектора |
| PROVIDER_ID | Строка(max) | Идентификатор провайдера |
| PROVIDER_PARAMS | Строка(max) | Параметры провайдера |
| PROVIDER_TYPE_ID | Строка(max) | Идентификатор типа провайдера |
| RESPONSIBLE_ID | Число | Ответстветнный |
| RESULT_CURRENCY_ID | Строка(max) | RESULT_CURRENCY_ID |
| RESULT_MARK | Число | RESULT_MARK |
| RESULT_SOURCE_ID | Строка(max) | RESULT_SOURCE_ID |
| RESULT_STATUS | Число | RESULT_STATUS |
| RESULT_STREAM | Число | Статистика отчётов |
| RESULT_SUM | Число | RESULT_SUM |
| RESULT_VALUE | Число | RESULT_VALUE |
| SETTINGS | Строка(max) | Настройки |
| START_TIME | Дата и время | Время начала выполнения |
| STATUS | Строка(max) | Статус |
| SUBJECT | Строка(max) | Субьект |
| TYPE_ID | Строка(max) | Тип контакта |
| WEBDAV_ELEMENTS | Строка(max) | Добавленные файлы |
Таблица Контакты.Направления
| Имя | ТИП | Описание поля |
|---|---|---|
| code | Строка(max) | Символьный код реквизита. |
| entityTypeId | Число | ENTITY_TYPE_ID |
| id | Число | Идентификатор контакта. Создается автоматически и уникален в пределах БД |
| isDefault | Строка(max) | IS_DEFAULT |
| isSystem | Строка(max) | IS_SYSTEM |
| name | Строка(max) | Имя контакта. Обязательное поле |
| sort | Число | Сортировка. |
Таблица Контакты.Реквизиты
| Имя | ТИП | Описание поля |
|---|---|---|
| ADDRESS_ONLY | Строка | ADDRESS_ONLY |
| ACTIVE | Строка | Признак активности |
| CODE | Строка(max) | Символьный код реквизита. |
| CREATED_BY_ID | Число | Создан |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| ENTITY_ID | Число | Идентификатор родительской сущности. Обязательное поле. |
| ENTITY_TYPE_ID | Число | Тип родительской сущности. Возможные типы: “Компания”, “Контакт”. Обязательное поле. |
| ID | Число | Идентификатор контакта. Создается автоматически и уникален в пределах БД |
| MODIFY_BY_ID | Число | Изменен |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| PRESET_ID | Число | Идентификатор шаблона реквизитов. Обязательное поле. |
| RQ_ACCOUNTANT | Строка(max) | Гл. бухгалтер. |
| RQ_BASE_DOC | Строка(max) | RQ_BASE_DOC |
| RQ_BIN | Строка(max) | БИН |
| RQ_CAPITAL | Строка(max) | RQ_CAPITAL |
| RQ_CEO_NAME | Строка(max) | ФИО первого руководителя. |
| RQ_CEO_WORK_POS | Строка(max) | Должность первого руководителя. |
| RQ_CNPJ | Строка(max) | RQ_CNPJ |
| RQ_COMPANY_FULL_NAME | Строка(max) | Полное наименование организации. |
| RQ_COMPANY_ID | Строка(max) | RQ_COMPANY_ID |
| RQ_COMPANY_NAME | Строка(max) | Сокращенное наименование организации. |
| RQ_COMPANY_REG_DATE | Строка(max) | Дата государственной регистрации. |
| RQ_CONTACT | Строка(max) | Контактное лицо |
| RQ_CPF | Строка(max) | RQ_CPF |
| RQ_DIRECTOR | Строка(max) | Ген директор |
| RQ_DRFO | Строка(max) | ДРФО |
| RQ_EDRPOU | Строка(max) | ЄДРПОУ |
| RQ_EMAIL | Строка(max) | |
| RQ_FAX | Строка(max) | Факс |
| RQ_FIRST_NAME | Строка(max) | Имя |
| RQ_IDENT_DOC | Строка(max) | Вид документа |
| RQ_IDENT_DOC_DATE | Строка(max) | Дата выдачи |
| RQ_IDENT_DOC_DEP_CODE | Строка(max) | Код подразделения |
| RQ_IDENT_DOC_ISSUED_BY | Строка(max) | Кем выдан |
| RQ_IDENT_DOC_NUM | Строка(max) | Номер |
| RQ_IDENT_DOC_PERS_NUM | Строка(max) | RQ_IDENT_DOC_PERS_NUM |
| RQ_IDENT_DOC_SER | Строка(max) | Серия |
| RQ_IDENT_TYPE | Строка | RQ_IDENT_TYPE |
| RQ_IFNS | Строка(max) | ИФНС |
| RQ_IIN | Строка(max) | ИИН |
| RQ_INN | Строка(max) | ИНН |
| RQ_KBE | Строка(max) | КБЕ |
| RQ_KPP | Строка(max) | КПП |
| RQ_KRS | Строка(max) | RQ_KRS |
| RQ_LAST_NAME | Строка(max) | Фамилия |
| RQ_LEGAL_FORM | Строка(max) | RQ_LEGAL_FORM |
| RQ_MNPL_REG | Строка(max) | RQ_MNPL_REG |
| RQ_NAME | Строка(max) | ФИО |
| RQ_OGRN | Строка(max) | ОГРН |
| RQ_OGRNIP | Строка(max) | ОГРНИП |
| RQ_OKPO | Строка(max) | ОКПО |
| RQ_OKTMO | Строка(max) | ОКТМО |
| RQ_OKVED | Строка(max) | ОКВЭД |
| RQ_PESEL | Строка(max) | RQ_PESEL |
| RQ_PHONE | Строка(max) | Телефон |
| RQ_RCS | Строка(max) | RQ_RCS |
| RQ_REGON | Строка(max) | RQ_REGON |
| RQ_RESIDENCE_COUNTRY | Строка(max) | Страна резидента |
| RQ_SECOND_NAME | Строка(max) | Отчество |
| RQ_SIREN | Строка(max) | RQ_SIREN |
| RQ_SIRET | Строка(max) | RQ_SIRET |
| RQ_ST_CERT_DATE | Строка(max) | Дата св о гос регистрации |
| RQ_ST_CERT_NUM | Строка(max) | Номер св о гос регистрации |
| RQ_ST_CERT_SER | Строка(max) | Серия св о гос регистрации |
| RQ_STATE_REG | Строка(max) | RQ_STATE_REG |
| RQ_USRLE | Строка(max) | Handelsregisternummer (для страны DE) |
| RQ_VAT_CERT_DATE | Строка(max) | Дата свидетельства по НДС |
| RQ_VAT_CERT_NUM | Строка(max) | Номер свидетельства по НДС |
| RQ_VAT_CERT_SER | Строка(max) | Серия свидетельства по НДС |
| RQ_VAT_ID | Строка(max) | VAT ID (идентификационный номер (плательщика) НДС) |
| RQ_VAT_PAYER | Строка | Платник ПДВ (для страны UA) |
| SORT | Число | Сортировка |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Подраздел “Продажи”
Таблица КоммерческиеПредложения
| Имя | ТИП | Описание поля |
|---|---|---|
| ACTUAL_DATE | Строка(max) | Актуальная дата |
| ASSIGNED_BY_ID | Число | Идентификатор ответственного за сделку |
| BEGINDATE | Строка(max) | Дата открытия сделки |
| CLIENT_ADDR | Строка(max) | Адрес |
| CLIENT_CONTACT | Строка(max) | Контактное лицо |
| CLIENT_EMAIL | Строка(max) | |
| CLIENT_PHONE | Строка(max) | Телефон |
| CLIENT_TITLE | Строка(max) | Клиент |
| CLIENT_TP_ID | Строка(max) | ИНН |
| CLIENT_TPA_ID | Строка(max) | КПП |
| CLOSED | Строка | Флаг “Сделка закрыта” |
| CLOSEDATE | Строка(max) | Дата закрытия сделки |
| COMMENTS | Строка(max) | Комментарии |
| COMPANY_ID | Число | Идентификатор компании-контрагента сделки |
| CONTACT_ID | Число | Идентификатор контактного лица |
| CONTACT_IDS | Число | Идентификатор привязанного контакта |
| CONTENT | Строка(max) | Содержание |
| CREATED_BY_ID | Число | Идентификатор создавшего сделку |
| CURRENCY_ID | Строка | Валюта сделки |
| DATE_CREATE | Дата и время | Дата создания |
| DATE_MODIFY | Дата и время | Дата изменения |
| DEAL_ID | Число | Сделка |
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| LAST_ACTIVITY_BY | Число | LAST_ACTIVITY_BY |
| LAST_ACTIVITY_TIME | Дата и время | LAST_ACTIVITY_TIME |
| LEAD_ID | Число | Идентификатор лида |
| LOCATION_ID | Строка(max) | Местоположение клиента |
| MODIFY_BY_ID | Число | Идентификатор изменившего сделку |
| MYCOMPANY_ID | Число | Идентификатор моей компании. |
| OPENED | Строка | Флаг “Сделка доступна для всех” |
| OPPORTUNITY | Число | Сумма в валюте сделки |
| PERSON_TYPE_ID | Число | Тип клиента |
| QUOTE_NUMBER | Строка(max) | № предложения |
| STATUS_ID | Строка | Идентификатор статуса лида |
| TAX_VALUE | Число | Ставка налога |
| TERMS | Строка(max) | Условия |
| TITLE | Строка(max) | Название сделки. Обязательное поле. |
| UTM_CAMPAIGN | Строка(max) | Обозначение рекламной кампании |
| UTM_CONTENT | Строка(max) | Содержание кампании |
| UTM_MEDIUM | Строка(max) | Тип трафика |
| UTM_SOURCE | Строка(max) | Рекламная система |
| UTM_TERM | Строка(max) | Условие поиска кампании |
Таблица КоммерческиеПредложения.ТоварныеПозиции
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| CUSTOMIZED | Строка | Изменен |
| DISCOUNT_RATE | Число | Величина скидки |
| DISCOUNT_SUM | Число | Сумма скидки |
| DISCOUNT_TYPE_ID | Число | Тип скидки |
| MEASURE_CODE | Число | Код единицы измерения |
| MEASURE_NAME | Строка(max) | Единица измерения |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE | Строка(max) | Тип владельца |
| PRICE | Число | Цена |
| PRICE_BRUTTO | Число | PRICE_BRUTTO |
| PRICE_EXCLUSIVE | Число | Цена без налога со скидкой |
| PRICE_NETTO | Число | PRICE_NETTO |
| PRODUCT_ID | Число | Товар |
| PRODUCT_NAME | Строка(max) | Название товара |
| QUANTITY | Число | Количество |
| SORT | Число | Сортировка |
| TAX_INCLUDED | Строка | Налог включен в цену |
| TAX_RATE | Число | Налог |
| TYPE | Число | TYPE |
Таблица Счета(старые)
| Имя | ТИП | Описание поля |
|---|---|---|
| ACCOUNT_NUMBER | Строка(max) | Номер |
| COMMENTS | Строка(max) | Комментарии |
| CREATED_BY | Число | ID пользователя, создавшего элемент. |
| CURRENCY | Строка(max) | Идентификатор валюты |
| DATE_BILL | Строка(max) | Дата выставления |
| DATE_INSERT | Дата и время | Дата создания |
| DATE_MARKED | Дата и время | Дата отклонения |
| DATE_PAY_BEFORE | Строка(max) | Срок оплаты |
| DATE_PAYED | Дата и время | Дата перевода в состояние оплаты |
| DATE_STATUS | Дата и время | Дата изменения статуса |
| DATE_UPDATE | Дата и время | Дата изменения |
| EMP_PAYED_ID | Число | Идентификатор пользователя, который последним перевёл счёт в состояние “оплачен” |
| EMP_STATUS_ID | Число | Идентификатор пользователя, который последним поменял статус счёта |
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| INVOICE_PROPERTIES | Строка(max) | Список свойств |
| IS_RECURRING | Строка(max) | Флаг шаблона регулярной сделки (если стоит Y, то это не сделка, а шаблон) |
| LID | Строка(max) | Идентификатор сайта |
| ORDER_TOPIC | Строка(max) | Тема |
| PAY_SYSTEM_ID | Число | Идентификатор печатной формы |
| PAY_VOUCHER_DATE | Строка(max) | Дата оплаты |
| PAY_VOUCHER_NUM | Строка(max) | Номер документа оплаты |
| PAYED | Строка(max) | Признак оплаченности |
| PERSON_TYPE_ID | Число | Идентификатор типа плательщика |
| PR_LOCATION | Число | Идентификатор местоположения |
| PRICE | Число | Сумма |
| PRODUCT_ROWS | Строка(max) | Список товарных позиций |
| REASON_MARKED | Строка(max) | Комментарий статуса |
| RESPONSIBLE_EMAIL | Строка(max) | E-mail ответственного |
| RESPONSIBLE_ID | Число | Ответстветнный |
| RESPONSIBLE_LAST_NAME | Строка(max) | Фамилия ответственного |
| RESPONSIBLE_LOGIN | Строка(max) | Логин ответственного |
| RESPONSIBLE_NAME | Строка(max) | Имя ответственного |
| RESPONSIBLE_PERSONAL_PHOTO | Число | Идентификатор фото ответственного |
| RESPONSIBLE_SECOND_NAME | Строка(max) | Отчество ответственного |
| RESPONSIBLE_WORK_POSITION | Строка(max) | Должность ответственного |
| STATUS_ID | Строка(max) | Идентификатор статуса лида |
| TAX_VALUE | Число | Ставка налога |
| UF_COMPANY_ID | Число | Идентификатор компании |
| UF_CONTACT_ID | Число | Идентификатор контакта |
| UF_DEAL_ID | Число | Идентификатор связанной сделки |
| UF_MYCOMPANY_ID | Число | Идентификатор своей компании |
| UF_QUOTE_ID | Число | UF_QUOTE_ID |
| USER_DESCRIPTION | Строка(max) | Комментарий |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Таблица Счета(старые).ТоварныеПозиции
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор |
| CUSTOMIZED | Строка | Изменен |
| DISCOUNT_RATE | Число | Величина скидки |
| DISCOUNT_SUM | Число | Сумма скидки |
| DISCOUNT_TYPE_ID | Число | Тип скидки |
| MEASURE_CODE | Число | Код единицы измерения |
| MEASURE_NAME | Строка(max) | Единица измерения |
| OWNER_ID | Число | Собственник |
| OWNER_TYPE | Строка(max) | Тип владельца |
| PRICE | Число | Сумма |
| PRICE_BRUTTO | Число | PRICE_BRUTTO |
| PRICE_EXCLUSIVE | Число | Цена без налога со скидкой |
| PRICE_NETTO | Число | PRICE_NETTO |
| PRODUCT_ID | Число | Товар |
| PRODUCT_NAME | Строка(max) | Название товара |
| QUANTITY | Число | Количество |
| SORT | Число | Сортировка |
| TAX_INCLUDED | Строка | Налог включен в цену |
| TAX_RATE | Число | Налог |
| TYPE | Число | TYPE |
Подраздел “Товары”
Таблица Товары
| Имя | ТИП | Описание поля |
|---|---|---|
| ACTIVE | Строка | Признак активности. |
| CATALOG_ID | Число | Каталог |
| CODE | Строка(max) | Символьный код реквизита. |
| CREATED_BY | Число | ID пользователя, создавшего элемент. |
| CURRENCY_ID | Строка(max) | Валюта расчетов |
| DATE_CREATE | Дата и время | Дата создания |
| DESCRIPTION | Строка(max) | Описание |
| DESCRIPTION_TYPE | Строка(max) | Тип описания |
| DETAIL_PICTURE | Строка(max) | Детальная картинка |
| ID | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| MEASURE | Число | Единица измерения |
| MODIFIED_BY | Число | Кем изменён |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| PREVIEW_PICTURE | Строка(max) | Картинка для анонса |
| PRICE | Число | Сумма |
| PROPERTY_400 | Строка(max) | Наименование ПО |
| SECTION_ID | Число | Раздел |
| SORT | Число | Сортировка |
| TIMESTAMP_X | Дата и время | Дата изменения |
| VAT_ID | Число | Ставка НДС |
| VAT_INCLUDED | Строка | НДС включён в цену |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Таблица Каталог
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| ORIGIN_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| ORIGINATOR_ID | Строка(max) | Идентификатор внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Таблица РазделыТоваров
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор компании. Создается автоматически и уникален в рамках БД. |
| CATALOG_ID | Число | Каталог |
| CODE | Строка(max) | Символьный код реквизита. |
| NAME | Строка(max) | Имя контакта. Обязательное поле |
| SECTION_ID | Число | Раздел |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Подраздел “Справочники”
Таблица Валюты
| Имя | ТИП | Описание поля |
|---|---|---|
| AMOUNT | Число | Номинал |
| AMOUNT_CNT | Число | Курс обмена |
| BASE | Строка | Базовая валюта |
| CURRENCY | Строка(max) | Идентификатор валюты |
| DATE_UPDATE | Дата и время | Дата изменения |
| DEC_POINT | Строка(max) | Десятичная точка при выводе |
| DECIMALS | Число | Количество десятичных знаков |
| FORMAT_STRING | Строка(max) | Строка формата для вывода валюты |
| FULL_NAME | Строка(max) | Название |
| LANG | Строка(max) | Привязка к языку |
| LID | Строка(max) | Идентификатор сайта |
| SORT | Число | Сортировка |
| THOUSANDS_SEP | Строка(max) | Свой разделитель тысяч при выводе |
Таблица Единицы измерения
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор сделки. Создается автоматически и уникален в рамках БД. |
| CODE | Число | Символьный код реквизита. |
| IS_DEFAULT | Строка | По умолчанию |
| MEASURE_TITLE | Строка(max) | Наименование единицы измерения |
| SYMBOL_INTL | Строка(max) | Условное обозначение (международное) |
| SYMBOL_LETTER_INTL | Строка(max) | Кодовое буквенное обозначение (международное) |
| SYMBOL_RUS | Строка(max) | Условное обозначение |
Таблица Ставки НДС
| Имя | ТИП | Описание поля |
|---|---|---|
| ID | Число | Идентификатор реквизита. Создается автоматически и уникален в рамках БД. |
| ACTIVE | Строка(max) | Признак активности. |
| C_SORT | Число | Сортировка |
| NAME | Строка(max) | Имя контакта |
| RATE | Число | Ставка |
| TIMESTAMP_X | Дата и время | Дата изменения |
Таблица Пользователи
| Имя | ТИП | Описание поля |
|---|---|---|
| ACTIVE | Строка(max) | Признак активности. |
| DATE_REGISTER | Строка(max) | Дата регистрации |
| Строка(max) | ||
| ID | Строка(max) | Идентификатор контакта. Создается автоматически и уникален в пределах БД |
| IS_ONLINE | Строка(max) | IS_ONLINE |
| LAST_ACTIVITY_DATE | Строка(max) | LAST_ACTIVITY_DATE |
| LAST_LOGIN | Строка(max) | Последняя авторизация |
| LAST_NAME | Строка(max) | Фамилия |
| NAME | Строка(max) | Имя |
| PERSONAL_BIRTHDAY | Строка(max) | Дата рождения |
| PERSONAL_CITY | Строка(max) | Город проживания |
| PERSONAL_COUNTRY | Строка(max) | Страна |
| PERSONAL_FAX | Строка(max) | Факс |
| PERSONAL_GENDER | Строка(max) | Пол |
| PERSONAL_ICQ | Строка(max) | ICQ |
| PERSONAL_MAILBOX | Строка(max) | Почтовый ящик |
| PERSONAL_MOBILE | Строка(max) | Личный мобильный |
| PERSONAL_NOTES | Строка(max) | Дополнительные заметки |
| PERSONAL_PAGER | Строка(max) | Пейджер |
| PERSONAL_PHONE | Строка(max) | Личный телефон |
| PERSONAL_PHOTO | Строка(max) | Фотография |
| PERSONAL_PROFESSION | Строка(max) | Профессия |
| PERSONAL_STATE | Строка(max) | Область / край |
| PERSONAL_STREET | Строка(max) | Улица проживания |
| PERSONAL_WWW | Строка(max) | Домашняя страничка |
| PERSONAL_ZIP | Строка(max) | Почтовый индекс |
| SECOND_NAME | Строка(max) | Отчество контакта |
| TIME_ZONE | Строка(max) | TIME_ZONE |
| TIME_ZONE_OFFSET | Строка(max) | TIME_ZONE_OFFSET |
| TIMESTAMP_X | Строка(max) | TIMESTAMP_X |
| TITLE | Строка(max) | Список пользователей |
| UF_DEPARTMENT | Строка(max) | Подразделения |
| UF_DISTRICT | Строка(max) | Район |
| UF_EMPLOYMENT_DATE | Строка(max) | Дата принятия на работу |
| UF_FACEBOOK | Строка(max) | |
| UF_INTERESTS | Строка(max) | Интересы |
| UF_LINKEDIN | Строка(max) | |
| UF_PHONE_INNER | Строка(max) | Внутренний телефон |
| UF_SKILLS | Строка(max) | Навыки |
| UF_SKYPE | Строка(max) | Логин Skype |
| UF_SKYPE_LINK | Строка(max) | Ссылка на чат в Skype |
| UF_TIMEMAN | Строка(max) | Учет рабочего времени |
| UF_TWITTER | Строка(max) | |
| UF_WEB_SITES | Строка(max) | Другие сайты |
| UF_XING | Строка(max) | |
| UF_ZOOM | Строка(max) | Zoom |
| USER_TYPE | Строка(max) | USER_TYPE |
| WORK_CITY | Строка(max) | Город работы |
| WORK_COMPANY | Строка(max) | Компания |
| WORK_COUNTRY | Строка(max) | WORK_COUNTRY |
| WORK_DEPARTMENT | Строка(max) | Отдел |
| WORK_FAX | Строка(max) | WORK_FAX |
| WORK_LOGO | Строка(max) | WORK_LOGO |
| WORK_MAILBOX | Строка(max) | WORK_MAILBOX |
| WORK_NOTES | Строка(max) | WORK_NOTES |
| WORK_PAGER | Строка(max) | WORK_PAGER |
| WORK_PHONE | Строка(max) | Телефон компании |
| WORK_POSITION | Строка(max) | Должность |
| WORK_PROFILE | Строка(max) | WORK_PROFILE |
| WORK_STATE | Строка(max) | WORK_STATE |
| WORK_STREET | Строка(max) | WORK_STREET |
| WORK_WWW | Строка(max) | Сайт компании |
| WORK_ZIP | Строка(max) | WORK_ZIP |
| XML_ID | Строка(max) | Внешний ключ, используется для операций обмена. Идентификатор объекта внешней информационной базы. Назначение поля может меняться конечным разработчиком. |
Таблица Объединенный справочник
| Имя | ТИП | Описание поля |
|---|---|---|
| CATEGORY_ID | Число | Идентификатор направления |
| COLOR | Строка(max) | Цвет |
| ENTITY_ID | Строка(max) | Идентификатор родительской сущности. Обязательное поле. |
| EXTRA | Строка(max) | Дополнительные поля |
| ID | Число | Идентификатор |
| NAME | Строка(max) | Имя контакта |
| NAME_INIT | Строка(max) | Название по умолчанию |
| SEMANTICS | Строка | SEMANTICS |
| SORT | Число | Сортировка |
| STATUS_ID | Строка(max) | Идентификатор статуса |
| SYSTEM | Строка | Системный |
3.8 - Выполнение внешних обработок в базах-источниках 1С:Предприятие через адаптер
Внимание: в Базе-источнике должен быть установлен Адаптер ETL не ниже 1.1.11.2.
Выполнение внешних обработок в базах-источниках 1С:Предприятие через адаптер представляет собой механизм получения данных с помощью обработок, встроенных в базы источники 1С. Предназначен для случаев, когда получение данных возможно только с помощью программного кода на языке 1С, либо требуется дополнительная программная обработка данных, полученных запросом/механизмами СКД.
Для выполнения внешних обработок в базах-источниках 1С:Предприятие через адаптер необходимо подготовить информационную базу - источник: разместить модуль получения данных. Обработки для получения данных можно добавлять через расширение или подключать как внешнюю обработку в информационную базу Подключение модуля на стороне ETL.
В ETL необходимо перейти в «Главное» / «Настройки» / «Модули получения данных»

В открывшемся окне списка создать новый элемент «Модуль получения данных из источника»

На форме элементе заполнить поля:
- Вид модуля = «Модуль на стороне базы-источника (1)
- База источник = Информационная система 1С:Предпиятие, в которой размещен модуль получения данных в п.1. (2)
- Вид объекта обработки - «Дополнительная обработка», если обработка добавлена как внешняя или «Обработка конфигурации», если обработка добавлена через расширение или находится внутри конфигурации (3)
- Обработка - имя модуля получения данных из п.1.Можно выбрать из списка (кнопка с тремя точками справа от поля)(4). После выбора обработки автоматически заполняется табличная часть с информацией по группам обработчиков. Принудительно обновить информацию в табличной части можно с помощью команды «Обновить данные по обработке». (5)
Настройка получения данных
Для получения данных необходимо создать в документ «Установка правил выгрузки». В документе указать:
- Вид правила = «Модули на стороне источника». (1)
- В группе «Настройки модуля» (2) на закладке «Данные модуля» в поле «Модуль получения данных» модуль добавленный в п.2. (3)
- В поле «Идентификатор группы обработчиков» выбрать группу обработчиков. (3)

Дальнейшая работа с документом (заполнение соответствия полей, настройка таблицы выгрузки) аналогична работе с другими видами правил.
Работа с составом выгрузки, пакетом обработки данных по установке правил аналогична работе с установкой правил по другим видам правил.
Создание обработки для получения данных
Для создания обработки получения данных, воспользуйтесь шаблоном, размещенном в текущей статье ниже При разработке обработки необходимо реализовать процедуры программного интерфейса:
- Инициализировать
- СписокПолейТаблицы
- Данные
- СписокПараметровПользователя
- ПараметрыПриПостановкеВОчередь
- Сведения о внешней обработке (если используется вариант подключения внешней обработки)
Выполнение произвольного кода на стороне информационной системы – источника
Внимание: Выполнение произвольного кода на стороне базы-источника может быть потенциально опасным, так как кодом, выполняемым на стороне приемника управляет другая система. Для промышленного использования рекомендуется избегать выполнения произвольного кода и создавать отдельную обработку на каждую процедуру получения данных.
Для решения задачи хранения кода на стороне ETL и передачи его для исполнения в базу источник создано расширение с обработкой-модулем(примером), в которой реализована концепция передачи произвольного кода через параметры.
Файлы для скачивания:
В обработке используется 2 параметра:
- КодПолученияСпискаПолей - параметр для хранения кода, с помощью которого Заполняется таблица соответствия полей в документе установки правил.
- КодПолученияДанных - параметр для хранения кода, с помощью которого будут получаться данные. Подготовлена тестовая обработка для ETL - «ЗаполнениеОбработчиков». С помощью этой обработки можно заполнить код для обработчиков выбранного Правила в более удобном интерфейсе. Последовательность действий для использования тестовой обработки:
- Обновить ETL до версии 1.6.9.8. Обновить в базе источнике Адаптер до версии 1.1.11.2.
- Добавить расширение «МодулиАдаптера» в базу источник.
- Пользователю в источнике, под которым ETL подключается к АдаптеруETL добавить роль хс_ИспользованиеМодулейПолученияДанных.
- В ETL в модулях подключить обработку-модуль (МА1_ПолучениеДанныхКодом) из расширения источника п.2
- Создать новый документ «Установка правил выгрузки», Вид правила = «Модули на стороне источника», выбрать модуль добавленный в п.3. Донастроить документ, сохранить и провести его. Т.к. обработчики для заполнения полей еще не установлены, следует в таблице соответствия полей добавить любую строку с любыми данными, далее она будет перезаполнена. Создавать никакую таблицу-приемник на текущем этапе не следует.
- Открыть обработку ЗаполнениеОбработчиков.epf, выбрать правило из п.4, заполнить обработчики(примеры обработчиков есть в папке Обработчики) и нажать «Записать параметры».
- Открыть заново документ установки правил выгрузки, нажать кнопку «Заполнить соответствие полей». При этом на стороне источника выполнится необходимый код обработчика и таблица соответствия заполнится(в примере будет 3 поля). Теперь можно донастроить правило сбора данных в части создания таблицы, установки нужных соответствий.
- Создать Состав выгрузки с правилом из п.4 и набором источников, в котором выбран источник с установленным расширением п.2.
- Запустить Состав выгрузки на исполнение и проверить, что таблица приемник заполнилась согласно коду-обработчику получения данных.
4 - Обработка данных
4.1 - Сценарии обработки данных
Полученные из источников учетных систем данные необходимо подготовить для использования в отчетах.
Подготовка данных включает процедуры-инструкции на языках SQL, 1C, Python для очистки, дополнения, агрегации, объединения и т.п. данных, расчета показателей, а также для сервисных операций выгрузки, загрузки, перемещения файлов, удаления архивных копий таблиц и т.д.
Для настройки процедур подготовки данных служит документ «Сценарий обработки данных», в котором настраиваются шаги сценария.
Список (журнал) сценариев вызывается либо с начальной страницы, либо из меню «Главная» / «Настройки» / «Сценарии»:

В списке сценариев можно создать новый сценарий (см. рисунок ниже, 1), отредактировать существующий и запустить сценарий:

Кнопка позволяет запустить на выполнение шаги сценария (см. рисунок выше, 2). Кнопка «Только примитивы» включает отбор служебных сценариев (примитивов) (см. рисунок выше, 3). Отключить этот отбор можно еще раз нажав на эту кнопку.
Настройка сценария обработки данных
Внешний вид документа представлен на рисунке ниже:

Варианты настройки и представления шагов сценария показаны на рисунке ниже.
Порядок настройки «Сценария обработки данных» следующий.
- На вкладке «Основное» необходимо заполнить поля:
- «Наименование сценария»;
- «База данных» (выбор из списка БД);
- «Тип» — заполняется автоматически как «Произвольная последовательность шагов». Другие типы используются для автоматически создаваемых сценариев обработки данных, таких как «Трансформация» или «Верификация данных»);
- «Комментарий» — текстовое поле при необходимости возможно заполнить дополнительной информацией по обработке данных.
- Для настройки шагов сценария существуют два варианта.
-
Вариант 1. На вкладке «Шаги сценария» создать и настроить шагисценария, написав для каждого шага скрипт на языке SQL\1С или использовать для настройки и авто-генерации скрипта для шага — готовые шаблоны.
-
Вариант 2. На вкладке «WorkFlow» настроить шаги обработки данных в визуальном интерфейсе WorkFlow (см. рисунок ниже, 2).
Вариант с интерфейсом WorkFlow для визуального проектирования ETL является более удобным и более функциональным, так как кроме основного процесса трансформации данных возможно дополнительно настроить сохранение информации по профилированию данных — сэмплы данных, статистику по значениям и качеству данных; а также сохранение и просмотр логов работы. Кроме того, шаги сценария, спроектированного в интерфейсе WorkFlow могут выполняться параллельно (см. рисунок ниже, 2). Таким образом, для новых сценариев обработки данных рекомендуется использовать WorkFlow, а вариант с таблицей шагов сценария использовать для изменения старых сценариев, для которых интерфейс WorkFlow недоступен и система сообщает о несовместимости.



- В таблице «Шаги сценария»,
- в интерфейсе WorkFlow,
- на закладке «Параметры сценария» возможно ввести параметры, которые будут использоваться в настройках / тексте скриптов шагов (см. рисунок ниже). Значения параметров можно и не заполнять, если предполагается запуск сценария только через «Пакеты обработки данных» (подробно см. в этом разделе).

- По кнопке «Записать и закрыть» на основной вкладке «Сценарий» сохраняется.
4.2 - Использование интерфейса WorkFlow
ModusETL развивается в концепции «low-code», что подразумевает возможность настраивать ETL-операции в визуальных интерфейсах и без необходимости написания кода. Появившийся в релизе ETL v. 1.5 (май 2021) интерфейс WorkFlow — является альтернативой настройке шагов сценария в виде таблицы, для которого возможно только последовательное выполнение шагов; в WorkFlow появилась возможность параллельного выполнения нескольких веток сценария, что обеспечивает большую производительность.
Интерфейс WorkFlow дает возможность проектировать сценарии обработки данных
- размещая шаги (обработчики) на холсте, связывая их друг с другом для передачи между шагами данных или потока управления;
- настраивая для шага правила обработки данных в визуальном мастере — сейчас возможно использовать десятки готовых мастеров (шаблонов) для выборки, группировки, соединения, объединения, дополнения, отбора данных и других ETL-операций.
- настраивая в нужных точках выполнения сценария сбор и сохранение статистики для профилирования и проверки качества данных (шаблон «Просмотр»).
При запуске сценария на исполнение в интерфейсе отображается ход выполнения процесса, сохраняются логи и статистика по данным.
Описание интерфейса WorkFlow
Для открытия интерфейса в разделе сценария обработки данных выбрать кнопку «WorkFlow» как на рисунке ниже:

Для настройки процесса обработки данных необходимо разместить шаги на холсте, выбирая шаблоны обработчика из списка шаблонов (см. рисунок ниже, 1 и 2) и связывая шаги друг с другом.
Список с кратким описанием назначения и основных функций шаблонов / мастеров обработки данных см. этот раздел.
Шаги связываются стрелкой, которая означает передачу управления иили передачу данных (см. рисунок ниже, 3).
Для шага возможно изменить «Наименование» в текстовом поле над шагом (см. рисунок ниже, 4).
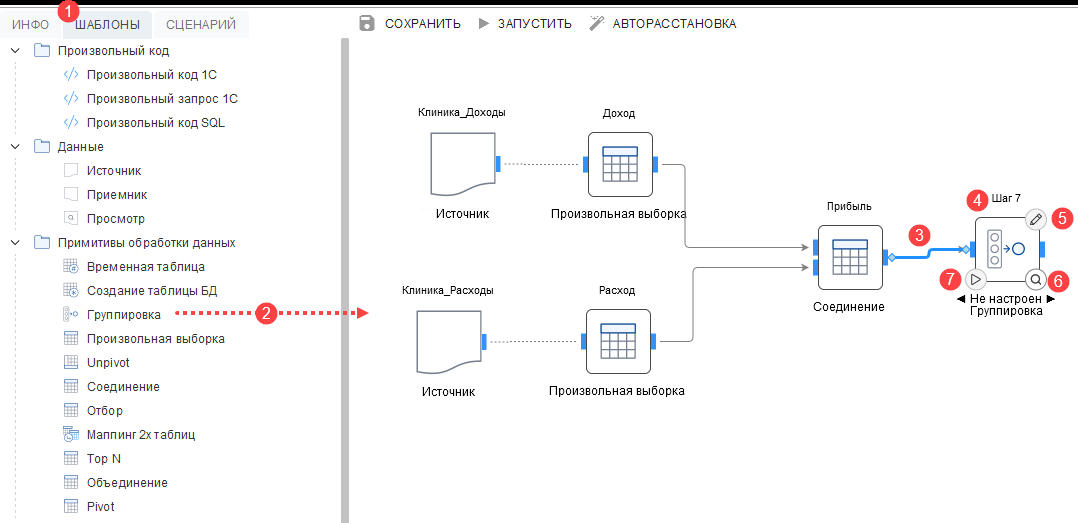
Для настройки параметров шага — необходимо запустить мастер, воспользовавшись контроллом «Редактировать шаг» (см. рисунок выше, 5). Настройка с использованием шаблонов мастеров описана в этом разделе:

Как правило, в мастере настройки имеются закладки «Выбора источника», «Настройки полей запроса» и просмотра «Результата». На закладке «Результат» отображается текст запроса и результат запроса:

Элемент управления «Просмотр» (см. второй рисунок, 6) предназначен для просмотра образца (сэмпла) данных (см. рисунок выше). Если при открытии отобразится сообщение «Нет данных», то для выполнения сценария до текущего шага и получения сэмпла данных необходимо нажать «Выполнить до текущего цикла». Также возможно изменить количество отображаемых строк, установив параметр «Размер выборки».

Элемент управления для шага «Выполнить до текущего шага» (см. второй рисунок, 7) предназначен для запуска выполнения сценария до текущего шага — при выполнении отображается прогресс и лог выполнения:

В сценарии возможно настраивать в нужных точках сбор и сохранение статистики для профилирования и качества данных, используя специальный шаблон «Просмотр».
После формирования диаграммы WorkFlow с шагами обработки данных и связями шагов, настройки точек сбора статистики по данным, источниками и приемниками данных — необходимо сохранить сценарий обработки данных и запустить на выполнение, воспользовавшись кнопками в верхней части WorkFlow «Сохранить», «Запустить», «Авторасстановка».
После запуска в интерфейсе (см. рисунок ниже, «S»), будет отображаться ход выполнения на прогресс-баре (см. рисунок ниже, «P»), выполненные шаги выделяются зелеными рамками и в таблице «Лог выполнения» выводится инфо о времени и длительности выполнения шагов (см. рисунок ниже, «L»):

После завершения выполнения сценария возможно анализировать «Лог выполнения», для возможной оптимизации наиболее длительных шагов. В случае ошибки — описание ошибки будет выведено в колонке «Ошибка лога выполнения».
Список шаблонов шагов сценария
Для реализации концепции «low-code» — возможности настраивать ETL-операции пользователем без специальной подготовки, в удобных визуальных интерфейсах и без написания кода в Modus ETL доступны мастера визуальной настройки обработки данных — шаблоны шагов сценария. Ниже — список используемых шаблонов. Этот список будет пополнятся и расширятся в новых релизах продукта:
| Шаблон шага сценария | Описание функционала | Есть в Work Flow? |
|---|---|---|
| Произвольный код | ||
| Произвольный код SQL | Для ввода кода на языке SQL | Да |
| Произвольный код 1С | Для ввода кода на языке 1С | Да |
| Произвольный запрос 1С | Для ввода на языке 1С-запросов | |
| Данные | ||
| Источник | Присоединяется ко входу шага-обработчика данных. Предназначен для выбора таблицы-источника. Нажав на элемент управления возможно просмотреть сэмпл данных | Да |
| Приемник | Присоединяется к выходу обработчика данных. Предназначен для формирования таблицы с набором полей из входящего потока и сохранения данных в таблицу. Элемент управления — для получения и просмотра сэмпла данных из таблицы. Если установить признак, то приемник может быть источником для последующих шагов сценария |
Да |
| Просмотр | Используется для сохранения и просмотра статистики по данным | Да |
| Очистка таблицы | Производит очистку таблицы из базы данных, которую надо указать в поле «Приемник данных» | Да |
| Перенос данных | Предназначен для переноса данных между двумя различными базами внутри одного сценария | Да |
| Примитивы обработки данных | Да | |
| Произвольная выборка данных | Для настройки выборки данных из одной или нескольких таблиц с функциями выбора полей, соединения таблиц, отбора и сортировки данных. Возможно применять функции преобразования к полям или добавлять новые поля, используя интерфейс «Конструктор выражений». На основании полей с типом «дата» и «дата и время» возможно добавлять поля с частями даты (год, квартал, месяц, номер недели, день недели и т.д.), воспользоавшись интерфейсом «Части даты» |
Да |
| Группировка | Группирует данные, аналогично SQL-функции GROUP BY. Настраиваются: поля группировки и поля агрегатов с выбором функций: SUM, MIN, MAX, AVG, COUNT. |
Да |
| Соединение (дополнение данных) |
Дополняет данные основной таблицы/потока полями из одной или нескольких таблиц. Соединяет таблицы, аналогично SQL-функции JOIN. Настраиваются условия соединения таблиц и поля из таблиц с возможностью применения функций |
Да |
| Объединение | Объединяет данные таблиц аналогично SQL-функции UNION. Настраиваются соответствия полей основной и добавляемых таблиц |
Да |
| Отбор | Для отбора/фильтрации данных по условиям. Настраиваются: «Поле» / «Условие» / «Значения». Набор условий зависит от типа поля (строка, число, дата) и соответствует SQL-операторам: =, ≠, >, <, ≥, ≤, LIKE, IN(список), not IN(список) NULL, IS NOT NULL |
Да |
| Маппинг полей двух таблиц | Копирует данные из одной таблицы в другую по настроенным правилам соответсвия (маппинга) полей | Да |
| Маппинг полей двух таблиц с предварительным удалением | Работает аналогично шаблону «Маппинг 2х таблиц», с одним отличием. На вкладке «Связь полей» задаются поля (ключ) для поиска. Если какие-то записи совпадут по ключу поиска, то они в таблице-приёмнике будут заменены соответствующими записями из таблицы-источника | Да |
| Unpivot | Транспонирует выбранные столбцы таблицы При этом заголовки выбранных столбцов переносятся в значения строк, а их значения — в один столбец. |
Да |
| Pivot | Для формирования сводной таблицы настраиваются: - поля группировки — значения выводятся в строках; - поля для транспонирования строк в столбцы; - поля значений с функцией агрегации |
Да |
| Создание таблицы БД | Используется для создания таблиц в базе данных хранилища | Да |
| Топ N | Для выбора строк по условиям. Настраивается: - размер выборки — N строк, - поля и направление сортировки. SQL эквивалент: top N / limit N с условием Order by |
Да |
| Разделение строки | разделяет строки на массив подстрок, используя указанный разделитель | Да |
| НСИ — дополнение данных | ||
| Справочник НСИ | Эталонный справочник модуля НСИ для дополнения или обновления первичных данных | Да |
| Маппинг НСИ | Таблица соответствия между сущностями: справочниками, категориями / группами | Да |
| НСИ. Дополнение из эталонного справочника | Дополнение таблицы значениями из эталонного справочника НСИ. Настраиваются: связь таблиц — поля и условия; поле(я) для дополнения таблицы | Да |
| НСИ. Обновление из эталонного справочника | Замена значений в таблице значениями из эталонного справочника НСИ. Настраиваются: - связь таблиц — поля и условия; - поле(я) для обновления таблицы |
Да |
| НСИ. Дополнение из маппинга | Дополнение таблицы значениями из маппинга НСИ. Настраиваются связь таблиц — поля и условия связывания, а также поле(я) для дополнения исходной таблицы | Да |
| Python | ||
| Кластеризация | Кластеризация используется для группировки объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри группы (кластера) должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры. Возможно выбирать алгоритмы «KMean», «DbScan». |
Да |
| Линейная регрессия | Регрессия используется для решения задач «Data Mining», таких, как прогнозирование и численное предсказание. Требуется предварительное обучение на обучающей выборке. Возможно выбрать из пяти линейных («Linear regression», «Ridge», «Lasso», «Elastic Net», «Lars») и двух древовидных («Decision tree», «Random forest regressor») моделей | Да |
| Сервисные операции | ||
| Настройка замены пустых значений | Заменяет значения по образцу | Да |
| Выгрузка таблицы в файл | Настраиваются параметры для выгрузки данных в файл | Да |
| Настройка индексов таблицы | Создает индексы в таблице для ускорения поиска | Да |
| Мастер настройки расчета фасетов таблицы | Расчет статистических данных таблицы (фасетов), котрые используется для быстрого знакомства с данными и профилирования данных | Да |
| Очистка хранилища от бэкапов | Удаления архивных копий таблиц, которые копируются и сохраняются при обновлении данных в целевой таблице «Составом выгрузки» в режиме «Скопировать и добавить». Такие архивные таблицы имеют общий признак: суффикс «_ГГГГММДД_Время» в наименовании | Да |
| Копирование бинарного файла в «BASE64» | Файлы, подходящие под заданную маску, кодируются по алгоритму «BASE64» и сохраняются в текстовый выходной «CSV»-файл | Да |
| Настройка удаления пробелов/спецсимволов из полей таблицы | Очистка строковых полей от «плохих» символов | Да |
| Запуск принудительного обновления куба | Настраиваются параметры интеграция с сервером «Полиматики» для обновления кубов по расписанию | Да |
| Сложный сценарий | ||
| Вставка результата запроса в таблицу | Записывает в выходную таблицу | Да |
| Смена имен таблиц | Изменяет имя таблицы по образцу | Да |
| Создание временной таблицы | Создает временную таблицу | Да |
| Верификация данных | ||
| Начало процесса верификации | Осуществляется запись в специальный журнал процессов о начале процесса верификации | Нет |
| Заменить значение | Настраивается замена значения при обнаружении ошибки | Нет |
| Записать в лог ошибок | Настраивается запись в лог ошибок описания ошибки при ее обнаружении | Нет |
| Завершение процесса верификации | Осуществляется запись в специальный журнал процессов об окончании процесса верификации, количестве обработанных строк и количестве выявленных ошибок | Нет |
| Мэппинг данных с заменой | Осуществляет проверку и замену значений поля таблицы в соответствии с предварительно настроенным справочником эталонных значений | Нет |
| Мэппинг предварительный анализ | Осуществляет проверку в соответствии с предварительно настроенным справочником эталонных значений | Нет |
| Проверка символьной строки | Осуществляется проверка значений поля на соответствие предопределенным правилам, например, проверка корректности СНИЛС, ИНН и т.п. | Нет |
| Проверка на NULL | Осуществляется поиск незаполненных (NULL) значений в поле таблицы для символьных, числовых или календарных типов данных. | Нет |
| Мэппинг данных с дополнением | Осуществляет проверку и дополнение таблицы новым полем в соответствии с предварительно настроенным справочником эталонных значений | Нет |
Перенос данных
Типы шаблонов и рекомендации по использованию шаблонов
Шаблоны из группы «Произвольный код» используются для ввода кода на языке 1С / SQL.
Шаблоны из группы «Данные» предназначены не для обработки данных, а для настройки источников, приемников и правил сбора статистики по данным.
Шаблоны из группы «Примитивы обработки данных» используются для настройки выборок из таблиц, обработки-трансформации данных определенным способом.
Шаблоны из группы «НСИ — дополнение данных» используются для операций стандартизации и категоризации данных с использованием объектов НСИ — эталонных справочников и маппингов.
Шаблоны из группы «Python» используются для решения задач DataMining сегментации объектов, прогнозирования, предсказания и т.д., с использованием моделей продвинутой аналитики и библиотек Python.
Шаблоны из группы «Сервисные операции» используются для выгрузки таблиц в файлы, настройки индексов, замены значений по определенным правилам, очистки хранилища от архивных копий таблиц, кодирования файла в «BASE64» и других сервисных операций.
Шаблоны из группы «Верификация данных» используются для настройки логирования процесса верификации (проверки на установленные условия), настройки правил верификации и обработки выявленных ошибок.
Шаблоны из группы «Сложные сценарий» используются для оптимизации работы с таблицами.
4.3 - Шаблоны примитивов обработки данных
Данная группа автоматизирует базовые операции по трансформации, агрегации, очистке данных и дополнительным расчётам.
Произвольная выборка
Шаблон «Произвольная выборка» — эффективный инструмент для выборки, очистки, трансформации данных и вспомогательных расчётов. Шаг настраивается в окне «Мастер настройки выборки данных». По умолчанию активна вкладка «Настройка полей запроса».

Как в большинстве шаблонов группы, вкладка имеет два секции: левую (источники данных) и правую (поля новой таблицы, которую создаёт шаг сценария).
Изначально задается один обязательный источник (его можно увидеть на первой вкладке «Выбор источника»). Если была задана связь с предыдущим шагом сценария, то это как раз таблица предыдущего шага (к примеру, созданного на основе шаблона «Источник» или других примитивов обработки данных). Однако, для новой таблицы можно выбирать и трансформировать поля из множества разных таблиц. Достаточно нажать кнопку со знаком «+» и указать дополнительную таблицу-источник в диалоговом окне «Выбор таблиц для сценариев». Новая таблица появится в левой секции. Контекстное меню (вызывается правой кнопкой мыши) позволяет удалять таблицы-источники.
Нужные для выборки поля перемещаются из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». На предыдущем рисунке использованы поля «Товар» (из таблицы «test_xlsx_ad») и «Сумма» (из таблицы «demo_tbl»), а на основе поля «Дата» (из таблицы «demo_tbl») сгенерировано новое поле «Дата_Месяц». Точка напротив использованных полей в исходной таблице меняет цвет на синий.
В правой секции вкладки «Настройка полей запроса» можно:
- добавлять, удалять поля новой таблицы. Предусмотрены кнопки «Добавить» и «Удалить всё»;
- менять порядок полей сверху вниз (кнопками со стрелками над секцией). Это влияет на порядок полей слева направо (соответственно) формируемой таблицы;
- задавать псевдоним нового поля ручным вводом в колонке «Псевдоним» (по умолчанию имена полей совпадают с исходными, либо генерируются автоматически при создании части даты);
- трансформировать выражения, производить дополнительные расчёты с помощью вставок кода на SQL. В колонке «Поле/Выражение» двойной щелчок мыши выводит кнопку с символом троеточия «…». Нажатие на кнопку открывает подокно «Произвольное выражение» (рисунок ниже), где вручную вводится код;

- менять тип полей в новой таблице с помощью колонки «Тип». Интерфейс аналогичный колонке «Поле/Выражение» — двойной щелчок мыши и кнопка «…»;
- задавать сортировку по полю. Двойной щелчок мыши в колонке «Сорт.» задает сортировку по убыванию, возрастанию (поле «Товар»), либо удаляет сортировку. Сортировка работает, если в поле «Ограничить размер выборки» введено число строк. При включенной сортировке появляется символ треугольника.
В нижней части вкладки есть селектор «Выбирать различные данные». Он позволяет извлекать только уникальный список значений (без повторов).
Можно использовать поле с датой и временем в трансформированном виде (извлечь месяц, год и т.д.). Перед этим поле следует добавить в правую секцию, выделить его и нажать кнопку «Части даты». Появится окно с различными вариантами для выбора. После добавления трансформированного результата исходное поле с датой можно удалить, и оставить только преобразованный вариант даты.

В примере из поле «Дата» извлечено название месяца на русском языке. После закрытия окна в столбце «Поле/Выражение» генерируется код на SQL:
to_char(Дата, 'TMMonth')
Если в шаге данные собираются из нескольких таблиц, необходимо связать исходные таблицы между собой (вкладка «Связи таблиц»). Двойной щелчок мыши по названию нижестоящей таблицы «test_xlsx_ad» вызывает диалоговое окно «Соединения». В окне выбираются тип соединения («Левое») и связанные поля («Товар»).

При необходимости, есть функция фильтрации данных в исходных таблицах по какому-либо условию (вкладка «Настройка отбора данных»). При этом, можно задать сразу множество отборов.
Каждый отбор создаётся кнопкой «Добавить новый элемент» (правее есть кнопки группировки условий и удаления). Потом надо указать поле для отбора, вид сравнения и в колонке «Значение» ввести константу.



В итоге, в нижней части окна появится SQL-код условий отбора:
"ad_test_demo_tbl_t"."Товар" = 'Товар 1'
Можно использовать группу условий, которые должны одновременно выполняться (логическое «И»), либо не выполняться (логическое «НЕ»), либо достаточно выполнения одного любого условия из группы (логическое «ИЛИ»). Для этого надо выделить несколько условий и нажать кнопку «Сгруппировать условия«, а затем выбрать в заголовке группы нужный логический вариант. Код отбора SQL можно ввести вручную, если активировать режим «Текст отбора задается произвольным кодом».
На вкладке «Результат» можно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует шагу.

Группировка
Шаблон «Группировка» позволяет агрегировать данные из таблицы-источника или таблицы предыдущего шага. Соответствует SQL-операции GROUP BY.
На следующем рисунке рассчитана сумма по полю «Сумма» для каждого значения поля «Товар».

Группируемые поля («Товар») перемещаются из левой секции «Поля источника» в нижнюю правую («Группировки») с помощью мыши (методом drag-and-drop). Точки напротив имён использованных полей поменяют цвет на синий.
Кнопки со стрелками над секцией «Группировки» позволяют менять порядок группируемых полей сверху вниз. Это влияет на их порядок в новой таблице слева направо (соответственно).
Поля для агрегаций (например, суммы, среднего, максимума, минимума, количества строк) также перемещаются с помощью мыши из левой секции «Поля источника» в верхнюю правую («Показатели»). Здесь изменение порядка строк сверху вниз производится с помощью контекстного меню (вызывается правой кнопкой мыши: там есть варианты для перемещения вверх и вниз).
Двойной щелчок мыши по полю в «Показатели» и нажатие кнопки «…» открывает диалоговое окно «Произвольное выражение». В окне можно вручную прописать код SQL для агрегации («Выражение»).
В каждой строке секций «Группировки» и «Показатели» есть столбец «Псевдоним». В столбце можно вручную ввести новое название колонки.
По умолчанию, агрегируемому выражению в секции «Показатели» присваивается тот же числовой тип, что и в исходном поле. На вкладке есть селектор «Показывать типы полей». Желательно его активировать. Тогда в агрегации можно менять тип чисел. Может понадобиться тип с большей разрядностью, если суммы в исходной таблице большие и итоговый расчёт выйдет за диапазон данных исходного поля. Иначе результатом группировки будет ошибка.

Результат шага отражается на одноименной вкладке: можно увидеть полученную таблицу и код SQL для её генерации.

Соединение
Шаблон «Соединение» нужен для объединения данных из нескольких таблиц.
Для шага с таким шаблоном нужны связи из предыдущих шагов (например, таблиц-источников или вычисляемых таблиц с помощью примитивов). Должно быть минимум две таблицы для объединения.
Рассмотрим пример соединения слева (аналог функции «ВПР» в MS Excel / операции LEFT JOIN в SQL). К таблице продаж по адресу надо добавить почтовый индекс.

В нижней секции «Условия связи таблиц» выбирается тип соединения («Левое»), с помощью кнопки «Добавить» добавляется строка условия равенства двух адресов. Две колонки называются по имени исходных таблиц («Продажи (основной)» и «Справочник»), а в выпадающих списках надо лишь выбрать два раза поле «Адрес». Между двумя полями есть столбец для вида условия, также с помощью выпадающего списка (в примере это равенство «=»).
Если ключ для связи составной (основан на двух и более полях), добавляются дополнительные строки условий (есть кнопка «Добавить»).
Шаг позволяет объединять за один раз более двух таблиц. В этом случае, в выпадающем списке «Присоединяемые таблицы» надо выбрать третью (четвертую и т.д.) таблицу и аналогичным образом задать связи между полями в секции «Условия связи таблиц».
Далее, следует выбрать поля, которые попадут в итоговую таблицу шага. На вкладке «Настройка полей запроса» в левой секции отображаются исходные таблицы и их поля. С помощью мыши методом drag-and-drop (или кнопками «>» и «<») их можно перетащить в правую секцию, где собираются поля и выражения итоговой таблицы. Точки напротив имён использованных полей поменяют цвет на синий.

Кнопки со стрелками над правой секцией позволяют менять порядок группируемых полей сверху вниз. Это влияет на их порядок в новой таблице слева направо (соответственно).
Кнопка «Добавить» добавляет новую строку, в которой можно создать выражение. Двойной щелчок мыши по столбцу «Поле/Выражение» и нажатие кнопки «…» открывает диалоговое окно «Произвольное выражение». В окне можно вручную прописать код SQL для расчёта нового показателя («Выражение»). Из рисунка выше можно понять, что адрес продаж переводится в верхний регистр.
В каждой строке правой секции есть столбец «Псевдоним». В столбце можно вручную ввести новое название колонки.
Если используется поле с датой и временем, его можно трансформировать (извлечь месяц, год и т.д.). Перед этим поле следует добавить в правую секцию, выделить его и нажать кнопку «Части даты». Появится окно с различными вариантами для выбора. После добавления трансформированного результата исходное поле с датой можно удалить.

Таблица, генерируемая шаблоном, отражается на вкладке «Результат». Здесь можно увидеть также код SQL для генерации данных.

Отбор
Шаблон «Отбор» используется для фильтрации таблицы по одному или группе полей. В логике SQL он соответствует оператору WHERE. Надо выбрать поля из таблицы предыдущего шага и указать условия фильтрации (одно или более).
При этом, выводятся все колонки исходной таблицы — их нельзя извлекать выборочно или производить над ними вычисления.
Важно обратить внимание, что на пиктограмме шага два выхода на следующие шаги. Если надо передать данные, которые соответствуют условию отбора, то связь делается через верхний выход. В противном случае, шаг отбора связывается со следующим через нижний выход.

На рисунке выше исходная таблица предыдущего шага фильтруется одновременно по трём полям:
- наименование товара должно быть «Товар 1»;
- дата продаж до 01.01.2024;
- сумма продаж в каждой строке больше 50 000 руб.
Вкладка «Настройка отбора данных» имеет два секции: левую (источник данных) и правую (условия отбора для новой таблицы, которую создаёт шаг сценария).
Нужные для фильтрации поля перемещаются из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий.
В правой секции можно:
- добавлять, удалять поля с условиями фильтрации. Предусмотрены кнопки «Добавить новый элемент» и «Удалить», а также «Сгруппировать условия»;
- менять порядок условий сверху вниз (кнопками со стрелками над секцией);
- задавать тип сравнения двойным щелчком мыши и выбором из выпадающего списка. Для дат кроме произвольной даты есть множество вариантов («Начало прошлого года», «Начало этого дня» и т.д. для дней, недель, месяцев и лет). Далее, в колонке «Значение» следует ввести константу, а перед именем поле активировать галочку.
В итоге, в нижней части окна появится SQL-код условий отбора.
Код отбора SQL можно ввести вручную, если активировать режим «Текст отбора задается произвольным кодом».
На вкладке «Результат» можно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует шагу.

Top N
Шаблон «Top N» извлекает из таблицы исходных данных первые N записей. Соответствует оператору SQL LIMIT. При этом, в шаблоне есть возможность фильтрации и сортировки.
Такой шаблон полезен, когда вместе с сортировкой по какому-то полю можно выбрать N «лучших» или «худших» позиций в контексте отсортированного поля.
Рассмотрим пример, когда на предыдущем шаге есть таблица следующего вида.

Выберем три самых продаваемых товара, но с суммой продаж более 1 300 000 руб. Отсортируем таблицу по полю «Сумма» и три записи с фильтром по полю «Сумма» от 1 300 000.

На первом шаге, следует указать поле для сортировки. Вкладка «Настройка сортировки» имеет два секции: левую (источник данных) и правую (условия отбора для новой таблицы, которую создаёт шаг сценария).
Нужные для фильтрации поля перемещаются из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий (в данном случае поле «Сумма»).
В правой секции можно:
- менять порядок условий сверху вниз (кнопками со стрелками над секцией). Это важно, потому что можно одновременно сортировать более одного поля. Порядок полей сверху вниз влияет на очередность сортировки: сортировка полей выше приоритетнее, чем тех, что ниже;
- добавлять, удалять поля с условиями фильтрации. Для этого предусмотрено контекстное меню, вызываемое правой кнопкой мыши;
- задавать тип сортировки двойным щелчком мыши по колонке «Сортировка». Сортировать можно по убыванию или возрастанию (в данном случае логично по убыванию). В колонке »Сортировка» появится знак треугольника соответствующей формы.
В поле «Размер выборки» введём цифру «3».
На следующем шаге зададим фильтрацию (вкладка «Настройка отбора данных«).

Здесь также есть две секции: левая (список полей исходной таблицы с предыдущего шага) и правая (условия отбора для полей).
Нужные для фильтрации поля перемещаются из левой секции в правую с помощью мыши, или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий (в данном случае поле «Сумма»).
В правой секции можно:
- добавлять, удалять поля с условиями фильтрации. Для этого предусмотрено контекстное меню, вызываемое правой кнопкой мыши, и кнопка «Добавить новый элемент» над секцией;
- выбрать тип сравнения из выпадающего списка в колонке «Вид сравнения»;
- задать вручную пограничное значение в поле «Значение».
Для дат есть множество вариантов («Произвольная дата» (с выбором из календаря), «Начало прошлого года», «Начало этого дня» и т.д. для дней, недель, месяцев и лет).
На вкладке «Результат» можно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.

Объединение
Шаблон «Объединение» позволяет объединить разные таблицы (из предыдущих шагов) построчно. Соответствует логике SQL-оператора UNION.
На первом шаге (вкладка «Настройки объединения») надо указать, как поля разных таблиц соответствуют друг другу. На вкладке появляется таблица-конструктор. Каждая её колонка — это поля таблиц, участвующих в объединении (их может быть более двух). Если у полей разных таблиц одинаковые названия и идентичные типы данных, то процесс ускорит кнопка «Заполнить»: этот инструмент сам произведет расстановку. Если нужна корректировка, в каждой ячейке есть раскрывающийся список и можно выбрать соответствующее поле вручную.

При включенном селекторе «Только уникальные» из итоговой (объединённой) таблицы удаляются повторяющиеся строки. В коде SQL из оператора UNION исключается параметр ALL.
На вкладке «Результат» можно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.

Unpivot
Шаблон «Unpivot» выполняет действия, обратные шаблону «Pivot», преобразуя столбцы данных в строки. Соответствует одноимённому оператору SQL.
Например, есть данные о продаже товаров помесячно следующего вида.

На следующем рисунке — пример настройки шаблона.

В левой секции окна настройки шаблона выделены все поля, поскольку они все задействованы.
На вкладке «Настройка полей запроса» в имени «Категория» вводим «Месяц», а в «Имя поля значения» вводим «Сумма продаж в руб.». В нижнюю правую секцию «Значение (категория)» следует переместить (мышью методом «drag-and-drop» или кнопками «<» и «>») поля с месяцами, и напротив каждого месяца можно вручную ввести полное наименование. С помощью контекстного меню можно удалить лишние поля из списка.
Если флаг «Выводить пустые» проставлен, то строки со значениями NULL будут выведены, в противном случае, строки не выводятся.
В «Тип поля значения» можно скорректировать тип (например, увеличить разрядность чисел, чтобы не было переполнения).
На вкладке «Результат» можно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.

Pivot
Шаблон «Pivot» производит действия, обратные шаблону «Unpivot»: он преобразует строки данных в столбцы. Соответствует одноимённому оператору SQL. Например, есть данные о продаже товаров помесячно следующего вида. Требуется данные с названиями месяцев перевести в столбцы.

В окне настройки шаблона есть четыре секции:
- «Поля источника» — перечень полей исходной таблицы;
- «Строки (группировки)» — для полей, которые останутся в столбцах (в данном случае поле «Товар»);
- «Столбцы» — для поля, которое из столбца трансформируется в строки («Месяц»);
- «Значения» — числовое поле со значениями («Сумма продаж в руб.»).

Поля из секции «Поля источника» добавляются в другие три секции с помощью мыши методом drag-and-drop. Слева от названия полей, использованных в секции «Поля источника», появляется цветная точка.
В процессе трансформации для числового поля можно выбрать агрегацию (сумма, количество, число уникальных значений, минимум, максимум и среднее). Такая возможность может быть актуальна, если для комбинаций полей в «Столбцы» и «Строки (группировки») есть много записей. Например, если бы в исходной таблице записи повторялись для одних и тех же товаров в одном месяце, но по дням месяца. В некоторых случаях, в принципе, для исследования данных интересны аналитики типа среднего, максимум, минимума и т.д.
В рассматриваемом примере выбирается вариант суммирования, и укрупнения информации не произойдёт.
Результат работы шаблона (вкладка «Результат») — трансформированная таблица и SQL-код для шага.

Маппинг 2х таблиц
Шаблон «Маппинг 2х таблиц» позволяет копировать данные из одной таблицы в другую, используя настроенные правила соответствия (маппинга) полей. С помощью шаблона надо показать, какие поля первой таблицы соответствуют каким полям другой таблицы в рамках SQL-инструкции INSERT INTO. Также можно произвести фильтрацию исходных данных и некоторые преобразования.
Например, необходимо скопировать данные из одной таблицы (таблица-источник) в другую таблицу (таблица-приёмник) (без округа ЮФО). Данные поля «Регион» таблицы-источника соответствует полю «Область» таблицы-приёмника.


На вкладке «Источник и приёмник» надо выбрать имена двух таблиц в базе данных.

Округ ЮФО отфильтрован на вкладке «Настройки отбора данных».

Каждый отбор создаётся кнопкой «Добавить новый элемент» (правее есть кнопки группировки условий и удаления). Потом надо указать поле для отбора, вид сравнения (из выпадающего списка) и в колонке «Значение» ввести константу.
Можно задать сразу множество отборов, а также группироваить их (когда условия одновременно выполняются — логическое «И», не выполняются — логическое «НЕ», либо достаточно выполнения одного любого условия из группы — логическое «ИЛИ»). Для этого надо выделить несколько условий и нажать кнопку «Сгруппировать условия», а затем выбрать в заголовке группы нужный логический вариант.
Далее, на одноимённой вкладке устанавливается связь полей (рисунок ниже). Из левой секции «Источник» (где есть перечень полей таблицы-источника) с помощью мыши методом drag-and-drop нужные поля перемещаются в правую секцию «Приёмник». Если поля называются одинаково, можно воспользоваться кнопкой «Автосопоставление». Предусмотрена кнопка и быстрой очистки сопоставлений. Над обоими секциями есть кнопки «Показать таблицу» для предварительного просмотра данных.

Чтобы суммы продаж были в одном измерении, поле таблицы-источника «Сумма_продаж_млн_руб.» перед копированием в поле «Продажи_в_руб.» таблицы-приёмника надо умножить на 1000000. После двойного щелчка мышью по имени перемещенного поля в правой секции («Сумма_продаж_млн_руб.») появится кнопка «…», которая вызовет диалоговое окно «Произвольное выражение». В этом окне можно ввести необходимую формулу для вычислений.
После выполнения шага маппинга можно получить необходимый результат (рисунок ниже).

Создание таблицы БД
Шаблон «Создание таблицы БД» позволяет создать пустую таблицу базы данных с определенным набором полей нужного типа. Для шаблона не нужны предыдущие шаги, чтобы получить входные данные. Такой шаг соответствует SQL-оператору CREATE TABLE.

На вкладке «Основная» задается «Имя таблицы», схема, и с помощью кнопки «Добавить» создать каждое поле. В колонке «Имя поля» вручную вводится имя поля. Двойной щелчок мыши в колонке «Тип поля» активизирует кнопку «…», которая позволяет задать тип (из категории «Типы данных» или «Пользовательские типы»).
Клавиши со стрелками вверх и вниз меняют порядок полей в новой таблице слева-направо соответственно.
На вкладке «Основная» также предусмотрен селектор «Создать если отсутствует» и «Удалить и создать». Выбранный режим выделяется синим цветом текста и влияет на алгоритм шаблона: в первом случае таблица просто создается с нуля, если её нет, во втором случае она всегда удаляется и заново создается.
Селектор «Скрыть служебные параметры» скрывает настройки: подтип данных для поля, и допускаются ли пустые значения (NULL) в конкретном поле. Результат работы шаблона (вкладка «Результат») — код на PostgreSQL.

Кнопка «Готово» в верхнем левом углу шаблона завершает настройку шага.
Разделение строки
Шаблон «Разделение строки» разделяет строки на массив подстрок, используя указанный разделитель. В таблице на выходе становится больше строк, так как строки исходной разделяются на части, причем в том месте, где есть разделитель.
Шаблон соответствует оператору UNNEST с параметром STRING_TO_ARRAY, которые специфичны для PostgreSQL.
Такой шаг может быть полезен для анализа данных, значения которых разделены определенным символом. Например, встречаются выгрузки в формате «CSV» в которых наборы данных в тексте разделены запятой.
Рассмотрим пример, когда на метеостанциях ежедневно, 6 раз в сутки, снимаются показания температуры.

Кнопка «Показать входные данные» выгружает в нижней секции пример исходной таблицы. Очевидно, что из списка полей «Разделяемое поле» надо выбрать «Температура», и укажем «Разделитель» («,»).
Ниже — результат работы шага (вкладка «Результат»). Из каждой строки исходной таблицы получилось 6 строк. Значения полей «Дата» и «Метеостанция» дублируются для каждой новой строки, а поле «Температура» разделено на 6 значений.

Маппинг 2х таблиц с предварительным удалением
Шаблон «Маппинг 2х таблиц с предварительным удалением» работает аналогично шаблону Маппинг 2х таблиц, с одним отличием. На вкладке «Связь полей» задаются поля (ключ) для поиска (в колонке «Поиск»). В таблицу-приёмник попадут все записи из таблицы-источника. Но если какие-то записи совпадут по ключу поиска, то они в таблице-приёмнике будут заменены соответствующими записями из таблицы-источника.
4.4 - Шаблоны выполнения произвольного кода
С помощью шаблонов в данной группе можно писать код на языке 1С или SQL для загрузки данных из базы 1С, либо создания, выборки данных, очистки и т.д. произвольных таблиц СУБД.
Произвольный код 1С
Шаблон «Произвольный код 1С» позволяет написать произвольный код на языке 1С для извлечения данных из базы 1С.

Произвольный запрос 1С
Данный шаблон позволяет получить данные из базы ETL с помощью языка запросов 1С. Он является устаревшим и не рекомендуется к использованию.
Произвольный код SQL
Шаблон «Произвольный код SQL» позволяет написать SQL-код для выгрузки данных из базы SQL. Шаблон может быть без предыдущего шага, поскольку исходные данные будут загружаться из таблиц, указанных в произвольном коде.

Предусмотрен выбор типа запроса в выпадающем списке «Тип»: выборка данных SELECT («SEL»), выполнение набора команд («EXEC») или подзапрос («Вложенный запрос»):
- если выбран тип запроса «EXEC», то в произвольный код можно внести набор инструкций, разделенных точкой с запятой — все они по очереди будут выполнены. Здесь также могут быть инструкции, которые не приводят к генерации таблиц данных. Например, это операции создания макета таблицы (
CREATE TABLE), очистки (TRUNCATE) и т.д.; - тип запроса «SEL» подходит, если код генерирует на выходе таблицу с данными, и тогда их можно посмотреть в результате работы шага и передать в следующий шаг. Например, в шаг «Перенос данных»; в этом случае внизу вкладки «Основное» есть вкладка «Дополнительно» / «Структура данных», где можно перенастроить поля таблицы;
- тип запроса «Вложенный запрос» полезен, если надо сгенерировать таблицу данных, и передать эти данные как вложенный запрос на следующий шаг, сделанный также в шаблоне «Произвольный код SQL». В настройке следующего шаге кнопка «Вложенные запросы» откроет диалоговое окно с наименованием шага предыдущего вложенного запроса. Двойной щелчок по наименованию внесёт имя данных вложенного запроса в текущий запрос.
Кнопка «Вложенный запрос» работает аналогичным образом, когда перед шагом «Произвольный код SQL» есть другой шаг типа «Произвольная выборка», «Группировка» и т.д. В этом случае кнопка «Вложенные запросы» открывает диалоговое окно «Доступные шаги сценария» с данными «входящей» таблицы (рисунок ниже). Двойной щелчок мыши по названиям её полей или самой таблицы добавляет фрагмент кода (с именем поля / таблицы соответственно) в запрос.

4.5 - Шаблоны базовых операций с данными
Данная группа предназначена для настройки источников и приемников данных, сбора статистики, а также очистки таблиц и переноса данных в базе.
Источник
Шаблон «Источник» — основа для работы. Он позволяет указать таблицу базы, из которой будут браться исходные данные для сценария. Если начать редактирование «Источника», то откроется диалоговое окно «Выбор таблиц для сценариев».

По умолчанию информация отражается в виде таблиц и схем (режим «Таблица»). В нижней части окна приведен список всех доступных таблиц и схем, к которым относятся эти таблицы. Для быстрого поиска нужной таблицы по её названию можно ввести текст в окне «Поиск (Ctrl + F)». По мере ввода каждого символа, в нижней части будут отфильтровываться совпадения названий таблиц.
Двойным щелчком мыши по строке можно завершить выбор таблицы для «Источника». Над иконкой шага появится имя выбранной таблицы.
Предусмотрен и другой режим поиска — «Составы выгрузки». Для активации режима следует нажать одноименную кнопку. В нижней секции будут сведения о составе выгрузок, именах таблиц, правил выгрузки, даты изменения, создания и режима записи.
Расширенный поиск помогает искать таблицу, когда в списке много таблиц с похожими названиями. Можно искать совпадение символов в начале строки, по части строки и по точному совпадению, причем не только в имени таблицы, но и схеме (выпадающий список «Где искать:»).

Кнопка «Обновить конфигурацию» позволяет обновить в диалоговом окне данные, которые появились недавно. На рабочем холсте WorkFlow сценария может быть более одного источника, если требуется объединять данные из разных таблиц.
Приёмник
Когда произведены все загрузки, очистки, трансформации, обогащения данных и т.д., после шаблона с последними операциями добавляют «финальный» шаг с «Приёмником». С помощью шаблона надо всего лишь задать имя набора данных, созданного после всех расчётов и преобразований. Имя впечатывается в строку ввода «Приемник данных» диалогового окна «Мастер настройки приемника данных». В дальнейшем, это имя следует использовать в Аналитическом портале при создании набора данных.

В верхнем правом углу Мастера есть кнопки для вспомогательных функций: можно сохранить файл (в формате «*.txt»), распечать таблицу на принтер, посмотреть содержимое, получить ссылку на финальную таблицу.
В нижней части окна Мастера отражается код SQL (удаление таблицы приемника, повторное её создание на базе предыдущего шага).
Можно установить галочку в селекторе «Является источником». Тогда появится возможность использовать приёмник дальше в сценарии, т.е. протянуть из него стрелку для следующего шага, и такой приёмник не будет «финальным».
Просмотр
Шаблон «Просмотр» сам по себе не влияет на результат работы сценария. Однако, это удобный и полезный инструмент. Он описывает данные, полученные на предыдущем шаге. Из списка полей предыдущего шага («Поля» в левой нижней части окна) методом drag-and-drop необходимо переместить анализируемые поля в секцию «Статистика» (в правой нижней части окна). По каждому полю еще можно указать (вводом с клавиатуры) лимит количества значений (ограничение выборки в столбце «Лимит кол-во значений (TOP N)»).

Выбор вкладки «Качество данных» (правее вкладки «Статистика») открывает доступ к следующим функциям:
-
соответствие значений поля какому-либо условию;
-
поиск дублей значений.
Аналогично секции «Статистика», поля для изучения перемещаются в секцию «Качество данных» (кнопка «Добавить» создает пустую строку, кнопка «Копировать» — копирует существующую). Для каждого поля в колонке «Тип проверки» есть выпадающий список со значениями «Дубли» или «Условие».

Чтобы сформировать условие для конкретного поля, надо выделить строку с этим полем, затем в нижней правой подсекции нажать кнопку «Добавить условие» (в виде белого плюса в круге зеленого цвета). Рядом также есть кнопка удаления условия.
Для числовых полей можно использовать операторы сравнения («больше», «меньше», «больше или равно», «меньше или равно», «равно», «не равно» — «!=») либо вхождения в диапазон («IN»).

Для текстовых строк в условии может быть длина строки («LEN»), поиск по совпадению текста («LIKE»), вхождение в диапазон текстовых значений («IN»). Также возможен поиск по варианту, когда в тексте только цифры («Только цифры [0-9]»).

В столбце «Значение» (правее колонки «Условие») следует ввести те значения, с которыми производится сравнение.
В каждой строке настройки условия можно включить селектор «NOT» (первый столбец): он задает, что условие не соблюдается (логическое «НЕ»).
Для типа проверки «Дубли» не предусмотрено условий сравнения.

В показателях статистики можно посмотреть, сколько всего строк по полю, сколько из них пустых или NULL, уникальных, минимальная, средняя и максимальные длина текстового поля либо минимум, максимум и среднее для чисел.
На вкладке «Образец данных» можно посмотреть образцы значений, а на вкладке «Статистика» для каждого значения каждого поля можно узнать, сколько раз оно встречается. Шаблон «Просмотр» не может принимать данные от шага «Источник». Нужны какие-то обработки данных на предыдущем шаге.
Очистка таблицы
Шаблон «Очистка таблицы» производит очистку таблицы из базы данных, которую надо указать в поле «Приемник данных». В итоге, шаг генерирует код SQL TRUNCATE TABLE с указанием имени таблицы.

Связь с другими шагами сценария нужна, чтобы указать, в какой момент (после чего и перед чем) сделать операцию очистки.
Перенос данных
Шаблон шага «Перенос данных» предназначен для переноса данных между двумя различными базами внутри одного сценария. Например, перенос данных в базу данных витрин ClickHouse из базы данных ядра на базе PostgreSQL.
Для работы шага обязательно должен быть установлен агент выполнения сценария («Информация» / «Основные настройки» / «Агент для выполнения сценариев»).
На закладке «Источник и приемник» указываются база данных и имя таблицы источника, а также база данных и таблица модели приемника. Также указывается режим записи данных в таблицу приемника. По гиперссылке «Настроить таблицу» открывается форма настройки таблицы модели приемника.

На следующем шаге (закладка «Связь полей»). требуется установить связи между полями таблицы-источника и таблицы-приемника. Для этого над именем поля таблицы-источника (в левой секции окна) нужно нажать левую кнопку мыши, и, не отпуская её, сдвинуть указатель мышь в имя поля таблицы-приёмника (в правой секции окна).

В итоге, связанные поля будут выделены жирным шрифтом. В левой части отражается информация о входящем потоке, а в правой устанавливается соответствие и режим записи данных.
Если в таблицах имена полей схожи, и у них совпадает тип, можно ускорить процесс связывания с помощью кнопки «Автосопоставление». Рядом есть кнопка «Очистить все сопоставления», которая удаляет связи.
Перенос данных логируется документом «Перенос данных» («Логи» / «Переносы данных»).
4.6 - Шаг переноса данных в другую БД
Шаблон шага «Перенос данных» находится в группе шагов «Данные» и предназначен для переноса данных между двумя различными базами внутри одного сценария. Например, перенос данных в базу данных витрин ClickHouse из базы данных ядра на основе PostgreSQL.
Для работы шага обязательно должен быть установлен агент выполнения сценария («Информация» / «Основные настройки» / «Агент для выполнения сценариев»).
Настройка мастера
- На закладке «Источник и приемник» указываются база данных и имя таблицы источника, а также база данных и таблица модели приемника. Также указывается режим записи данных в таблицу приемника. По гиперссылке «Настроить таблицу» открывается форма настройки таблицы модели приемника.
- На закладке «Связь полей» в левой части отражается информация о входящем потоке, а в правой устанавливается соответствие и режим записи данных. Доступны команды автосопоставления и очистки всех сопоставлений.
Перенос данных логируется документом «Перенос данных» («Логи» / «Переносы данных»).
4.7 - Использование параметров выполнения шага
Настройки работы ADO для конкретного шага
Каждому шагу сценария обработки данных можно указать параметры работы ADO, которые будут учитываться при выполнении шага. Для этого нужно дважды кликнуть на нужный шаг — откроется окно с параметрами шага (см. рисунок ниже, 1). Далее перейти на вкладку «Настройки работы ADO» (см. рисунок ниже, 2):

Создать новый элемент и заполнить параметры:
- «Шаг сценария», должен заполнится автоматически (см. рисунок ниже, 1);
- «Вид настройки» («Опции выполнения метода execute» или «Таймаут выполнения команды») (см. рисунок ниже, 2);
- Параметры, зависящие от вида настройки (см. рисунок ниже, 3);
Далее, следует записать и закрыть элемент (см. рисунок ниже, 4). Теперь при выполнении шага будут учитываться заданные параметры ADO:

Настройки работы ADO для категорий шагов
Для применения параметров работы ADO для определенных (отобранных) шагов, можно воспользоваться «Правилами применения настроек ADO». Для этого необходимо перейти в меню «Главное» / «Настройки» / «Правила применения настроек ADO»:

Создать новый элемент и заполнить параметры «Наименование» (см. рисунок ниже, 1) и «Отбор» (см. рисунок ниже, 2) — для определения нужных шагов и записать (см. рисунок ниже, 3) изменения. Далее перейти на вкладку «Настройки работы ADO» (см. рисунок ниже, 4):

На вкладке «Настройки работы ADO» создать новый элемент и заполнить параметры:
- «Правило», должен заполнится автоматически (см. рисунок ниже, 1);
- «Вид настройки» («Опции выполнения метода execute» или «Таймаут выполнения команды») (см. рисунок ниже, 2);
- параметры, зависящие от вида настройки (см. рисунок ниже, 3).
Далее, следует записать и закрыть элемент (см. рисунок ниже, 4). Теперь, к шагам, соответствующим отбору, при их выполнении будут применятся заданные настройки работы ADO.

4.8 - Шаги сценария (старый интерфейс)
Для настройки каждого шага на вкладке «Шаги сценария (старый интерфейс)» предусмотрены управляющие элементы:

Рабочая область вкладки поделена на две основные части: дерево сценария и настройки выбранного шага. Функциональность управляющих элементов позволяет добавить / удалить шаги, добавить/удалить группы шагов, включатьотключать отображение служебных и удаленных шагов, а также изменять порядок следования шагов или групп в дереве сценария.
При добавлении шагов сценария следует заполнить поля:
| Поле | Назначение поля | Правила заполнения и работы |
|---|---|---|
| Кнопка «Включить / Выключить» | Выключить шаг, т.е. пропускать шаг при авто-выполнении сценария | Для выключения шага необходимо нажать на кнопку «Выключить» |
| Вид шага | Выбор вида скрипта | Выбрать из: «SQL-запрос» / «1C-запрос» / «Произвольный код на языке 1С» |
| Тип шага | Выбор типа шага | Выбрать из трех значений: «EXEC» — исполняемый, «SEL» — выборка данных, «Вложенный запрос» — результаты шага будут доступны в последующих шагах сценария |
| Запускать 1 раз | Признак, что шаг допустимо выполнять только один раз | Если допускается только однократное выполнение шага, то установить флаг и тогда при ошибке выполнения скрипта система не будет делать несколько попыток выполнить шаг (количество попыток устанавливается в системных настройках) |
| Текст запроса | Текст запроса | Заполнить текст запроса на языке SQL или 1C |
| Имя таблицы | Текстовое поле, отражающее название таблицы, в которую вносятся изменения на этом шаге сценария | Заполняется вручную, используется для графического изображения процесса обработки данных. Графическое изображение можно включить в пакете обработки (подробно см. в этом разделе |
| Комментарий | Описание для шага | Заполнить описание шага |
Настройка сценария, используя шаблоны шагов сценария
Для облегчения настройки шагов возможно воспользоваться готовыми преднастроенных шаблонов (мастеров). Текст скрипта на языке SQL / 1С сформируется автоматически на основании выбранных пользователем настроек.
Для использования шаблонов нужно при создании нового шага сценария, выбрать шаблон из списка «Шаблоны шагов сценария»:

После формирования текста запроса и сохранения параметров шага, в дереве сценария шаги созданные при помощи шаблонов выделяются иконкой (см. рисунок выше).
Для того, чтобы изменить параметры в мастере шага сценария,необходимо перейти по ссылке с наименованием шаблона «Группировка».
Для удаления шаблона шага необходимо нажать правой кнопкой на наименование выбранного шаблона «Очистить шаблон шага».
После удаления появляется возможность выбрать шаблон «Задать шаблон».
Результирующий текст запроса шага сценария обработки данных получится после ввода всех необходимых для шаблона настроек при помощи мастера настроек, как будет описано ниже. Чтобы сохранить шаг введите его наименование и нажмите кнопку «Записать»:

Просмотр текста скрипта для шаблона шага доступен в справочнике «Шаблоны шагов сценария» на вкладке «Текст запроса»:

Настройка параметров шаблонов шага при помощи мастера
Для каждого шаблона шагов сценария существует свой набор параметров, необходимых для формирования скрипта на языке SQL. Для заполнения этих параметров нужно вызвать мастер настройки.
Для создания шага с помощью шаблона необходимо нажать кнопку «Задать шаблон».
После выбора необходимого шаблона открывается мастер, например, «Произвольная выборка данных»:

Далее на примере «Произвольной выборки данных» будут описаны особенности интерфейса и управляющие элементы, характерные для других шаблонов (мастеров).
При использовании шаблона «Произвольная выборка данных» необходимо:
- выбрать таблицу, из которой нужно получить данные;
- настроить связи между таблицами, в случае если запрос необходимо сформировать к нескольким таблицам;
- настроить необходимые поля целевой выборки данных;
- настроить отбор данных, в случае если необходимо отфильтровать какие-либо строки целевой выборки.
Описанные этапы настройки представлены на рисунках ниже.



При настройке есть возможность указать псевдонимы для выбираемых полей, поменять порядок полей в итоговой выборке.
Форма настройки полей также позволяет настроить произвольное выражение, форма доступна при нажатии на кнопку «fx» . Это позволяет применить, например, строковые, календарные, числовые и другие функции:

Настройка связей между таблицами состоит из шести шагов.
- Для установки связи между таблицами нужно перенести одну таблицу на другую (см. рисунок ниже, 1), переход к детальной настройке связи осуществляется двойным кликом.
- выбор типа соединения (см. рисунок ниже, 2).
Доступные варианты: левое; правое; внутреннее; внешнее (полное). - выбор поля первой таблицы (см. рисунок ниже, 3);
- выбор оператора соединения (см. рисунок ниже, 4).
Доступные варианты операторов: «=» — равно; «<>» — не равно; «<» — меньше; «<=» — меньше или равно; «>» — больше; «>=» — больше или равно. - выбор поля второй таблицы (см. рисунок ниже, 5):

Настройка отбора данных состоит из трёх шагов:
- выбор поля таблицы, к которому применяется отбор (см. рисунок ниже, 1);
- выбор вида сравнения (см. рисунок ниже, 2). Например, «Равно», «Больше или равно», «В списке», «Заполнено» и т.п.;
- ввод значения для применения отбора данных (см. рисунок ниже, 3);

Для возможности использования логики «ИЛИ», а также формирования других логических конструкций необходимо воспользоваться кнопкой «Сгруппировать условия» (см. рисунок ниже).
Пример: «значение поля больше или равно, или значение поля не заполнено»:

В результате шаг сценария будет содержать SQL-запрос по указанным настройкам мастера:

Группировка шагов сценария
Шаги сценария можно объединять в логические группы.
Первый вариант использования групп позволяет включить механизм безопасного обновления данных. Принцип безопасного обновления данных заключается в том, что все изменения внутри происходят не с исходной таблицей, а с ее копией:
- если все шаги группы завершены успешно, то таблица-копия превращается в основную таблицу, а исходная таблица сохраняется для истории изменений;
- если во время работы шагов в группе произошел сбой, и работа по трансформации данных не может быть завершена, процесс прекращается, однако, состояние исходной таблицы остается таким каком оно было до начала процесса, так как все шаги трансформации производились над таблицей-копией.
Второй вариант использования групп — это объединение нескольких шагов в группу каждый последующий шаг использует предыдущий в качестве подзапроса. Т.е. если на первом шаге мы делаем выборку из какой-то таблицы, то на следующем шаге мы работаем уже с результатом этой выборки как с самостоятельной таблицей.
Настройка группировки шагов
Для создания группы в дереве сценария необходимо нажать на кнопку «Группа». Для добавления нового шага в группу необходимо установить курсор в дереве сценария на группу и добавить шаг, нажав на кнопку «Шаг»:

Для добавления существующего шага в группу необходимо выбрать шаг и в поле «Шаг родитель» указать группу, в которую необходимо перенести выбранный шаг:

Настройка безопасного обновления данных
Для создания группы шагов в режиме безопасного обновления данных необходимо создать группу и выбрать тип группировки «Безопасное обновление данных таблицы».
В этом режиме в группе создаются служебные шаги:

Выберите таблицу в списке «Имя таблицы». Для этой таблицы включится механизм безопасного обновления. Нажмите кнопку «Записать»:

Добавляя шаги обработки данных в такую группу, служебные шаги создания временной таблицы и смены имен таблиц останутся на своих предзаданных позициях:

В служебном шаге «Создание временной таблицы» формируется таблица-копия с аналогичной структурой исходной таблицы. Наименование таблицы-копии формируется по маске «Имя таблицы_TMP_yyyyMMddHHmmssfff».
Далее все манипуляции с данными необходимо производить в таблице-копии. Например, используя шаблон «Мэппинг полей 2х таблиц» генерируется SQL-запрос, в котором операция вставки данных производится в таблицу-копию. Мастер шаблона определяет, что шаг сценария расположен в группе с типом «Безопасное обновление данных таблицы» и подменяет наименование таблицы-приемника на системную переменную «{!Контекст_ИмяВременнойТаблицы!}».
Если все шаги группы выполняются без ошибок, то служебный шаг «Смена имен таблиц» обменивает наименования исходной таблицы и таблицы-копии, завершая тем самым процесс безопасного обновления данных.
Настройка шагов сценария как подзапросов
Для возможности использовать результаты выполнения шага в других шагах сценария необходимо указать тип шага «Вложенный запрос».
Ниже приведен пример настройки шага сценария.
Создаем первый шаг сценария шаблоном «Произвольная выборка данных», указывая что результат будет доступен в других шагах сценария:

В результате формируется шаг сценария с типом «Вложенный запрос».
Создаем второй шаг сценария с видом шага «SQL» и типом «SEL». В блоке «Текст запроса» указываем запрос, например, select from и далее перейдя по ссылке «Вложенные» необходимо выбрать ранее созданный шаг:

В результате текст запроса в шаге дополнится строкой вида
«select from ({!системный идентификатор!}) AS Step_1»
Запуск сценария
Существуют три варианта запуска шагов сценария
- запускать каждый шаг или группу шагов по кнопке «Выполнить шаг» в дереве сценария;
- запустить выполнение всех шагов сценария по кнопке на вкладке «Основное»;
- запустить выполнение всех шагов сценария в интерфейсе WorkFlow по кнопке «Запустить» — как было описано выше.
При запуске на выполнение всех шагов сценария открывается интерфейс, в котором показывается ход выполнения шагов сценария:

После завершения работы сценария — открывается «Лог выполнения сценария»:

4.9 - Дополнительные возможности
Сценарий обработки данных. Работа с шаблоном расчета фасетов таблицы
Мастер настройки расчета фасетов таблицы используется при проведении анализа данных с помощью отчета «Фасеты»:
Подробнее о работе отчета см. раздел Просмотр результатов расчета фасетов таблицы.
Настройка расчета фасетов таблицы
Для расчета фасетов таблицы необходимо создать специальный сценарий. В сценарии создать новый шаг и выбрать из шаблонов мастер настройки расчета фасетов (см. рисунок ниже, 1, 2, 3):
Для настройки расчета фасетов таблиц необходимо
- выбрать базу данных (см. рисунок ниже, 1);
- выбрать название модели (см. рисунок ниже, 2), в случае если расчет необходимо провести для таблицы, которая находится в составе какой-либо модели данных;
- выбрать таблицу (см. рисунок ниже, 3), поставить галку «Таблицы из конфигурации базы данных» (см. рисунок ниже, 4) в случае если расчет необходимо провести для таблицы, которая не находится в составе какой-либо модели данных;
- нажать кнопку «Далее» для перехода не следующий этап настройки.
На закладке «Настройка полей» (см. рисунок ниже) необходимо:
- проставить галку выбора поля (см. рисунок ниже, 1);
- ввести значение «Количество строк в фасете» = «-1» (см. рисунок ниже, 2), в случае если расчет фасетов по выбранному полю не требуется;
- ввести значение «Количество строк в фасете» = «100» (см. рисунок ниже, 3), в случае если требуется частичный расчет фасетов по выбранному полю.
Примечание: при частичном расчете фасетов значения по рассчитываемому атрибуту таблицы сохраняются с применением ограничения заданного в поле «Количество строк в фасете». Например, расчет полного фасета по полям уникальных идентификаторов является избыточным ввиду необходимости сохранить полный список уникальных значений. При расчете фасетов по таким полям необходимо ограничивать расчет значением минимально достаточным для анализа.
После завершения настройки необходимо нажать кнопку «Готово». Текст шага сценария сгенерируется и будет готов для запуска.
Для запуска расчета фасетов необходимо выделить и запустить созданный шаг сценария. Либо если требуется запустить весь созданный сценарий. А также при необходимости можно добавить созданный сценарий в пакет обработки данных и поставить на расписание.
Просмотр результатов расчета фасетов таблицы
Для просмотра результатов расчета фасетов таблицы необходимо открыть отчет «Фасеты», расположенный на начальной странице в разделе «Отчеты»:
Для запуска отчета «Фасеты» необходимо
- выбрать базу данных (см. рисунок ниже, 1);
- выбрать название модели (см. рисунок ниже, 2), в случае если расчет необходимо провести для таблицы, которая находится в составе какой-либо модели данных, либо выбрать модель «m1_По умолчанию»;
- выбрать таблицу (см. рисунок ниже, 3);
В блоке списка полей таблицы необходимо выбрать поля, по которым требуется провести анализ и нажать кнопку «Сформировать». После формирования отчета в блоке значений отобразятся списки значений по выбранным полям:
В блоке вывода значений есть возможность открыть подробную информацию по метрикам фасета, для этого необходимо нажать на ссылку с наименованием поля (см. рисунок выше, 1).
Подробная информация отображается в дополнительном окне:
Окно с подробной информацией можно также открыть при двойном нажатии на наименование поля в блоке выбора полей таблицы:
5 - Пакеты обработки данных
Пакет обработки данных предназначен для настройки автоматического запуска заданий по обновлению данных.
В состав пакета могут входить следующие шаги:
- составы выгрузок данных;
- сценарии обработки данных;
- другие пакеты обработки данных.
Перейти к списку пакетов можно через начальную страницу или через меню «Главное» / «Настройки» / «Пакеты обработки данных».

В открывшемся окне появится список доступных пользователю пакетов. Пакеты могут быть сгруппированы в папки.
5.1 - Настройка пакетов обработки данных
Для настройки пакета обработки данных в документе необходимо заполнить «Наименование», «Группу» (может остаться пустой) и «Проект» (если используется).
Выбор режима выполнения
При настройке пакета пользователь может выбрать два режима выполнения: последовательно или параллельно. При выборе режима «Последовательно» все шаги пакета будут выполняться друг за другом. В случае выбора режима «Параллельно» настройка выполнения шагов будет выполняться в отдельной форме «Состав пакета».
Последовательное выполнение
Для добавления шага необходимо нажать кнопку «Добавить» и выбрать тип шага из списка:
- «Составы выгрузок»;
- «Сценарий»;
- «Пакеты обработки данных» (шагом может являться другой пакет получения данных).
После выбрать в качестве шага элемент из соответствующего списка.
Шаг пакета можно исключить из выполнения. Для этого нужно снять флаг в колонке «Включить».
Параллельное выполнение
При параллельном выполнении пакета, шаги пакета выполняются по заданным правила очередности. Настройка состава пакета происходит в интерфейсе WorkFlow. Для настройки параллельного выполнения необходимо:
- в пакете выбрать «Режим выполнения: Параллельно»;
- перейти на вкладку «Состав пакета»;
- откроется интерфейс WorkFlow, где необходимо произвести настройку шагов.
Порядок работы в интерфейсе WorkFlow состава пакета аналогичен порядку работы с интерфейсом WorkFlow в сценарии:
- на поле «WorkFlow» переносится нужный тип шага сценария;
- с помощью кнопки «Редактировать шаг» на шаблоне открывается форма выбора элемента сценария, в соответствии с выбранным типом;
- шаги соединяются между собой связью портов;
- запуск до конкретного шага осуществляется через кнопку «Выполнить до этого шага».

Настройка параметров
При необходимости можно заполнить параметры, которые будут действовать для всех шагов пакета. А если настроить параметры для нескольких запусков, то пакет будет выполняться столько раз, сколько пакетов параметров настроено.

Вывод схемы выполнения пакета
Визуальная схема — позволяет увидеть, как взаимодействуют разные шаги получения и обработки данных, не изучая исходные документы и тексты скриптов. Пример графического представления состава пакета представлен ниже.
Открыть схему можно из списка пакетов, нажав на кнопку. Схема строится на основе указания названия баз данных и таблиц в документах («Состав выгрузки», «Сценарий»).

5.2 - Включение пакета в расписание
Для настройки автоматического запуска пакета:
- для активации расписания регламентного задания установить флаг «Активно» на форме редактирования пакета;
- настроить расписание запуска регламентного задания по сбору данных, нажав на ссылку «Расписание не задано».
Просмотреть настроенное расписание можно через меню «Главное» / «Сервис» / «Планировщик запуска пакетов». В расписании по дням и часам визуально представлены запланированные к запуску пакеты. Длительность и цвет пакетов в расписании отображены исходя из настроек.
5.3 - Настройка рассылки оповещений о выполнении пакета
После выполнения пакета обработки данных, программа может прислать оповещение на электронную почту.
Чтобы программа могла отправлять оповещения, нужно настроить учетную запись электронной почты (см. статью «Настройка почты»).
Для настройки списка рассылки нужно перейти в «Главное» / «Настройки» / «Списки рассылок».

Далее нажать кнопку «Создать»:

Далее заполнить «Наименование» (см. рисунок ниже, 1), «Адрес электронной почты» (см. рисунок ниже, 2). Если необходимо рассылать оповещения на несколько адресов, можно добавить поля на кнопку «Добавить» (см. рисунок ниже, 3). Записать и закрыть форму:

После создания списка, его можно выбрать в «Пакете обработки данных» в подменю «Контроль работы», поле «Получатели рассылки».

5.4 - Лог выполнения пакетов обработки данных
Для отслеживания процесса получения и обработки данных можно воспользоваться журналом выполнения пакетов. Доступ к журналу через меню «Главная» / «Логи» / «Выполнение пакета»:
В журнале пакетов можно просмотреть записи о выполненных и выполняющихся пакетах. Цветом указано состояние пакета и был ли он выполнен успешно:
- зеленый — завершен и выполнен успешно;
- синий — в процессе работы;
- красный — выполнен с ошибками.
Каждый лог о выполнении можно открыть и просмотреть подробные данные о каждом шаге.
Документ «Выполнение пакета» отображает следующую информацию о начале, окончании и длительности выполнения пакета, наименование пакета, а также информацию о состоянии выполнении пакета.
В табличной части выводится «Шаг пакета», признаки «Шаг начат» и «Шаг выполнен», ссылка на документ лога выполнения шага (при нажатии на ячейку будет открыт документ лога с подробностями шагов выполнения состава выгрузки, сценария постобработки или пакета), информация о работе шага, список ошибок во время работы пакета.
6 - Модуль НСИ
1. Модуль НСИ
Модуль учета нормативно-справочной информации (сокращенно «НСИ») предназначен для хранения и использования объектов НСИ — справочников и маппингов («маппинг» — это соответствие элементов первичных данных элементам справочников). Объекты НСИ хранятся в универсальной структуре — в базе данных хранилища и используются для стандартизации, категоризации, очистки и обогащения первичных данных.
Ограничение: в настоящее время модуль НСИ возможно использовать только для хранилища на СУБД PostgreSQL.
Основные шаги использования НСИ при обработке данных:
- создать справочники первичных данных и эталонных данных;
- настроить маппинг полей первичных и эталонных справочников;
- использовать представления справочников и маппингов в сценариях обработки данных.
1.1. Настройка и подключение
Для возможности работы с модулем НСИ необходимо выполнить следующие действия:
- Установить соответствующий флаг в «Основных настройках»:

- Подключить модуль к базе данных, в которой будут храниться заведенные справочники в виде универсальной структуры. Для этого сначала необходимо создать структуру для модуля, а затем подключить хранилище к модулю.
Для подключения модуля к базе данных, надо перейти в раздел меню: «Размещение данных» / «Базы данных» (быстрый доступ с начальной страницы нажать на ссылку базы данных) и выбрать базу, в которой планируется развернуть структуру модуля. Затем перейти на вкладу «Функциональность» выбранной базы данных и нажать кнопку «Создать» / «Проверить таблицы справочников» (см. рисунок ниже). В результате пользователь увидит сообщение о создании структуры в хранилище и рядом с кнопкой автоматически будет установлен флаг «Таблицы НСИ созданы».
Затем необходимо нажать кнопку «Установить подключение к таблицам НСИ».
Результат настройки модуль НСИ подключен к выбранному хранилищу и готов к использованию.
Далее, в разделе «НСИ» / «Подключение» следует выбрать указанную базу.

1.2. Создание справочников
В модуле используются два вида справочников:
- справочники первичных данных;
- эталонные справочники (те данные, которые будут использоваться для стандартизации, категоризации и обогащения исходных данных).
При создании справочника добавляются обязательные поля-реквизиты – «Код» и «Наименование». Для эталонных справочников возможно добавить дополнительные поля-реквизиты.
1.2.1. Создание справочников первичных данных
Чтобы создать справочник первичных данных надо перейти в раздел «НСИ» / «Настройка первичных справочников» и нажать на кнопку «Создать»:

При создании надо заполнить следующие поля:
- «Наименование» — наименование справочника;
- «Алиас» — короткое наименование справочника, которое будет использоваться в дальнейшем при создании представлений справочников.

В таблице «Вид справочников» указаны маппинги для выбранного справочника первичных данных. Подробнее см. раздел 1.4.
1.2.2. Создание эталонных справочников
Для создания эталонного справочника надо перейти в раздел «НСИ» / «Настройка справочников» и нажать на кнопку «Создать»:

При создании и редактировании справочника надо заполнить следующие поля:
- «Имя справочника» — наименование справочника;
- «Алиас» — короткое наименование справочника, котрое будет использоваться в дальнейшем при создании представлений справочников;
- «Видимость кода» — включить, если при выгрузке в Excel нужно получить значение поля «Код» (является обязательным полем каждого справочника) каждой строки справочника;
- «Уникальность наименования» — включить для проверки поля «Наименование» (является обязательным полем каждого справочника). При включенном признаке для каждой строки справочника будет проводиться проверка поля «Наименование» без учета регистра.

Поля справочника отображаются в соответствующей таблице. Для добавления справочнику полей необходимо нажать на кнопку «Создать» (см. рисунок выше) и указать следующее:
- «Наименование реквизита» — наименование поля справочника;
- «Тип реквизита» — тип поля справочника. Возможно выбрать следующий тип из списка:
- строка;
- число;
- дата;
- ссылка на другой справочник. Возможно настроить, чтобы значения для поля справочника выбирались из другого эталонного справочника. Поэтому при выборе ссылочного типа в «Типе ссылки» необходимо указать справочник, на который он будет ссылаться.
- «Видимость реквизита» — для отображения поля справочника в интерфейсе «Заполнения справочника»;
- «Использовать реквизит в отборе» — используется для создания фильтра по реквизиту в разделе «Заполнения справочника»;

Порядок вывода реквизита — отображает порядок вывода данного реквизита в разделе заполнения справочника и недоступно для редактирования в форме «Редактирование реквизита справочника». Изменить порядок вывода можно, воспользовавшись кнопками в разделе «Настройка справочника».
1.3. Заполнение справочников
Заполнение первичных справочников осуществляется в разделе «Заполнение первичных справочников», заполнение эталонных справочников — в разделе «Заполнение справочников». Интерфейс работы со справочниками очень похож.
При переходе на раздел «Заполнение первичных справочников» или «Заполнение справочников» откроется список соответствующих справочников первичных данных или эталонов. Переход на заполнение конкретного справочника осуществляется двойным нажатием мышки по выбранному справочнику.

Заполнение или редактирование справочников возможно как через интерфейс в соответствующем разделе, так и с использованием файлов MS Excel.
1.3.1. Заполнение справочников через интерфейс
На ринсунке ниже отображен интерфейс работы с элементами эталонного справочника.
Добавить строку в справочник возможно по кнопке «Создать». При двойном клике мышки на выбранную строку справочника откроется форма редактирования этой строки.
Удалить строку возможно по правой кнопке мыши.

Если поле-реквизит справочника является ссылкой на другой справочник, то значение этого поля выбирается из списка значений справочника, на который ссылается поле-реквизит.
1.3.2. Заполнение справочников с использованием файлов Excel
Иногда, например, в случае большого количества строк в справочнике, удобно загрузить данные справочника с использованием файла MS Excel.
В этом случае предполагается следующий сценарий работы:
- выгрузить шаблон справочника;
- заполнить данными шаблон, сохранить файл;
- загрузить файл.
1.3.2.1. Выгрузка файла шаблона справочника
Шаблон справочника представляет собой «XLSX»-файл, размеченный особенным образом:

Формирование шаблона осуществляется по ссылке «Экспорт в шаблон».
При экспорте шаблона возможно указать количество строк, для которых будет сделана разметка файла по строкам. Возможно добавить и большее количество строк, чем указано в шаблоне.
1.3.2.2. Загрузка файла справочника
Импорт элементов справочника из xlsx-файла осуществляется по кнопке «Загрузить элементы справочника».
При импорте осуществляются следующие проверки:
- на корректность заполннения поля «Наименование» (если при создании справочника установлен флаг «Уникальность наименования» см. пп. 1.2.2.Создание эталонных справочников;
- в случае использования кодов записей, осуществляется проверка на заполнение поля «Код»;
- на корректность заполнения ссылочных полей.
В случае ошибок при импорте справочных данных из «XLSX»-файла в директории с исходным файлом создается файл с ошибками, а пользователю выводится соответствующее сообщение.
1.3.2.3. Выгрузка справочника в файл Excel
Все элементы справочника возможно выгрузить в «XLSX»-файл. Выгрузка осуществляется по ссылке «Выгрузить элементы справочника». Возможно отредактировать выгруженный файл и загрузить его обратно.
1.3.3. Заполнение справочников с использованием сценария WorkFlow
Предусмотренна возможность заполнения первичного справочника через шаблон сценария WorkFlow.
Источник данных сценария должен соответствовать базе НСИ.
Настройка происходит следующим образом:
- выбирается шаблон «НСИ. Загрузка в первичный справочник»;
- в поле настройки выбирается источник первичных данных для справочника;
- в следующей вкладке сопоставляются поля таблицы источника и первичного справочника;
- нажать «Провести и закрыть»;
- запустить.

По окончанию выполнения операции в первичный справочник попадут уникальные значения полей, выбранных на этапе сопоставления.
1.4. Настройка маппинга
Сценарий работы при создании нового маппинга описан ниже.
- Создать маппинг в разделе «Настройка первичных справочников» для выбранного справочника первичных данных. Текущие маппинги выбранного справочника отображаются в таблице «Вид справочника (маппинг)». По кнопке «Создать» возможно добавить новый маппнг для выбранного справочника:

При создании необходимо указать эталонный справочник, с которым будут установлены связи.
- Настроить связи между справочниками первичных данных и эталонных осуществляется в разделе «Маппинг элементов».
Внешний вид интерфейса представлен на рисунке ниже:

На форме в левой части результат настройки маппинга между элементами справочника первичных данных и эталонными справочниками. В правой части представлены маппинги для первичного справочника. Отображение маппинга зависит от выбранных эталонных справочников. Если не указывать флаг у эталонного справочника, его маппинг не будет отображаться в левой части формы.
В средней таблице представлены значения выбранного эталонного справочника. Установка связей осуществляется несколькими способами:
- можно использовать кнопку сопоставления, которая на основании разработанного алгоритма производит сопоставление полей (точность до 95% для строковых полей);
- перетаскиванием мышкой элемента эталонного справочника на левую таблицу (первичного справочника);
- с помощью «XLSX»-файла:
- кнопкой «Экспорт в шаблон» получится выгрузить файл шаблона маппинга;
- кнопка «Выгрузить маппинг» позволяет выгрузить маппинг в таком виде, в каком он представлен в левой таблице на форме;
- кнопка «Загрузить маппинг» позволяет загрузить маппинг из «XLSX»-файла.
Очистка выбранных строк маппинга в левой таблице осуществляется по правой кнопке мыши.
1.5. Использование справочников или маппингов при обработке данных
Применение настроенных маппингов и справочников осуществляется в сценарии по средствам использования шаблонов НСИ.
Шаблоны НСИ в WorkFlow:
- «НСИ.Дополнение из маппинга» — используется для обогащения первичных данных значениями эталонного справочника по средствам преднастроенного маппинга.
Настройка шаблона:
- вкладка «Сопоставление»:
- в поле «Источник данных» выбирается таблица источник с первичными данными;
- в поле «Маппинг НСИ» выбирается настроенный маппинг;
- в поле «Связи» настраивается связь таблиц по ключу.

- «Поля выборки»: в правую часть шаблона помещаются все необходимые поля из источника первичных данных, а из маппинга эталонное значение справочника.

В «Результате» получается таблица первичных данных обогащенная значениями из эталонного справочника.
-
«НСИ.Дополнение из эталонного справочника» — позволяет добавить дополнительные поля из эталонного справочника после маппинга первичных и эталонных значений.
Настройка аналогична шаблону «НСИ.Дополнение из маппинга». -
«НСИ.Обновление из эталонного справочника» — позволяет обновить записи источника первичных данных на записи эталонного справочника по ключу.
Настройка аналогична шаблону «НСИ.Дополнение из маппинга». -
«Маппинг НСИ» — может использоваться как источник, содержит справочники с маппингами.
-
«Справочник НСИ» — может использоваться как источник, содержит перечень эталонных справочников.
7 - Дополнительные возможности
1. Экспорт данных из таблицы SQL
Доступ к этой возможности есть через начальную страницу или через меню: «Главное» / «Сервис» / «Экспорт данных из таблицы SQL»:
Заполнение настроек:
- варианты выбора показаны как находящиеся рядом кнопки, выбранный вариант отмечен зеленым цветом названия кнопки (пример на рисунке выше, 1.1 и 1.2, активным является вариант 1.2):
- вариант 1.1 используется для выгрузки в формате «UTF-8»;
- вариант 1.2 используется для выгрузки в формате «UTF-16» или, если не важно какой, «Unicode»;
- база SQL на сервере (выбирается из справочника «Базы данных») — см. рисунок выше, 2;
- имя таблицы из базы SQL на сервере (см. рисунок выше, 3);
- если нужно выгрузить данные в формате «UTF-8» без BOM-маркера, установить соответствующий флаг в положение «Истина» (см. рисунок выше, 4);
- выбрать разделитель полей (варианты «Табуляция» и «;» см. рисунок выше, 5). При выборе варианта нужно убедиться, что в исходных данных в таблице нет таких символов, как «;», а при их наличии заменить на другой символ, например, «,»;
- выберите формат выходного файла («XLSX», «CSV»; см. рисунок выше, 6.1 и 6.2), при выборе нужно иметь ввиду ограничение количества строк в Excel, при большом объеме выгрузки предпочтителен формат «CSV»;
- выберите путь к файлу и его название:
- если тип выгрузки установлен 1.1, то нужно выбирать размещение файла на сервере размещения 1С;
- если тип выгрузки установлен 1.2, то нужно выбирать размещение файла на сервере размещения базы-источника SQL.
Установите нужные настройки и нажмите кнопку «Экспортировать данные».
Экспорт данных не логируется.
2. Экспорт данных для многомерного анализа в виде OLAP-куба
В качестве сервера для многомерного анализа используется отдельное партнерское решение для многомерного анализа — «Полиматика».
2.1. Настройка и подключение
Для включения возможности интеграции с «Полиматикой» необходимо установить нужную настройку в основный настройках:
Получить доступ к формированию куба для многомерного анализа можно через основной интерфейс по пути «Главное» / «Сервис» / «Интеграция с «Полиматикой»:
Т.к. «Полиматика» является самостоятельным решением, отделенным от ModusETL, расположенным на отдельном ресурсе. Для подключения к «Полиматике» необходимо установить адрес сервера, ввести логин и пароль для доступа и нажать кнопку «Войти»:
После успешного подключения к «Полиматике» можно формировать кубы и просматривать настройки ранее созданных кубов.
2.2. Просмотр существующих кубов
Для просмотра ранее созданных кубов нужно перейти на соответствующую вкладку (см. рисунок ниже). В списке можно увидеть названия (см. рисунок ниже, 1) и основные настройки кубов. При установке курсора на нужный куб можно увидеть текст запроса на языке SQL, который использовался для формирования выбранного куба (см. рисунок ниже, 2).
Т.к. данные для куба выгружаются в отдельное приложение, при изменении данных в хранилище требуется обновлять данные в «Полиматике». Для этого можно запустить обновление для выбранного куба (см. рисунок ниже, 4) или обновить все кубы сразу (см. рисунок ниже, 3). Также для обновления кубов можно настроить расписание.
Собственно, многомерный анализ и просмотр результатов анализа производится в «Полиматике».
2.3. Настройка куба для многомерного анализа
Для настройки нового куба нужно перейти на соответствующую вкладку (см. рисунок ниже). Нужно ввести название куба (см. рисунок ниже, 1), выбрать базу-источник, из таблиц которой будет формироваться куб (см. рисунок ниже, 2). Далее можно ввести запрос на языке SQL для получения данных из базы-источника вручную. Поле для ввода запроса см. рисунок ниже, 3. Также существует возможность использовать мастер запросов, который автоматически сформирует запрос в соответствии с указанными настройками. Вызов мастера запросов производится по кнопке «Открыть конструктор запроса» (см. рисунок ниже, 4). После того как запрос сформирован (вручную или при помощи мастера) можно запустить получение данных для проверки запроса на наличие ошибок и для визуального контроля полученных данных. Запуск проверки производится по кнопке «Выполнить запрос» (см. рисунок ниже, 5).
2.3.1. Настройка запроса при помощи мастера
При вызове мастера настройки откроется окно. В этом окне нужно выбрать таблицу из списка таблиц базы данных-источника и нажать кнопку «Далее»:
На следующем шаге настройки мастер переходит на закладку настройки полей запроса. В левой части формы (см. рисунок ниже, 1) список исходных полей таблицы. В правой части формы (см. рисунок ниже, 2) выбранные для запроса поля.
Включение полей в запрос возможно при помощи кнопок «>», «»» или двойным щелчком на нужном поле в левой части формы. Исключение полей из запроса возможно с помощью кнопок «<», ««».
Одно поле может быть включено в запрос несколько раз. Для выходного поля в запросе используются псевдонимы (alias), по умолчанию псевдоним совпадает с названием исходного поля, но может быть изменен пользователем. Псевдонимы не могут повторяться в одном запросе.
В качестве выходного поля в запросе может быть использовано выражение с участием полей исходной таблицы, арифметических и логических операторов и функций.
Для включения в качестве поля вычисляемого выражения, нужно нажать двойным щелчком мыши на знак «fx» в нужном поле. Откроется окно конструктора выражений:
В конструкторе выражений могут быть использованы поля исходных таблиц, числа, арифметические и логические операции, а также встроенные функции. Внешний вид конструктора выражений показан на рисунке ниже. В левом верхнем поле расположен список полей источника (см. рисунок ниже, 1). Встроенные операторы и функции расположены в левом нижнем углу формы (см. рисунок ниже, 3). Описание встроенных функций можно прочитать в правом нижнем поле формы (см. рисунок ниже, 4), для этого нужно нажать на название функции. Собственно, выражение формируется в правом верхнем поле формы (см. рисунок ниже, 2):
Чтобы сохранить выражение, нажмите кнопку «ОК» в правом нижнем углу формы.
Также в запрос могут быть включены несколько таблиц и подзапросы.
Для включения новой таблицы нажмите кнопку «Добавить» и выберите таблицу из списка.
Связи между таблицами можно установить на вкладке «Связи таблиц». На этой вкладке автоматически заполняются все таблицы, включенные в запрос. Чтобы указать что две таблицы связаны. Перетащите мышкой одну таблиц на строку другой, как показано на рисунке:
На строке с таблицей появится знак соединения таблиц. Можно установить тип соединения. Варианты соединения:
- левое;
- правое;
- внутреннее;
- внешнее.
Для выбора типа соединения щелкните по знаку соединения. Откроется форма настройки соединения:
Для настройки соединения нужно выбрать тип и выбрать поля соединяемых таблиц, по которым будет выполняться соединение. Наборов полей может быть несколько. Для добавления набора полей нажмите кнопку «Добавить», выберите поле из списка полей первой таблицы и поле из списка полей второй таблицы:
В запросе для формирования куба можно настроить фильтры.
Перейдите на закладку «Настройки отбора данных», добавьте нужные поля для отбора, выберите функцию проверки и значение, с которым будут сравниваться данные поля.
Результат работы запроса может быть проверен на каждом этапе его создания. Для этого нужно нажать кнопку «Проверить запрос». В области «Данные результирующего запроса» будут показаны возвращаемые им данные:
2.3.2. Настройка параметров куба из запроса
Для автозаполнения размерностей будущего куба нажмите кнопку «Выполнить запрос». Все поля настроенного запроса заполнятся в область «Размерности». Поля в область фактов можно переместить при помощи кнопки «Стрелка вправо»:
Можно изменить наименования размерностей и фактов в кубе.
Поля размерностей можно добавлять вручную. Нажмите кнопку «Добавить» и впишите название поля в строку.
2.3.3. Сохранение настроек куба в ETL
Т.к. «Полиматика» является отдельным продуктом, функции формирования куба и сохранения настроек для куба в базе программного продукта разделены. Для сохранения текущих настроек запроса и полей куба нажмите кнопку «Сохранить параметры»:
2.3.4. Формирование куба
Для формирования куба по сделанным настройкам нажмите кнопку «Создать куб» (см. рисунок выше).
2.4. Настройка расписания автообновления данных для кубов
Для автообновления данных для кубов нужно создать специальный сценарий. Нужно создать новый сценарий, шаг сценария выбрать из шаблонов:
В открывшемся окне нужно ввести адрес сервера «Полиматики», логин и пароль.
Для настройки запуска сценария по расписанию его нужно включить в пакет. Настройка расписания для пакета описана в [этом разделе](../9. Пакеты обработки данных/index.md#).
3. Механизм замены символа «’» (апостроф) на «`»
В текстовых исходных данных иногда встречаются специальные символы, которые невозможно записать в SQL-таблицу. Для устранения этого создана функция замены таких символов. Замена выполняется во всех полях и строках полученных таблиц. Включение этой функции может выполняться автоматически или устанавливаться в ручном режиме.
Автоматический режим создан для уменьшения нагрузки на сервер. Замена, при работе очереди, работает не всегда. Номер попытки при сборе данных, с которой включается механизм замены, указывается в основных настройках:
При ручном сборе с помощью обработки «Выгрузка в отчет» механизм замены включается вручную — флаг «Заменить спец. символы».
4. Версионирование
Предназначено для хранения исторических данных. Версионирование настраивается для каждой таблицы отдельно. Версионирование организовано как хранение актуальных и исторических (неактуальных) данных в одной таблице с пометкой «Актуальные» / «Не актуальные». При новом получении данных осуществляется поиск таких данных по ключевым полям. Если данные не найдены, запись добавляется с признаком «Актуальная». Если данные найдены, то производится сравнение неключевых полей, выбранных для сравнения. При их отличии старая запись помечается, как «Не актуальная», и добавляется новая запись с признаком «Актуальная».
Для настройки версионирования таблицы базы данных необходимо выполнить последовательно ряд шагов.
Включить отметку о доступности версионирования у базы данных, на вкладке «Функциональность»:
Открыть пункт меню «Конфигурации» / «Конфигурации БД» / «1С». В открывшейся форме найти нужную базу данных и нажать кнопку «Показать структуру метаданных».
В структуре метаданных найти таблицу, для которой нужно настроить версионирование:
Двойным кликом по наименованию таблицы открыть форму настройки таблицы. Нажать на кнопку «Настроить версионирование», чтобы открыть форму настройки версионирования.
В списке полей нужно отметить те поля, значения которых позволяют однозначно идентифицировать строку таблицы базы данных, это будет уникальный «Ключ».
А также нужно выбрать несколько полей, не являющихся ключом, по значениям которых будет осуществляться проверка изменения строк таблицы базы данных, это будет «Хэш».
Затем нажать кнопку «Включить версионирование».
Если все настроено правильно, то появится сообщение:

Настраивать поля «Ключа» и «Хэша» можно только при отключенном версионировании.
При просмотре структуры базы данных, таблицы с включенным версионированием отображаются специальной пиктограммой:

В документе «Установить правила выгрузки» для таблиц выведен признак включенности версионирования и добавлены колонки «Ключ», «Хэш».

При настройке «Пакета» также добавлен вывод имени таблицы и признака ведения версий для шагов типа «Состав выгрузки».

8 - Новое в версии
Версия ETL 1.6.9.11
03.05.2024
Внимание! Минимальная версия платформы для работы релиза 8.3.18.1957.
Загрузка файлов
- Исправлены ошибки выгрузки из файлов csv.
Версия ETL 1.6.9.9
16.04.2024
Внимание! Минимальная версия платформы для работы релиза 8.3.18.1957.
Мастер интеграции
- Исправлена ошибка видимости справочника «Пользователи».
Версия ETL 1.6.9.8
03.04.2024
Внимание! Минимальная версия платформы для работы релиза 8.3.18.1957.
Рекомендуемая версия сервера СЛК 3.0.34.
Рекомендуемая версия Агента ETL: 1.33.3.
Рекомендуемая версия Адаптера ETL: 1.1.11.2.
Мастер интеграции
Мастер интеграций — новый инструмент для создания и настройки сборов данных без программирования. Позволяет создать набор правил, составов выгрузки и пакетов для сбора данных из различных веб сервисов в хранилище данных В текущем релизе выпущена версия загрузки данных из CRM Битрикс24 в части сделок. Решение позволит без программиста загружать информацию о сделках и их статусах, продажах и лидах, товарах и услугах, которые ведутся в Битрикс24.
Общая инструкция по использованию мастера приведена здесь.
Инструкция по настройке Битрикс24 приведена здесь.
Запуск и произвольный код на стороне 1С:Предприятия
Для сложной обработки данных в системе 1С:Предприятие, например, для выполнения сложных расчетов и методов на стороне базы-источника в Адаптере ETL реализована возможность запуска подключаемых внешних обработок через адаптер. В состав поставки включена внешняя обработка, которая позволяет выполнять произвольный код на стороне источника и передавать подготовленную исполняемым кодом структуру данных.
Инструкция по использованию внешних обработок и по запуску кода на стороне приемника приведена здесь.
Прочие улучшения
- При проверке подключения к информационной базе 1С через адаптер, проверка выполняется как напрямую ETL - АдаптерETL, так и через используемого Агента ETL.
- Добавлены шаблоны «Маппинг 2х таблиц с предварительным удалением» и «Перенос данных». Подробная инструкция на шаги сценария приведена здесь.
- Подсистема НСИ. Ускорена загрузка записей в первичный справочник.
- Пакеты данных. При запуске пакетов выполняется контроль наличия цикличных ссылок, при выставлении соответствующей настройки.
- Доработан механизм заполнения списка полей по настройкам схемы СКД.
Исправление ошибок
- Исправлена ошибка загрузки метаданных в случае, если выполняется подключение к базе данных под пользователем, у которого нет прав на некоторые схемы.
- Доработан механизм заполнения списка полей по настройкам схемы СКД.
- Доработана Консоль запросов в части получения данных из баз 1С: настроено корректное отображение наименований Объектов БД при их переносе из списка «Объекты БД» в область «Текст запроса».
- Исправлены прочие ошибки.
Версия ETL 1.6.8.10
29.12.2023
Внимание! Минимальная версия платформы для работы релиза 8.3.18.1957. Рекомендуемая версия сервера СЛК 3.0.34.
Сбор данных
- Доработан механизм контроля работающих заданий.
- Доработан механизм приоретизации параметров в пакетах.
- Доработаны механизмы регламентного получения данных из нескольких «JSON»-файлов.
- «Режим выгрузки» в «Составе выгрузки» теперь обязательный параметр.
- Исправлена ошибка в «Выгрузке в отчет» при использовании Агента ETL.
- Исправлена ошибка создания группы составов выгрузки.
- Исправлены ошибки механизма сбора данных с помощью СКД.
WorkFlow
- В сценарии обработки данных ETL добавлен новый шаблон шага «Разделение строки», который позволяет разделить строковое значения по указанному разделителю на несколько строк.
- Исправлена ошибка шага сценария «Произвольный код», которая в некоторых случаях не позволяла посмотреть результат работы шага.
НСИ
- Переработаны места, которые в исключительных случаях приводили к аварийному завершению работы на Linux.
Пресеты
- Актуализированы правила переноса данных.
Управление хранилищем
- Добавлена возможность создания наборов данных в Modus BI на основании таблиц модели данных Modus ETL.
- Добавлено отключение функциональной опции «Управление хранилищем».
- Исправлен выбор схемы при создании таблицы в «Настройка таблицы выгрузки».
Прочее
- Выполнены доработки пользовательского интерфейса таблиц модели в части улучшения удобства их использования.
- Доработаны механизмы для удаления шагов сценариев.
- Обновлена версия компоненты СЛК.
- При разворачивании новой базы больше не создаются тестовые «Сценарии», «Правила выгрузок».
- Установлен режим совместимости 8.3.18.
- При создании подключения к базе данных автоматически создается пустая конфигурация этой базы данных.
- Исправлена ошибка, не позволяющая редактировать шаги сценария.
- Исправлены мелкие ошибки.
Версиия ETL 1.6.7.6
25.09.2023
Внимание! Минимальная версия платформы для работы релиза 8.3.17.1851. Рекомендуемая версия 8.3.18.1208.
Параллельное выполнение пакетов
Добавлена возможность настраивать выполнение пакетов, сценариев и составов выгрузки в виде графа в режиме WorkFlow. Теперь можно настраивать параллельный сбор, обработку и трансформацию данных. Это позволит сократить время обработки информации, например, когда сбор первичных данных может выполняться параллельно, но их обработка должна начаться только тогда, когда все данные соберутся.
Для переключения режима редактирования установите в пакете режим выполнения «Параллельно». При включении параллельного режима появится гиперссылка «Состав пакета», в которой можно настроить порядок выполнения шагов в режиме WorkFlow.

Сценарии обработки данных
Перенос данных в другую базу из WorkFlow
Теперь в сценарии обработки можно добавить шаг переноса данных в другую базу данных. Для это добавлен шаг «Перенос данных». Перенос данных позволяет быстро перенести данные в нужную базу без создания правил и составов выгрузок. Мастер может использоваться для переноса данных из DW слоя в слой отчетности. Например, перенести подготовленные данные из ядра хранилища из PostgreSQL в таблицу ClickHouse.

Саму же таблицу ClickHouse тоже можно сконфигурировать в мастере настройки таблицы, установив порядок сортировки и первичные ключи.

Для включения функциональности работы с таблицей в основных настройках необходимо в разделе «Управление хранилищем» установить функциональную опцию «Использовать управление хранилищем».
Теперь сценарий можно скопировать вместе с его шагами.
Реализована поддержка соединения и выбора одинаковых таблиц в шагах мастера.
Конструктор запросов
В правилах выгрузки и в мастере сбора данных добавлена консоль запросов для тестирования и отладки при написании SQL или 1С запроса.

Исправление ошибок
Исправлены найденные ошибки.
Версия 1.6.6.14
27.07.2023
Внимание! Минимальная версия платформы для работы релиза 8.3.17.1851. Рекомендуемая версия 8.3.18.1208.
Мастера сбора данных
- Добавлена возможность выбора ClickHouse в мастере сбора данных.
- Доработан мастер получения данных. Появилась возможность указать проект и папку для правил выгрузки, состава выгрузки.
- Исправлена работа мастеров при изменении типов связи между шагами.
- Исправлено определение типов в мастере создании таблицы БД.
WorkFlow
- Доработан шаблон «НСИ.Загрузка в первичный справочник».
- Реализован функционал сохранения обученных моделей ML.
- Исправлены ошибки шаблонов при изменении типа связи между шагами.
- Исправлена работа шаблона шага «Соединение».
Адаптер ETL
- Добавлена поддержка работы со сжатием при сборе данных из информационных баз 1С с использованием АдаптераETL.
НСИ
Для включения функциональности НСИ необходимо перейти в «Информация» / «Основные настройки» / «НСИ» / «Использовать НСИ».
- Добавлена возможность в маппинге справочников отображать дополнительные реквизиты.
- Добавлена возможность автоматического сопоставления первичного справочника с эталонным на этапе маппинга.
- Добавлен мастер загрузки данных из таблиц СУБД в первичный справочник.
- Исправлены ошибки при добавлении реквизитов с одинаковыми наименованиями в первичный справочник.
Получение данных
- В установке правил выгрузки данных добавлена консоль запросов для отладки. (находится: «Еще» / «Консоль запросов»).
- Добавлено автоматическое создание источника и набора данных при установки признака «используется для получения данных».
Управление хранилищем данных
Функционал выпущен в тестовом варианте. Для его включения необходимо перейти в «Информация» / «Основные настройки» /«Использовать трансформацию таблиц».
Внимание! Кнопка «Установить модель в хранилище» и «Удалить модель из хранилища» в форме «Модели данных» полностью удаляет таблицы из хранилища!
- Добавлена функциональность тонкой настройки для Сlickhouse. В установке правил выгрузке и в мастере сбора данных появилась возможность указать порядок сортировки таблицы и указать первичные ключи.
- Добавлен функционал проектирования модели данных, позволяющий описать связи в существующих таблиц.
- Добавлено обновление моделей данных при создании и обновлении конфигурации БД.
Прочее
- Добавлена возможность выбирать базу данных ClickHouse в «Отчете по данным в БД».
- Добавлен отчет «Выполнение пакета по дням», позволяющий отслеживать динамику времени выполнения шагов пакета за произвольный период.
- Доработаны механизмы пресетов в части переноса сценариев.
- Добавлена функциональность работы с произвольными дополнительными параметрами, которые могут быть использованы при подключении к базам данных.
- Обновлен БСП до версии 3.1.7.382.
- Добавлен раздел «Информация» на начальной странице ETL.
Исправлены ошибки
- Исправлены ошибки возникающие при работе сервера 1С на Linux.
- Исправлена ошибка загрузки из Excel.
- Исправлена ошибка создания базы данных типа «Файл».
- Переработаны зависимости визуального отображения от включенной функциональности.
- Исправлены мелкие ошибки.
Версия 1.6.5.18
25.04.2023
Внимание! Минимальная версия платформы для работы релиза 8.3.17.1851.
WorkFlow
- Добавлены новые шаги сценариев для ClickHouse:
- «Произвольная выборка»;
- «Объединение»;
- «Группировка»;
- «Соединение»;
- «Отбор»;
- «Создание таблицы».
- Добавлен универсальный шаг — «Перемещение файлов» с или на FTP сервер.
- Добавлена возможность передачи потока данных результата шага «Произвольный запрос SQL» в другие шаги сценария.
- В шаг произвольной выборки добавлена возможность выбирать различные данные.
- В шаг сценария с произвольной выборкой, группировкой и отбором добавлена возможность добавлять отбор в виде произвольного кода.
- Добавлена возможность копировать шаги сценария.
- Добавлена возможность описать отбор в шаге TOP-N.
Получение данных
- В конструкторе правил разбора «JSON» появилась возможность использовать web-запрос в качестве источника правил выборки. Подробнее о конструкторе Конструктор правил разбора «JSON».
- Добавлены подсказки использования различных программных обработчиков состава выгрузки.
Адаптер ETL
- Исправлены ошибки работы по получению данных через СКД.
Администрирование
- Добавлен отчет по контролю выполнения всех пакетов обработки данных.
- Актуализирована работа механизма пресетов.
- Аналитику добавлена возможность добавлять и изменять пользовательские типы данных.
- Добавлен http-сервис для интеграции с zabbix’ом и получения различных контрольных метрик.
- Сделана единая форма списка для справочника базы данных.
- Добавлена функциональность остановки / прерывания сбора данных. Добавлен отбор фактов выгрузки по различным состояниям («Выполняется» / «Завершен» / «Остановлен»).
НСИ
- Исправлены ошибки, связанные с НСИ. Реализована работа под ОС Linux.
- Доработаны алгоритмы создания/изменения элементов НСИ, в части автоматического создания/изменения представлений СУБД связанных с этими объектами.
- Доработан профиль Аналитик для возможности использовать подсистему НСИ.
- Выделен отдельный профиль «Администратор НСИ». Только пользователи с этим профилем могут создавать новые элементы эталонных справочников.
- Добавлена возможность создания элементов Эталонных справочников из значений Первичных справочников.
Исправлены ошибки
- Исправлена ошибка, приводящая к невозможности загрузить данные из файла при слишком длинном имени файла.
- Исправлена динамическая загрузка файлов. В некоторых случаях загрузка выполнялась только из одного файла.
- Исправлена ошибка импорта «.XLSX»-файлов.
- Исправлена ошибка создания таблицы.
- Исправлена ошибка мастеров WF при просмотре данных шагов, если входящий поток имеет тип «Вложенный запрос».
- Исправлена работа шаблонов в установке правил выгрузки.
- Исправлена ошибка заполнения списка полей в установке правила выгрузки.
- Исправлена ошибка загрузки большого файла.
- Исправлены прочие найденные ошибки.
Версия 1.6.4.12
30.01.2023
Внимание! Минимальная версия платформы для работы релиза 8.3.17.1851.
Получение и обработка данных
- Выполнена доработка Мастера загрузки файла «XLSX» и «CSV», обеспечена совместимость с файлами, сохраненными в LibreOffice и других «альтернативных» приложениях, доработан интерфейс Мастера в части работы с незагружаемыми столбцами (исключен анализ ошибок в заголовках для тех столбцов, загрузка которых не требуется).
- Добавлена возможность работы Мастеров шагов трансформации данных с различными схемами хранилища DWH.
- В сценарии подготовки таблицы «Очистить и добавить» добавлена возможность использования
DELETEдля очистки, вместоTRUNCATE. - Добавлено событие для фиксации факта начала и завершения сбора данных из источника.
- Добавлена возможность загрузки списка пользователей в Modus BI.
- Доработан конструктор правил и алгоритм получения данных «JSON», для возможности загрузки отдельных ветвей JSON в колонку таблицы.
- Все режимы подготовки таблиц, которые используются при сборе данных, адаптированы для СУБД Vertica и Clickhouse.
- Добавлен http-сервис, позволяющий запускать «Состав выгрузки», «Сценарий», «Пакет обработки данных».
- Добавлена возможность создания групп(иерархии) в справочниках «Сценарии», «Составы выгрузок», «Пакеты».
- Добавлена возможность ограничивать количество потоков «сборщиков данных» для составов выгрузки. Это позволяет более гибко регулировать нагрузку на системы поставщики данных.
Администрирование
- Добавлен отчет для просмотра списка активных пакетов и ориентировочном времени их исполнения.
- Доработан отчет для контроля доступности баз данных.
- Добавлено версионирование шагов сценария.
Адаптер ETL
- Добавлена функциональность распознавания ссылок для ссылочных метаданных (справочники, документы и т.д.), которые добавлены через расширения.
Исправлены ошибки
- Исправлена ошибка мастера «Выгрузка таблицы в файл»: в некоторых случаях, при указании произвольного запроса возникала ошибка.
- Исправлена ошибка из-за которой не создавались новые поля в таблице при изменении её структуры из установки правла выгрузки.
- Исправлены найденные ошибки.
Версия 1.6.3.17
24.10.2022
Внимание! Минимальная версия платформы для работы релиза 8.3.17.1851.
Получение данных
- Добавлен механизм инкрементальной выгрузки для информационных баз на платформе 1С: Предприятие. Функциональность позволяет получать изменения, зарегистрированные на узлах обмена, автоматически очищать загруженные изменения, присваивать составам данных номера сообщений. Инкрементальная выгрузка значительно упрощает получение измененных данных из информационных баз и сокращает время получения данных.
- Ускорен механизм работы сценариев при делении потоков по параметрам.
Поддержка ClickHouse
- Добавлена возможность использовать в качестве хранилища (витрин данных) СУБД ClickHouse. Использование ClickHouse значительно сокращает время получения данных и позволяет строить витрины данных с большой скоростью доступа к ним.
WorkFlow
- Функциональность WorkFlow, в сценариях обработки данных, используется теперь по умолчанию.
- Исправлены ошибки работы некоторых мастеров.
Исправление ошибок
- Исправлены найденные ошибки.